□ Similarity Measure for Sparse Time Course Data Based on Gaussian Processes
>> https://www.biorxiv.org/content/10.1101/2021.03.03.433709v1.full.pdf
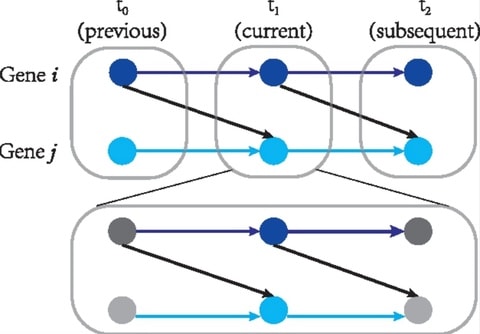
The Gaussian Processes similarity is similar to a Bayes factor and provides enhanced robustness to noise in sparse time series. The GP measure is equivalent to the Euclidean distance when the noise variance in the GP is negligible compared to the noise variance of the signal.
Fitting a GP model with N time courses of length t takes O(t3 + Nt2) time. Computing pairwise similarities takes O(tN2) time. high-dimensional short time courses (N ≫ t), the total time for GP similarity would be approximately O(tN2), which is the same as for the Euclidean distance.
Modeling the time courses as continuous functions using GPs, and define a similarity measure in the form of a log-likelihood ratio. The proposed GP similarity achieves substantially better results than the Bregman divergence and Dynamic Time Warping.

□ BIONIC: Biological Network Integration using Convolutions
>> https://www.biorxiv.org/content/10.1101/2021.03.15.435515v1.full.pdf
BIONIC (Biological Network Integration using Convolutions), learns features which contain substantially more functional information compared to existing approaches, linking genes that share diverse functional relationships, including co-complex and shared bioprocess annotation.
BIONIC uses the GCN neural network architecture to learn optimal gene interaction network features individually, and combines these features into a single, unified representation for each gene. BIONIC learns gene features based solely on their topological role in the given networks.

□ LEVIATHAN: efficient discovery of large structural variants by leveraging long-range information from Linked-Reads data
>> https://www.biorxiv.org/content/10.1101/2021.03.25.437002v1.full.pdf
LEVIATHAN (Linked-reads based structural variant caller with barcode indexing) takes as input a BAM file, which can either be generated by a Linked-Reads dedicated mapper such as Long Ranger, or by any other aligner.
LEVIATHAN allows to analyze non-model organisms on which other tools do not manage. For each iteration, LEVIATHAN only computes the number barcodes between region pairs for which the first region is comprised between the ((i − 1) ∗ R/N + 1)-th and the (i ∗ R/N )- th region.

□ minicore: Fast scRNA-seq clustering with various distance measures
>> https://www.biorxiv.org/content/10.1101/2021.03.24.436859v1.full.pdf
Minicore is a fast, generic library for constructing and clustering coresets on graphs, in metric spaces and under non-metric dissimilarity measures. It includes methods for constant-factor and bicriteria approximation solutions, as well as coreset sampling algorithms.
Minicore both stands for "mini" and "core", as it builds concise representations via core-sets, and as a portmanteau of Manticore and Minotaur.
Minicore’s novel vectorized weighted reservoir sampling al- gorithm allows it to find initial k-means++ centers for a 4-million cell dataset in 1.5 minutes using 20 threads.
Minicore can cluster using Euclidean distance, but also supports a wider class of measures like Jensen-Shannon Divergence, Kullback-Leibler Divergence, and the Bhattacharyya distance, which can be directly applied to count data and probability distributions.

□ BLight: Efficient exact associative structure for k-mers
>> https://academic.oup.com/bioinformatics/advance-article-abstract/doi/10.1093/bioinformatics/btab217/6209734
BLight, a static and exact data structure able to associate unique identifiers to k-mers and determine their membership in a set without false positive, that scales to huge k-mer sets with a low memory cost.
BLight can construct its index from any Spectrum-preserving string sets without duplicate. A possible continuation of this work would be a dynamic structure that follows the main idea of BLight, using multiple dynamic indexes partitioned by minimizers.
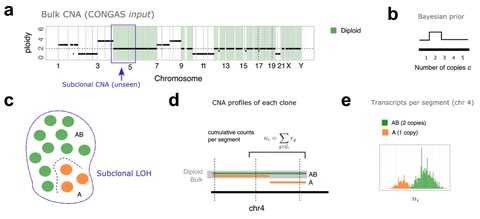
□ ARIC: Accurate and robust inference of cell type proportions from bulk gene expression or DNA methylation data
>> https://www.biorxiv.org/content/10.1101/2021.04.02.438149v1.full.pdf
ARIC adopts a novel two-step feature selection strategy to ensure an accurate and robust detection for rare cell types. ARIC introduces the componentwise condition number into eliminating collinearity step to pay equal attentions for the relative errors of all components.
ARIC employs a weighted υ-support vector regression (υ-SVR) to get component proportions. ARIC outperforms in the deconvolution of data from multiple sources. the absolute error term in υ-SVR can optimize the relative errors component-wisely, without ignoring rare cell types.
□ X-Entropy: A Parallelized Kernel Density Estimator with Automated Bandwidth Selection to Calculate Entropy
>> https://pubs.acs.org/doi/10.1021/acs.jcim.0c01375
The entropy is calculated by integrating the Probability Density Functions of the individual backbone dihedral angle distributions of the simulated protein. Calculating the classical coordinate-based dihedral entropy and use a 1D approximation of the entropy.
There are other approaches for calculating the dihedral entropy, e.g., quasiharmonic calculation, 2D Entropy, MIST, or the use of Gaussian Mixtures. These aim at calculating the total entropy of the entire system whereas the proposed approach calculates localized entropies of the individual residues.
The sum of these local entropies can be considered an approximation of the total entropy in the system, i.e., the approximation that neglects all higher order terms to the entropy.
X-Entropy calculates the entropy of a given distribution based on the distribution of dihedral angles. The dihedral entropy facilitates an alignment-independent measure of local. The key feature of X-Entropy is a Gaussian Kernel Density Estimation.

□ MuTrans: Dissecting Transition Cells from Single-Cell Transcriptome Data through Multiscale Stochastic Dynamics
>> https://www.biorxiv.org/content/10.1101/2021.03.07.434281v1.full.pdf
By iteratively unifying transition dynamics across multiple scales, MuTrans constructs the cell-fate dynamical manifold that depicts progression of cell-state transition, and distinguishes meta-stable and transition cells.
MuTrans quantifies the likelihood of all possible transition trajectories between cell states using the Langevin equation and coarse-grained transition path theory.
□ OmicLoupe: facilitating biological discovery by interactive exploration of multiple omic datasets and statistical comparisons
>> https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04043-5
OmicLoupe leverages additions to standard visualizations to allow for explorations of features and conditions across datasets beyond simple thresholds, giving insight which otherwise might be lost.
OmicLoupe is built as a collection of modules, each performing a certain part of the analysis. If multiple entries map to the same ID, for instance in the case of multiple transcripts mapping to one gene ID, OmicLoupe can still combine these datasets by using the first listed entry for each ID.

□ PEPPER-Margin-DeepVariant: Haplotype-aware variant calling enables high accuracy in nanopore long-reads using deep neural networks
>> https://www.biorxiv.org/content/10.1101/2021.03.04.433952v1.full.pdf
PEPPER-Margin-DeepVariant outperforms the short-read-based single nucleotide variant identification method at the whole genome-scale and produces high-quality single nucleotide variants in segmental duplications and low-mappability regions where short-read based genotyping fails.
PEPPER-Margin-DeepVariant achieves Q35+ nanopore-based and Q40+ PacBio-HiFi-polished assemblies with lower switch error rate compared to the unpolished assemblies.
As nanopore assembly methods like Shasta move toward generating fully resolved diploid genome assemblies like trio-hifiasm, PEPPER-Margin-DeepVariant can enable nanopore-only Q40+ polished diploid assemblies.
□ scCorr: A graph-based k-partitioning approach for single-cell gene-gene correlation analysis
>> https://www.biorxiv.org/content/10.1101/2021.03.04.433945v1.full.pdf
The scCorr algorithm generates a graph or topological structure of cells in scRNA-seq data, and partitions the graph into k multiple min-clusters employing the Louvain algorithm, with cells in each cluster being approximately homologous.
scCorr Visualizes the series of k-partition results to determine the number of clusters; averages the expression values, including zero values, for each gene within a cluster; and estimates gene-gene correlations within a partitioned cluster.

□ DTFLOW: Inference and Visualization of Single-cell Pseudotime Trajectory Using Diffusion Propagation
>> https://www.sciencedirect.com/science/article/pii/S1672022921000474
DTFLOW uses an innovative approach named Reverse Searching on kNN Graph (RSKG) to identify the underlying multi-branching processes of cellular differentiation.
DTFLOW infers the pseudo-time trajectories using single-cell data. DTFLOW uses a new manifold learning method, Bhattacharyya kernel feature decomposition (BKFD), for the visualization of underlying dataset structure.

□ simATAC: a single-cell ATAC-seq simulation framework
>> https://genomebiology.biomedcentral.com/articles/10.1186/s13059-021-02270-w
Given a real scATAC-seq feature matrix as input, simATAC estimates the statistical parameters of the mapped read distributions by cell type and generates a synthetic count array that captures the unique regulatory landscape of cells with similar biological characteristics.
simATAC estimates the model parameters based on the input bin-by-cell matrix, incl the non-zero cell proportion, the read count average of each bin, and generating a bin-by-cell matrix that resembles the original input data by sampling from Gaussian mixture and polynomial models.
□ CONSTANd: Constrained standardization of count data from massive parallel sequencing
>> https://www.biorxiv.org/content/10.1101/2021.03.04.433870v1.full.pdf
CONSTANd transforms the data matrix of abundances through an iterative, convergent process enforcing three constraints: (I) identical column sums; (II) each row sum is fixed (across matrices) and (III) identical to all other row sums.
CONSTANd can process large data sets with about 2 million count records in less than a second whilst removing unwanted systematic bias and thus quickly uncovering the underlying biological structure when combined with a PCA plot or hierarchical clustering.
□ sRNARFTarget: A fast machine-learning-based approach for transcriptome-wide sRNA Target Prediction
>> https://www.biorxiv.org/content/10.1101/2021.03.05.433963v1.full.pdf
sRNARF-Target, the first ML-based method that predicts the probability of interaction between an sRNA-mRNA pair. sRNARFTarget is generated using a random forest trained on the trinucleotide frequency difference of sRNA-mRNA pairs.
sRNARFTarget is 100 times faster than the best non-comparative genomics program available, IntaRNA, with better accuracy. Another advantage of sRNATarget is its simplicity of use, as sRNARFTarget does not require any parameter setting.
□ scAND: Network diffusion for scalable embedding of massive single-cell ATAC-seq data
>> https://www.biorxiv.org/content/10.1101/2021.03.05.434093v1.full.pdf
the near-binary single-cell ATAC-seq data as a bipartite network that reflects the accessible relationship between cells and accessible regions, and further adopted a simple and scalable network diffusion method to embed it.
scAND directly constructs an accessibility network. scAND performs network diffusion using the Katz index to overcome its extreme sparsity. an efficient eigen-decomposition reweighting strategy to obtain the PCA results w/o calculating the Katz index matrix directly.
□ glmSMA: A network regularized linear model to infer spatial expression pattern for single cells
>> https://www.biorxiv.org/content/10.1101/2021.03.07.434296v1.full.pdf
glmSMA, a computation algorithm that uses glmSMA to predict cell locations by integrating scRNA-seq data with a spatial-omics reference atlas.
Treating cell-mapping as a convex optimization problem by minimizing the differences between cellular-expression profiles and location-expression profiles with a L1 regularization and graph Laplacian based L2 regularization to ensure a sparse and smooth mapping.

□ Alexander Wittenberg
>> https://twitter.com/AW_NGS/status/1370294999980589058?s=20
Just obtained amazing results on Fusarium spp genome using R10.3 nanopore PromethION data, Bonito basecalling and Medaka consensus calling. Achieved chromosome-level assembly with QV52. That is 99.999% consensus accuracy! #RNGS21

□ omicsGAN: Multi-omics Data Integration by Generative Adversarial Network
>> https://www.biorxiv.org/content/10.1101/2021.03.13.435251v1.full.pdf
omicsGAN, a generative adversarial network (GAN) model to integrate two omics data and their interaction network. The model captures information from the interaction network as well as the two omics datasets and fuse them to generate synthetic data with better predictive signals.
The integrity of the interaction network plays a vital role in the generation of synthetic data with higher predictive quality. Using a random interac- tion network does not create a flow of information from one omics data to another as efficiently as the true network.
□ Alignment and Integration of Spatial Transcriptomics Data
>> https://www.biorxiv.org/content/10.1101/2021.03.16.435604v1.full.pdf
PASTE (Probabilistic Alignment of ST Experiments) aligns Spatial transcriptomics (ST) data across adjacent tissue slices leveraging both transcriptional similarity and spatial distances between spots.
Deriving an algorithm to solve the problem by alternating between solving Fused Gromov-Wasserstein Optimal Transport (FGW-OT) instances and solving a Non-negative Matrix Factorization (NMF) of a weighted expression matrix.
In the CENTER LAYER INTEGRATION PROBLEM - seek to find a center ST layer that minimizes the weighted sum of distances of input ST layers, where the distance b/n layers is calculate by the minimum value of the PAIRWISE LAYER ALIGNMENT PROBLEM objective across all mappings.

□ Buffering Updates Enables Efficient Dynamic de Bruijn Graphs
>> https://www.biorxiv.org/content/10.1101/2021.03.16.435535v1.full.pdf
BufBOSS is a compressed dynamic de Bruijn graph that removes the necessity of dynamic bit vectors by buffering data that should be added or removed from the graph.
BufBOSS can locate the interval of nodes at the ends of paths labeled with any pattern P in O(|P| log σ) time by starting from the interval of all nodes, and updating the interval |P| times. This algorithm locates any nodemer and to traverse edges in the graph forward / backward.

□ BubbleGun: Enumerating Bubbles and Superbubbles in Genome Graphs
>> https://www.biorxiv.org/content/10.1101/2021.03.23.436631v1.full.pdf
BubbleGun is considerably faster than vg especially in bigger graphs, where it reports all bubbles in less than 30 minutes on a human sample de Bruijn graph of around 2 million nodes.
BubbleGun detects and outputs runs of linearly connected superbubbles, which is called bubble chains. the algorithm iterates over all nodes s and determines whether there is another node t that satisfies the superbubble rules. BubbleGun can also compact linear stretches of nodes.

□ CAIMAN: Adjustment of spurious correlations in co-expression measurements from RNA-Sequencing data
>> https://www.biorxiv.org/content/10.1101/2021.03.25.436972v1.full.pdf
CAIMAN (Count Adjustment to Improve the Modeling of Association-based Networks.) utilizes a Gaussian mixture model to fit the distribution of gene expression and to adaptively select the threshold to define lowly expressed genes, which are prone to form false-positive associations.
The CAIMAN algorithm constructs an augmented group-specific ex- pression profile by concatenating the negative transformed expression values with the original log-transformed expression data.
CAIMAN calculates the probability of whether genes with low counts are actually expressed in the cell, instead of being artifacts caused by the non-specific alignment of reads or by technical variability introduced during data preprocessing.
CAIMAN initializes the means of the flanking components to be symmetrical to zero, and makes the absolute values of parameters identical for the positive flanking components and their negative counterpart during the maximization process.

□ scSO: Single-cell data clustering based on sparse optimization and low-rank matrix factorization
>> https://academic.oup.com/g3journal/advance-article/doi/10.1093/g3journal/jkab098/6205713
In the paper of SC3 method, Kiselev et al. pointed out that “The motivation for the gene filter is that ubiquitous and rare genes are most often not informative for clustering, and the gene filter significantly reduced the dimensionality of the data.”
scSO uses Sparse Non-negative Matrix Factorization (SNMF) and a Gaussian mixture model (GMM) to calculate cell-cell similarity, and unsupervised clustering based on sparse optimization.

□ scAMACE: Model-based approach to the joint analysis of single-cell data on chromatin accessibility, gene expression and methylation
>> https://www.biorxiv.org/content/10.1101/2021.03.29.437485v1.full.pdf
scAMACE provides statistical inference of cluster assignments and achieves better cell type seperation combining biological information across different types of genomic features.
Dividing the entries by (1 − entries) to map them into [0, ∞). And then normalize the entries by dividing the median of non-zero entries in each cell, and then take square of the entries to boost the signals.
□ AASRA: An Anchor Alignment-Based Small RNA Annotation Pipeline
>> https://academic.oup.com/biolreprod/advance-article-abstract/doi/10.1093/biolre/ioab062/6206296
AASRA represents an all-in-one sncRNA annotation pipeline, which allows for high-speed, simultaneous annotation of all known sncRNA species with the capability to distinguish mature from precursor miRNAs, and to identify novel sncRNA variants in the sncRNA-Seq sequencing reads.
AASRA can identify and allow for inclusion of sncRNA variants with small overhangs and/or internal insertions/deletions into the final counts. The anchor alignment algorithm can avoid multiple and ambiguous alignments, which are common in those straight matching algorithms.

□ HARVESTMAN: a framework for hierarchical feature learning and selection from whole genome sequencing data
>> https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04096-6
HARVESTMAN is a hierarchical feature selection approach for supervised model building from variant call data. By building a knowledge graph over genomic variants and solving an integer linear program , HARVESTMAN automatically finds the right encoding for genomic variants.
HARVESTMAN employs supervised hierarchical feature selection under a wrapper-based regime, as it solves an optimization problem over the knowledge graph designed to select a small and non-redundant subset of maximally informative features.

□ waddR: Fast identification of differential distributions in single-cell RNA-sequencing data
>> https://academic.oup.com/bioinformatics/advance-article/doi/10.1093/bioinformatics/btab226/6207964
The waddR provides an adaptation of the semi-parametric testing procedure based on the 2-Wasserstein distance which is specifically tailored to identify differential distributions in scRNA-seq data.
Decomposing the 2-Wasserstein distance into terms that capture the relative contribution of changes in mean, variance and shape to the overall difference. waddR is equivalent or outperforms the reference methods scDD and SigEMD.

□ ASHLEYS: automated quality control for single-cell Strand-seq data
>> https://academic.oup.com/bioinformatics/advance-article/doi/10.1093/bioinformatics/btab221/6207962
ASHLEYS’ main input is a set of BAM files, one per single-cell paired-end Strand-seq library aligned to a reference genome. ASHLEYS also evaluates library quality based on generic sequencing library features.
Other common library issues lead to W/C signal dropouts, which are modeled as the number of windows with non-zero W/C read coverage. The aggregated feature table for all libraries can then be used to train a new classifier to predict quality labels using ASHLEYS pretrained models.

□ ReFeaFi: Genome-wide prediction of regulatory elements driving transcription initiation
>> https://www.biorxiv.org/content/10.1101/2021.03.31.437992v1.full.pdf
ReFeaFi (Regulatory Feature Finder), a general genome-wide promoter and enhancer predictor, using the DNA sequence alone.
ReFeaFi uses a dynamic training set updating scheme to train the deep learning model, which allows us to have high recall while keeping the number of false positives low, improving the discrimination and generalization power of the model.
□ IPCARF: improving lncRNA-disease association prediction using incremental principal component analysis feature selection and a random forest classifier
>> https://bmcbioinformatics.biomedcentral.com/articles/10.1186/s12859-021-04104-9
IPCARF Using a combination of incremental principal component analysis (IPCA) and random forest (RF) algorithms and by integrating multiple similarity matrices.
IPCARF integrated disease semantic similarity, lncRNA functional similarity, and Gaussian interaction spectrum kernel similarity to obtain characteristic vectors of lncRNA-disease pairs.
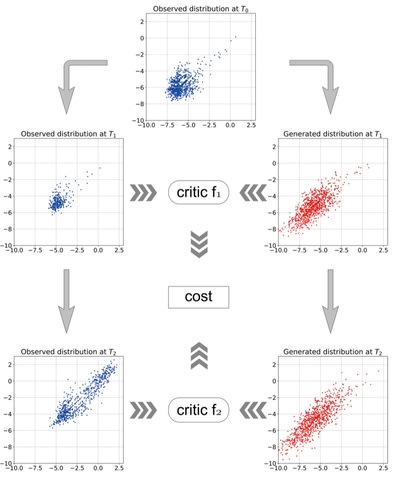
□ Non-parametric synergy modeling with Gaussian processes
>> https://www.biorxiv.org/content/10.1101/2021.04.02.438180v1.full.pdf
A Gaussian process is completely defined by its mean and kernel functions. Different kernels can be used to express different structures observed in the data.
Hand-GP, a new logarithmic squared exponential kernel for the Gaussian process which captures the logarithmic dependence of response on dose. Constructing the null reference model numerically using the Hand model by locally inverting the GP-fitted monotherapeutic data.

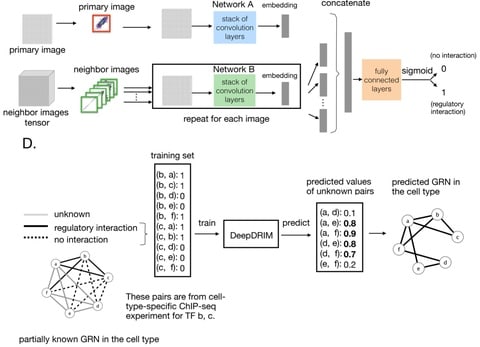
□ KBoost: a new method to infer gene regulatory networks from gene expression data
>> https://www.biorxiv.org/content/10.1101/2021.04.01.438059v1.full.pdf
KBoost uses KPCR and boosting coupled with Bayesian model averaging (BMA) to estimate the probabilities of genes regulating each other, and thereby reconstructs GRNs.
AUPR_AUROC_matrix=function(Net,G_mat, auto_remove,TFs, upper_limit){
# Reshape both matrices to facilitate the calculations
if (auto_remove){
g_mat = matrix(0,(dim(Net)[1]-1)*(dim(Net)[2]),1)
net = matrix(0,(dim(Net)[1]-1)*(dim(Net)[2]),1)
# A counter for indexing the matrices to copy
j_o = 1
j_f = dim(Net)[1]-1
for (j in seq_len(dim(Net)[2])){
g_mat[j_o:j_f,1] = G_mat[-TFs[j],j]
net[j_o:j_f,1] = Net[-TFs[j],j]
# update j_o and j_f.
j_o = j_o + (dim(Net)[1]-1)
j_f = j_f + (dim(Net)[1]-1
}
□ Cnngeno: A high-precision deep learning based strategy for the calling of structural variation genotype
>> https://www.sciencedirect.com/science/article/abs/pii/S1476927120314912
Cnngeno converts sequencing texts to their corresponding image datas and classifies the genotypes of the image datas. the convolutional bootstrapping algorithm is adopted, which greatly improves the anti-noisy label ability of the deep learning network on real data.
In comparison with current tools, including Pindel, LUMPY+SVTyper, Delly, CNVnator and GINDEL, Cnngeno achieves a peak precision and sensitivity of 100% respectively and a wider range of detection lengths on various coverage data.


































































































































































































 (Photo By William Eggleston; "Los Alamos")
(Photo By William Eggleston; "Los Alamos")


























 (Photo by William Eggleston; "Los Alamos")
(Photo by William Eggleston; "Los Alamos")