安易なリトポ
粗いメッシュにブーリアン系で形をとったメッシュは、シワが入りやすいものです。
そこでメッシュを細かく分割して表面を滑らかにしてやればマシになるのではないかと考えるのだけど、ブーリアン系の処理の結果、多角形なポリゴンになっててBlenderさんはメッシュ分割をしてくれません(Subdivideコマンドは三角・四角ポリゴンが対象)。
ということでアドオンでなんでも解決なBlender文化にいるのだから頼ってみようと購入してみました、BetaQuad。
Beta Quad [Blender Market]
まだまだ開発版というこちらのツールは現在日本円で1000円ちょっとで購入できます。

コマンド実行時のパラメータはこんな感じ。まあまあシンプルです。

上図一番左側のメッシュが渡ってきちゃって、このメッシュを書き出して読み込む先の読み込みの成功率を上げるために三角か四角ポリゴンにする(真ん中)よりも、BetaQuadで細分化してスムーズ処理をかけてやる(右側)とマシな結果になるのではないか、というのが今回の購入の趣旨です。

単純に三角ポリゴンにするよりはマシかなって方向にできるかもしれないという期待は持てそうな感触を得たので、満足です。
というか、普通にその他用途で多用するかもしれんなぁとちょっと思いました。
画像名を画像ファイルと同じにする
fbxなんかを読み込んだ時、画像の名前が画像ファイルとは全然違う個性を失ったものになっていることがあります。画像ファイル名が"face.png"なのにShader Editorに見えてくるイメージ名が"画像 #3”とかね。
なのでその画像名をファイル名と同じにするスクリプトをさっくりと。
import bpy
import os
for image in bpy.data.images:
filePath = image.filepath
imageName = os.path.splitext( os.path.basename(filePath) )[0]
if image.name != imageName:
image.name = imageName
シーン内の全画像を対象にしちゃうからOutinerのData API内で選択している画像のみを対象にしたいのだけど、どうやんだろ?
TexToolsでいいのではないか
 Blenderのベイクは標準機能だとベイク出力されるテクスチャはマテリアルごとに管理されるという使用者的にはどうしてそうなった?というフローが面倒くさいです。
Blenderのベイクは標準機能だとベイク出力されるテクスチャはマテリアルごとに管理されるという使用者的にはどうしてそうなった?というフローが面倒くさいです。
一つのオブジェクトに複数のマテリアルスロットがあると、それらスロットに接続されている全てのマテリアルにベイク出力するテクスチャの設定をしなければならないし、複数オブジェクトでマテリアルを共有していたら、そのマテリアル内に必要オブジェクト分だけImage Textureノードを作成して設定をしなければならない。大変に面倒だし、見通しが悪いのでImage Textureノードの選択ミスでベイクが失敗なんてことも起こりやすい。
そんなわけで何かいいツールはないかなってずっと思っているのだけど、古からのツールであるTexTools[GitHub]でいいんじゃね?ってことに初めて気づいたりしました。
いや、ベイクできることは知っていたのですけどね、要素別出力のためのものだと思っていたのですよ。(昔から必要だった作業的に)必要なのはBlender標準のベイク設定におけるCombinedなのです。で、TexToolsでは普通にそれも選択できたというわけで。Blenderのベイク設定をfrom CameraにしておくとTexToolsの方でも反映されるから、TexTools側にない設定はBlender側がの反映されるらしい。
ということでバッチ処理をさせる必要がなく単一のテクスチャを焼く程度ならこいつでいいのだろう。バッチするなら個人的にはBake Wranglerで行きたいと思います。
Blender 4.2でSoftimage XSIテーマを
Blender 4.2になり、従来標準でインストールされていたアドオンやテーマがバンドルされなくなりました。アドオンやテーマはエクステンションという形で配布され、それはBlenderのGUI内からダウンロード・インストールを行う模様。

デフォルトでは二つのテーマしか入ってなく、当然XSIテーマなんかなく、

それをエクステンションから入れましょうということになりました。
作業自体は簡単なのであまり問題はないでしょう。XSIのテーマ、メンテナンスが続くといいなぁ…

従来標準で入っててアクティブにはなっていなかったアドオンもエクステンションになって必要ならダウンロードしてねってことになったようだし、今後、サードパーティーの方が作成したアドオンやテーマ、キーマップ、アセットがここから配布されることになるようです(ライセンス的にここの配布基準を満たさないものは従来通りの配布の仕方になるようです)。
まあいいです。こんなエントリを書いたのは、Blender 4.2が入っていなかったMacBook Airで、ある操作を確認するために4.2のインストールを行ったら、そいえばXSIテーマにするのは従来よりちょっと面倒だったってことを思い出したからで、主目的はその操作です。
Blenderのオブジェクトの名前についてです。Blenderシーン内にオブジェクトを追加する際、それと同名のオブジェクトがあると、name.001, name.002, name.003...って感じでドットを分離記号とした連番の数字が入るじゃないですか。なんでドットなんだ?って馴染めないのです。blenderはそういう文化だから諦めるとして、それでも何か理由がない限り、分離記号はアンダースコアあたりにしておきたい、とします。
BlenderはデフォルトでEditメニュにBatch Renameコマンドを備えてます。Cubeオブジェクトを複製すると Cube.001, Cube.002, Cube.003...って名前のオブジェクトが増えていきます。つまりシーン内には
Cube, Cube.001, Cube.002, Cube.003
があることになります。これをまずは Cube.000, Cube.001, Cube.002, Cube.003 っていうふうにしたい時、TypeはSet NameでMethodをNewに、名前をCube.000としてあげれば良いようです。(Cube.000とリネームしようと試みて、同名のオブジェクトがすでにシーンにあるから Cube.001としてくれる。まあ"Cube"を"Cube.000"にするだけだから手動でやっても良いのだが…)

その上で、”.”を”_”に置き換えてあげると良さそうです。

うまくいったようです。とりあえずはこの方法で凌ぐかなぁ。
余談ながらBatch Renameでは複数ステップの処理を行うことが可能なため、Cube.000としてから”.”を”_”にするという処理を一気にするような設定が一見できそうです。

しかしオブジェクトごとに一連の処理を行うため、Cube_000, Cube_000.001, Cube_000.002, Cube_000.003 って名前に変更されちゃうのでした。選択オブジェクト全部に対して1ステップ目の処理をしてから2ステップ目の処理をするってやってくれればうまくいくはずだけど、そううまくはいきませんでした。
アルファチャンネルの形で切り抜く
樹木のオブジェクトがあったとして、その葉っぱは多くの場合、板ポリにアルファチャンネル付きのテクスチャで表現されていることが多いけど、それをリアルタイム系の描画エンジンに突っ込むと、そのエンジンによってはカメラから見た時の葉っぱたちの手前奥がわからなくなって描画が乱れちゃうよ、ってことが起こることがあります。
それを回避する簡単な方法として、アルファチャンネルを使わないようにするってのがありますね。つまり板ポリを葉っぱの形に切り抜くってことです。Image 2 Mesh [Blender Market] が使えるんじゃないか?って一瞬期待するけど、ちょっと目的が違うため、Geometry Nodesを利用してみました。

右の白黒テクスチャを利用して、黒いところを消したのが左の状態です。ノードは下のように組んでます。

ネット上で参考にさせてもらったサイトの組み方そのまんまですけどね。
ただこのやり方には一つ問題がありまして、ポリゴン数が膨大になってしまうってのがありまする。このやり方をするなら、その後ポリゴンリダクションの処理を行って完成といきたいところだけど、Geometry Nodesでサクッと組む方法を知らないため、Decimateモディファイヤをさらにかけてやるなんて力技で解決することになります。
なを、この方法を試した樹木オブジェクトの葉っぱで上記処理をした結果、葉っぱの先っぽに線ポリゴンが出来てしまうところがあったため、Geometry Nodesで Vertex Neighborsノードを使ってそんな連中を削除する処理を行いました。まあ、この程度なら割と簡単にできるから上記全体の作業工程としては許容範囲すかね。
BlenderのUnit Scaleを変更するアドオン
業務的にUnit Scaleは0.01にしたいし、フレームレートは59.94で行きたいし、Unit Scaleを変えたらビューのクリップの範囲も変更したいしで、でもそれをそれぞれの設定にアクセスして手動で変えるのは地味に面倒なのでChatGPT先生にアドオンを作ってもらいました。
bl_info = {
"name": "Setup for Viz Scene",
"version": (0, 1),
"blender": (4, 1, 0),
"category": "3D View",
}
import bpy
def set_unit_scale():
bpy.context.scene.unit_settings.scale_length = 0.01
def set_fps():
bpy.context.scene.render.fps = 60
bpy.context.scene.render.fps_base = 1.001
def set_clip_start_end():
for area in bpy.context.window.screen.areas:
if area.type == 'VIEW_3D':
for space in area.spaces:
if space.type == 'VIEW_3D':
space.clip_start = 1.0
space.clip_end = 30000.0
class VIZ_OT_set_unit_scale(bpy.types.Operator):
bl_idname = "view3d.set_unit_scale"
bl_label = "Set Unit Scale to 0.01"
bl_description = "Set Unit Scale to 0.01"
def execute(self, context):
set_unit_scale()
return {'FINISHED'}
class VIZ_OT_set_fps(bpy.types.Operator):
bl_idname = "view3d.set_fps"
bl_label = "Set FPS to 59.94"
bl_description = "Set FPS to 59.94"
def execute(self, context):
set_fps()
return {'FINISHED'}
class VIZ_OT_set_clip_start_end(bpy.types.Operator):
bl_idname = "view3d.set_clip_start_end"
bl_label = "Set Clip Start/End"
bl_description = "Set Clip Start to 0.01m and Clip End to 300m"
def execute(self, context):
set_clip_start_end()
return {'FINISHED'}
def menu_func(self, context):
self.layout.separator() # 区切り線を追加
self.layout.operator(VIZ_OT_set_unit_scale.bl_idname, text="Set Unit Scale to 0.01")
self.layout.operator(VIZ_OT_set_fps.bl_idname, text="Set FPS to 59.94")
self.layout.operator(VIZ_OT_set_clip_start_end.bl_idname, text="Set Clip Start/End")
def register():
bpy.utils.register_class(VIZ_OT_set_unit_scale)
bpy.utils.register_class(VIZ_OT_set_fps)
bpy.utils.register_class(VIZ_OT_set_clip_start_end)
bpy.types.VIEW3D_MT_object_context_menu.append(menu_func)
def unregister():
bpy.utils.unregister_class(VIZ_OT_set_unit_scale)
bpy.utils.unregister_class(VIZ_OT_set_fps)
bpy.utils.unregister_class(VIZ_OT_set_clip_start_end)
bpy.types.VIEW3D_MT_object_context_menu.remove(menu_func)
if __name__ == "__main__":
register()
ほぼ修正なしで動作しました。すごいですね、ChatGPT。速度がものすごく速くなってて、これなら無料バージョンでもストレスなく使えるからお世話になる機会が多くなりそうです。
ちなみにChatGPTさん曰く、これをインストールするには
1. スクリプトをPythonファイルとして保存 上記のスクリプトをテキストエディタにコピーし、ファイル名を setup_for_viz_scene.py として保存します。 2. Blenderのアドオンとしてインストール Blenderを起動します。 Edit -> Preferences -> Add-ons を開きます。 Install... ボタンをクリックし、先ほど保存した setup_for_viz_scene.py ファイルを選択してインストールします。 アドオンリストに「Setup for Viz Scene」が表示されるので、チェックボックスをオンにして有効化します。
ということです。
ほぼ修正なしで動いたってのの「ほぼ」の理由は、Clip Start/Endの値の設定値がUnit Scaleを変更する前のUnit基準で設定されていたからで、それ以外は完璧です。すごい世の中になっているなと今更思うのでした。
正距方位図法化
先日のGeoPandasで地図を出せたわーいって喜んでたら、必要な図法は正距方位図法でした。
GeoPandasでGeoDataFrameに対して to_crs("正距方位図法を示す文字列")って指定は単純にはできないようで、まずpyporjモジュールを使って座標参照系(Coordinate Reference System)ってのを作るのだそうです。前のコードの
gdf_WebMerc = gdf_withColor.to_crs("EPSG:3857")
の代わりに from pyproj import CRS した上で
aeqd = CRS(proj='aeqd', ellps='WGS84', lat_0=35.6580992222, lon_0=139.7413574722).srs gdf_WebMerc = gdf_withColor.to_crs(crs=aeqd)
としときます。まあ本来は gdf_WebMerc って変数名じゃなくて gdf_AE とかにしとくべきなのだろうけど、そこはそれ。手抜き。
projで図法を指定しており、正距方位図法(Azimuthal Equidistant Projection)はaeqdのようです。pyprojのgithubでpyproj.projのソースコードを見ると150以上の投影法に対応しているみたいですね。
lat_0とlon_0で中心となるところの緯度経度を指定しやす。入っている数字は国土地理院で配布されている日本地図に記された位置のはず。たぶん日本経緯度原点で「東京都港区麻布台二丁目十八番一地内 日本経緯度原点金属標の十字の交点」と定義されているようです。東経 139度44分28秒8869,北緯 35度39分29秒1572。
ellps は地球をどのような楕円体でモデル化しているかを示してて、この場合WGS84測地系で採用されているものを使っているという意味みたいです。参考にしたページには datum も指定されていたけど、それは測地系の定義を指定してるところで微妙に歪んだ楕円体である地球をどんな形で捉えているかって情報の模様です。無くても結果は変わってないように見えます。
最後のsrsで文字列に変換してto_crsの引数に食わせているということらしい。
そんなわけでこんな風にすれば結果が出たのはとりあえず確認できたので満足です。
GeoPandas のお勉強(ゴミコードのみ)
import geopandas as gpd
import pandas as pd
import random
import svgwrite
import re
import datetime
print( datetime.datetime.now())
#基盤地図情報のgeoJSONデータを読み込み
gdf = gpd.read_file('./N03-20230101_12_GML/N03-23_12_230101.geojson', encoding='SHIFT-JIS')
#列の名前を変更
gdf_renamed = gdf.rename(columns={"N03_001":"Prefectures", \
"N03_002":"BranchGov", \
"N03_003":"County", \
"N03_004":"City", \
"N03_007":"AreaCode"})
#東京都以外の"City"列の名前に「区」が含まれる行の"City"列の値を"Country"と同じにする
gdf_renamed.loc[ (gdf_renamed["Prefectures"]!="東京都") & (gdf_renamed['City'].str.contains("区")) , 'City'] = gdf_renamed["County"]
#同じ市町村名を持つ行は一つの行にまとめる
gdf_grouped = gdf_renamed.dissolve(by=['Prefectures','City'], as_index=False)
#各市町村に適当すぎる色をつける
hexColors = []
for i in range(len(gdf_grouped)):
hexColor = '#' + format(random.randrange(255), '02x') + \
format(random.randrange(255), '02x') + \
format(random.randrange(255), '02x')
hexColors.append(hexColor)
cityNames = []
for i , row in gdf_grouped.iterrows():
cityNames.append( row["City"] )
pdf_colors = pd.DataFrame({ 'City':cityNames, 'Color':hexColors})
pdf_mrgedColor = pd.merge(gdf_grouped, pdf_colors ,on='City' )
gdf_withColor = gpd.GeoDataFrame(pdf_mrgedColor)
#図法をWebメルカトルに
gdf_WebMerc = gdf_withColor.to_crs("EPSG:3857")
#ポイント削減
gds_WebMercSimple = gdf_WebMerc["geometry"].simplify(tolerance=10.)
#svgファイルへの書き出し
docSize = 2000
viewBoxSize = "0 0 %d %d"%(docSize, docSize)
bbox = gdf_WebMerc.total_bounds
xLength = bbox[2] - bbox[0]
yLength = bbox[3] - bbox[1]
if xLength > yLength:
scale = docSize / xLength
else:
scale = docSize / yLength
gds_WebMercSimple = gds_WebMercSimple.translate( -bbox[0] - xLength*0.5 , -bbox[1] - yLength*0.5)
gds_WebMercSimple = gds_WebMercSimple.scale(scale, -scale, origin=(docSize * 0.5 ,docSize * 0.5))
gdf_WebMercDeleted = gdf_WebMerc.drop('geometry', axis=1)
gdf_WebMercDeleted['geometry'] = gds_WebMercSimple
dwg = svgwrite.Drawing( "chibaMapWebMelc.svg", size=( docSize , docSize ), profile='tiny')
grp1 = dwg.add(dwg.g(id='市町村'))
for i , row in gdf_WebMercDeleted.iterrows():
city_svg = row.geometry.svg()
startIndies = [m.span() for m in re.finditer('M', city_svg)]
endIndies = [m.span() for m in re.finditer('z', city_svg)]
svgpath = ""
for j in range(len(startIndies)):
svgpath += city_svg[startIndies[j][0]:endIndies[j][1]]
path = dwg.path( svgpath , stroke='none', stroke_width=3.0, fill=row['Color'], id=row['Prefectures'] + row['City'])
grp1.add( path )
dwg.save()
print( datetime.datetime.now())
GeoPandas のお勉強
必要にかられてというより、ちょっと落ちつているのでGeoPandasを触っているのですけど基本が分かってないから苦戦をしています。
shapefileとかgeoJSONを読み込むとテーブルデータが作成されましてそれがGeoDataFrameというもの。表だから行と列があり、各行にindexといくつかのデータが保持できるのだけど、その中にジオメトリ情報も保持できて、それらデータを使ってまあ便利って処理ができるのがGeoPandasということみたい。ジオメトリってのは点や線、ポリゴンっすね。
国土数値情報ダウンロードサイトからダウンロードできる行政区域データの千葉県のを落としてそれを読んでみました。そのデータを元に千葉県の地図のsvgで書き出すのが目的です。
import geopandas as gpd
gdf = gpd.read_file('./N03-20230101_12_GML/N03-23_12_230101.geojson', encoding='SHIFT-JIS')
gdf.info()
そうすると帰ってくる内容は
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 2265 entries, 0 to 2264 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 N03_001 2265 non-null object 1 N03_002 0 non-null object 2 N03_003 86 non-null object 3 N03_004 2265 non-null object 4 N03_007 2265 non-null object 5 geometry 2265 non-null geometry dtypes: geometry(1), object(5) memory usage: 106.3+ KB
というものでした。N03_001〜N03_007が列の名前ということになります。わかりにくいので名前をつけてみるなら、たとえば
N03_001→都道府県名→Prefectures
N03_002→支庁・振興局名→BranchGov
N03_003→郡・政令都市名→County
N03_004→市区町村名→City
N03_005→無い
N03_006→無い
N03_007→行政区域コード→AreaCode
とかにしてみます。なを英語としてはたぶん正しくないですw
gdf_renamed = gdf.rename(columns={"N03_001":"Prefectures", \
"N03_002":"BranchGov", \
"N03_003":"County", \
"N03_004":"City", \
"N03_007":"AreaCode"})
gdf_renamed.info()
<class 'geopandas.geodataframe.GeoDataFrame'> RangeIndex: 2265 entries, 0 to 2264 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Prefectures 2265 non-null object 1 BranchGov 0 non-null object 2 County 86 non-null object 3 City 2265 non-null object 4 AreaCode 2265 non-null object 5 geometry 2265 non-null geometry dtypes: geometry(1), object(5) memory usage: 106.3+ KB
市町村ごとに分割された地図を描きたいので、City列で同じ名前の行の中のジオメトリを一行にまとめるって処理をする時、dissolveメソッドを使うと良いのだけど、政令指定都市の場合Cityに入っているのは〜区なんすよね。千葉市青葉区だったら千葉市がCountyに、青葉区がCityに入っている。この目的とするところではCityに千葉市が入っていて欲しいのでどうしようかと悩みました。とりあえずCountyに値が入っててCityの値に「区」が含まれているという条件の行のCity列にCounty列の値を入れるって処理をすることにしました。 東京都以外の都道府県に市町村に「区」の入った名前はないと信じて、東京都以外のCityのとこに「区」が入った行のCity列にCounty列の値を入れるって処理にします。(ネット上の情報によると自治体名に区が入っているところはないそうなので、これで行けるはず)
gdf_renamed.loc[ (gdf_renamed["Prefectures"]!="東京都") & (gdf_renamed['City'].str.contains("区")) , 'City'] = gdf_renamed["County"]
これで千葉市青葉区みたいに〜区のところは〜市だけになったのでdissolveで1市町村区1行という状態を作ります。
gdf_grouped = gdf_renamed.dissolve(by=['City'], as_index=False)
以上で出来上がるGeoDataFrameであるgdf_groupedを図法変換してplotしてあげればとりあえずいいかと思ったのだけど、plotで使用される matplotlib.pyplot の処理だと、どうやら市町村ごとにsvgの別グループとして設定することができないようなのですね。仮に全ての市町村を別々の色に塗りつぶしていたとしても、〜町の形が欲しいってIllusratorで選ぼうとしても島がいっぱいあるような町だと必要要素を選択するのに難儀しそうです。
ということで、市町村区ごとにsvgの別々のグループにできるようにsvgwriteモジュールを使うことにしました。とはいえ、svgに書き出す前にGeoDataFrameの各市町村区の行にランダムな色を割り振り、その色でその地域の範囲を塗りつぶそうと思います。
hexColors = []
for i in range(len(gdf_grouped)):
hexColor = '#' + format(random.randrange(255), '02x') + \
format(random.randrange(255), '02x') + \
format(random.randrange(255), '02x')
hexColors.append(hexColor)
cityNames = []
for i , row in gdf_grouped.iterrows():
cityNames.append( row["City"] )
pdf_colors = pd.DataFrame({ 'City':cityNames, 'Color':hexColors})
pdf_mrgedColor = pd.merge(gdf_grouped, pdf_colors ,on='City' )
gdf_withColor = gpd.GeoDataFrame(pdf_mrgedColor)
16進数の色指定の文字列を作る方法がそうやるんだって感心してました。gdf_withColorは各行にランダムな色を設定したColor列が追加されてます。
図法変換し、Illustratorはパス1つにつき32000個のポイントしか許さないという制限に対処するためにポイント数を減らす処理をします。
#図法をWebメルカトルに
gdf_WebMerc = gdf_withColor.to_crs("EPSG:3857")
gds_WebMercSimple = gdf_WebMerc["geometry"].simplify(tolerance=10.)
svgへの書き出しです。svgファイルの中央に図形が配置されるようにするための処理がこれでいいのかちょっとわからんです。
docSize = 2000
viewBoxSize = "0 0 %d %d"%(docSize, docSize)
bbox = gdf_WebMerc.total_bounds
xLength = bbox[2] - bbox[0]
yLength = bbox[3] - bbox[1]
if xLength > yLength:
scale = docSize / xLength
else:
scale = docSize / yLength
gds_WebMercSimple = gds_WebMercSimple.translate( -bbox[0] - xLength*0.5 , -bbox[1] - yLength*0.5)
gds_WebMercSimple = gds_WebMercSimple.scale(scale, -scale, origin=(docSize * 0.5 ,docSize * 0.5))
gdf_WebMercDeleted = gdf_WebMerc.drop('geometry', axis=1)
gdf_WebMercDeleted['geometry'] = gds_WebMercSimple
dwg = svgwrite.Drawing( "chibaMapWebMelc.svg", size=( docSize , docSize ), profile='tiny')
grp1 = dwg.add(dwg.g(id='市町村'))
for i , row in gdf_WebMercDeleted.iterrows():
city_svg = row.geometry.svg()
startIndies = [m.span() for m in re.finditer('M', city_svg)]
endIndies = [m.span() for m in re.finditer('z', city_svg)]
svgpath = ""
for j in range(len(startIndies)):
svgpath += city_svg[startIndies[j][0]:endIndies[j][1]]
path = dwg.path( svgpath , stroke='none', stroke_width=3.0, fill=row['Color'], id=row['Prefectures'] + row['City'])
grp1.add( path )
dwg.save()

法線マップを作ろう
法線マップをさくっとそれっぽく出せればいいってときPhotoshopの3D機能は便利だったのだけど、現行バージョンに搭載されているフィルタ→3D→法線マップを作成...は知っている機能となんか違っている上に将来削除されると明言されているものに成り下がってます。
ってことで何かいいツールないかなぁって思っていたのですけど、Kritaで行ける模様。
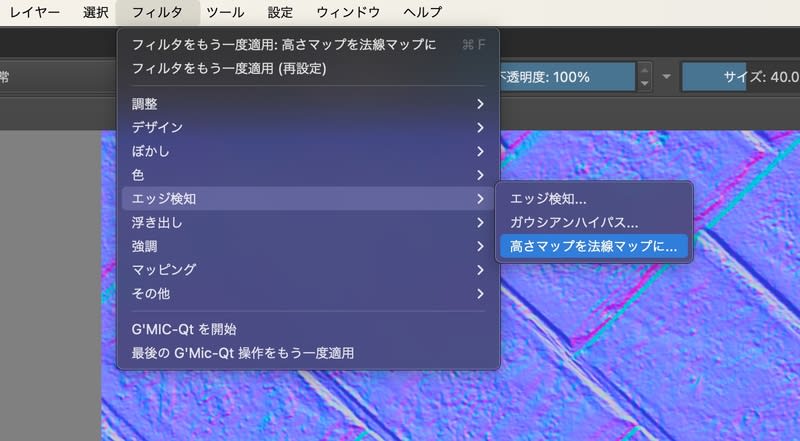

あら素敵。
ネット上のサービスとかあるけど、お仕事関係は得てしてネット上のツールは使用禁止だったりしますしね。ありがたいことです。
ちなみにPhotoshopから3D機能を廃止する方向で動いているAdobe様はSubstanceに誘導したいようです。この場合はSubstance 3D Samplerを使えって感じかね。入力画像からPBRに必要な各種素材を出力してくれるのだからこっちの方がはるかにいいのは間違い無いのだけど、それっぽくさくっとって目的にはちょっと大袈裟に感じます。あと値段。単体販売はされてないから個人用途ではSubstance 3D TexturingかSubstance 3D Collectionのサブスクに入りなさいってことだけど、Texturingで月額2680円なのよね。ちょっと辛いねぇって思ったりはするわけです、自宅用途としては。
なを職場用途で入ろうとした場合はSubstance 3D Collectionしか選択肢がない模様。
カレンダ
8月30日まで通常78,982円なのが50,247円とかなり安くなってました。次はいつやるかね。
ロジクール KX850MSG MX MECHANICAL MINI for Mac
ちょっと欲しいかもというキーボードのうちの一つ。テンキーのない最小の配列のメカニカルキーボード。参考:待望のUS配列!ロジクール『MXメカニカルMini for Mac』打鍵感も見た目も最高の一言【今日のライフハックツール】[ライフハッカー・ジャパン]
いわゆる板タブ。初心者向けのカテゴリのタブレットということになるけど、数値上の性能は個人的には十分で、次買う時はこれにする予定。参考:Wacom One[wacom.com]
ワコム Dr. Grip Digital for Wacom ブラック CP202A02A
とはいえWacom One付属のペンは気に入らなそうなので、この手の普通の文房具のグリップ感を保持したペンの追加購入はしておきたい。参考:Wacom Store
CalDigit Thunderbolt 4 Element Hub
Thunderbolt 4のUSBハブ。とにかくThunderbolt/USBポートが欲しい向きにはこれは最適解かもしれないと思ってる。参考:製品ページ[caldigit.com]