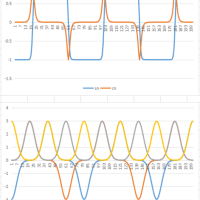
本日日曜日は私にとってちょっと特別な日なので、ゆっくりお休みしました。何、世間的には大したことはありません。
結局、今回の結論としてはコンパイル派とインタープリタ派のコンピュータ(計数型電子式計算機)のごく初期からある相克を確認するだけとなりました。
もちろん、コンパイル派の代表はFORTRANで、インタープリタ派の代表はLISPです。ネイティブコンパイラ(機械語に翻訳される)で無いFORTRANなど無意味です。LISPではごく初期に中間言語が定義されて、現在のLISPは普通はコンパイルされますが、その出力は中間言語で、中間言語インタプリタが解釈実行します。何がどうなっているのかは、実例を見れば一発理解できます、が、ネットが発達した現在でも確認には多少の努力が必要かもしれません。
私の感覚では、そのコンパイル派とはアセンブラ風の1パスコンパイラを想起すれば良いです。アセンブラはニーモニックと呼ばれるbit列の機械語に適当にアルファベット列の記号を割り当てた部分が目立ちますが、命令の条件分岐や繰り返しの先頭のメモリアドレスを示すラベルと、(大域・局所)変数のアドレスを具体的な数値に変換するのが大いに役立ちます。これはマイコンのごく初期にいわゆるハンドアセンブルを経験した方にはいやほど分かる便利な仕組みです。
インタプリタでは普通は実行時に命令の分岐先のアドレスや変数のありかを探します。
一見、無駄な動作に思えますが、実行時にプログラムをプログラム自身が書き換えるメタ言語の要素を持っている場合、LISPで言うeval関数やapply関数がある場合は、刻々とプログラムや変数の位置までもがダイナミックに変化して行きますから、探さないと本体には到達できません。
ですからアルゴリズムの教科書では探索アルゴリズムが必ず出てきます。探す場合はデータが整列しているととても都合が良いので、ソート(分類)のアルゴリズムも重要課題となります。
もう一つの話題は可変長文字列の扱いです。素朴に実現すると非効率になります。工夫が必要で、私の経験からは上述の探索に適したデータ構造と統合するとシステムが簡明になります。簡明となる理由は自明では無いです。今後の私の課題とさせていただきます。
結局、今回の結論としてはコンパイル派とインタープリタ派のコンピュータ(計数型電子式計算機)のごく初期からある相克を確認するだけとなりました。
もちろん、コンパイル派の代表はFORTRANで、インタープリタ派の代表はLISPです。ネイティブコンパイラ(機械語に翻訳される)で無いFORTRANなど無意味です。LISPではごく初期に中間言語が定義されて、現在のLISPは普通はコンパイルされますが、その出力は中間言語で、中間言語インタプリタが解釈実行します。何がどうなっているのかは、実例を見れば一発理解できます、が、ネットが発達した現在でも確認には多少の努力が必要かもしれません。
私の感覚では、そのコンパイル派とはアセンブラ風の1パスコンパイラを想起すれば良いです。アセンブラはニーモニックと呼ばれるbit列の機械語に適当にアルファベット列の記号を割り当てた部分が目立ちますが、命令の条件分岐や繰り返しの先頭のメモリアドレスを示すラベルと、(大域・局所)変数のアドレスを具体的な数値に変換するのが大いに役立ちます。これはマイコンのごく初期にいわゆるハンドアセンブルを経験した方にはいやほど分かる便利な仕組みです。
インタプリタでは普通は実行時に命令の分岐先のアドレスや変数のありかを探します。
一見、無駄な動作に思えますが、実行時にプログラムをプログラム自身が書き換えるメタ言語の要素を持っている場合、LISPで言うeval関数やapply関数がある場合は、刻々とプログラムや変数の位置までもがダイナミックに変化して行きますから、探さないと本体には到達できません。
ですからアルゴリズムの教科書では探索アルゴリズムが必ず出てきます。探す場合はデータが整列しているととても都合が良いので、ソート(分類)のアルゴリズムも重要課題となります。
もう一つの話題は可変長文字列の扱いです。素朴に実現すると非効率になります。工夫が必要で、私の経験からは上述の探索に適したデータ構造と統合するとシステムが簡明になります。簡明となる理由は自明では無いです。今後の私の課題とさせていただきます。