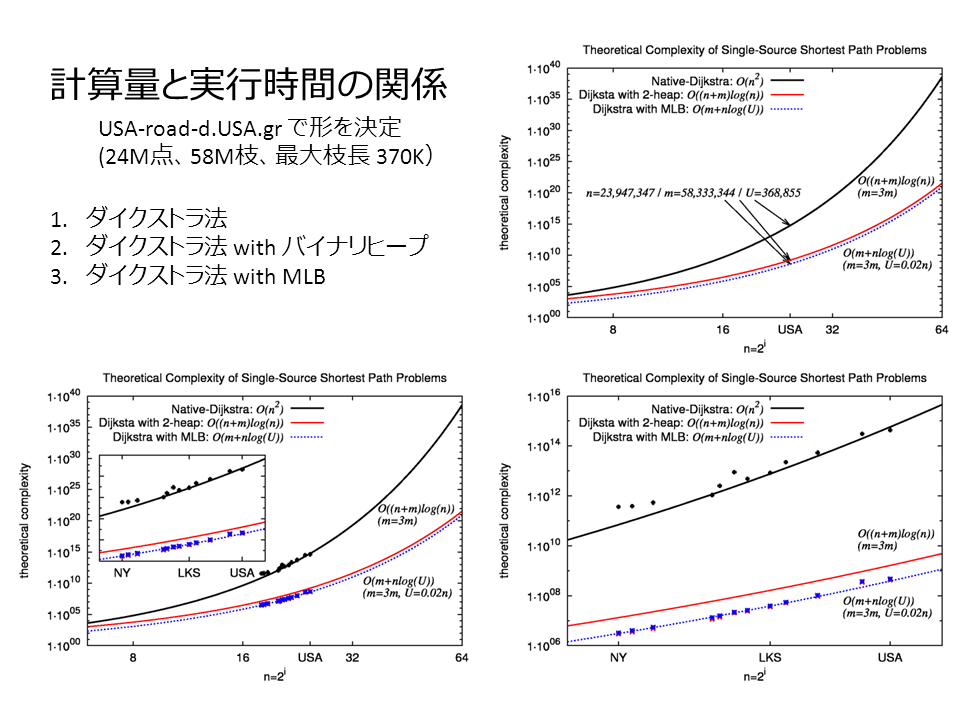
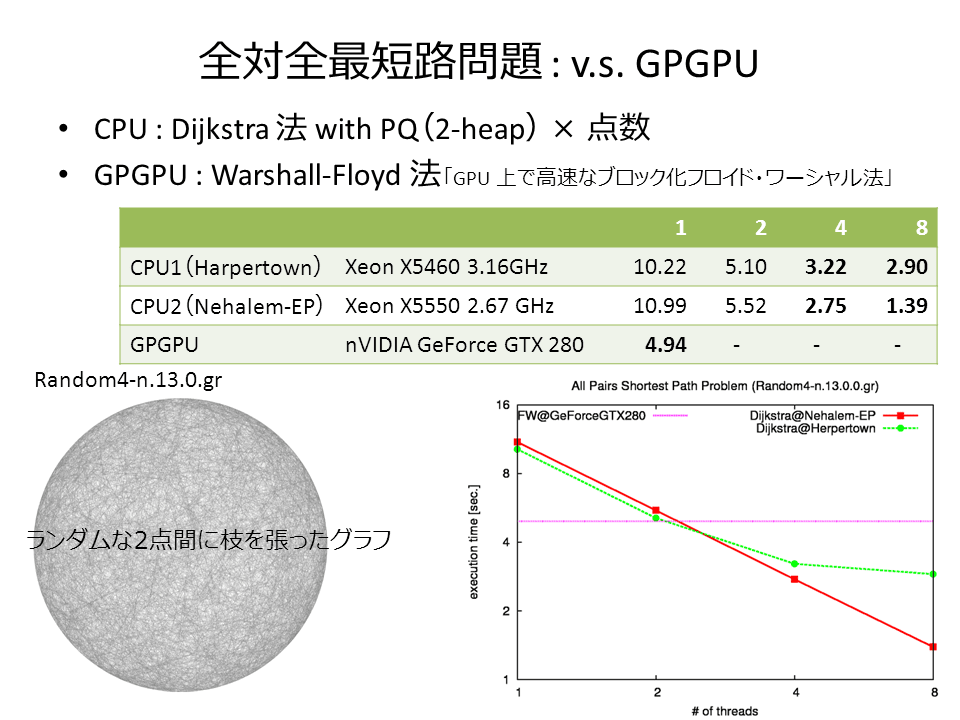
Gurobi 3.0.2 がリリースされたので、3.0.1 と幾つかの問題で比較してみた。MIP のアルゴリズムの性質上、全ての問題で 3.0.2 が速いわけではないが、MIPLIB2003 の問題などを中心に様々なチューニングが行われているのだろう。
○問題 S-20-30-2-3.mps(ロットサイズ決定問題)
3.0.1 : 330.30秒
3.0.2 : 503.36秒
○問題 gmpl-10-0.2.mps (仮想マシンマイグレーション問題)
3.0.1 : 227.96秒
3.0.2 : 125.21秒
○問題 roll3000.mps (MIPLIB2003)
3.0.1 : 49.87秒
3.0.2 : 31.02秒
○問題 mod011.mps (MIPLIB2003)
3.0.1 : 34.73秒
3.0.2 : 21.50秒
○サーバ (4 CPU x 6 コア = 24 コア)
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
OS : Fedora 13 for x86_64
○問題 S-20-30-2-3.mps(ロットサイズ決定問題)
3.0.1 : 330.30秒
3.0.2 : 503.36秒
○問題 gmpl-10-0.2.mps (仮想マシンマイグレーション問題)
3.0.1 : 227.96秒
3.0.2 : 125.21秒
○問題 roll3000.mps (MIPLIB2003)
3.0.1 : 49.87秒
3.0.2 : 31.02秒
○問題 mod011.mps (MIPLIB2003)
3.0.1 : 34.73秒
3.0.2 : 21.50秒
○サーバ (4 CPU x 6 コア = 24 コア)
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
OS : Fedora 13 for x86_64