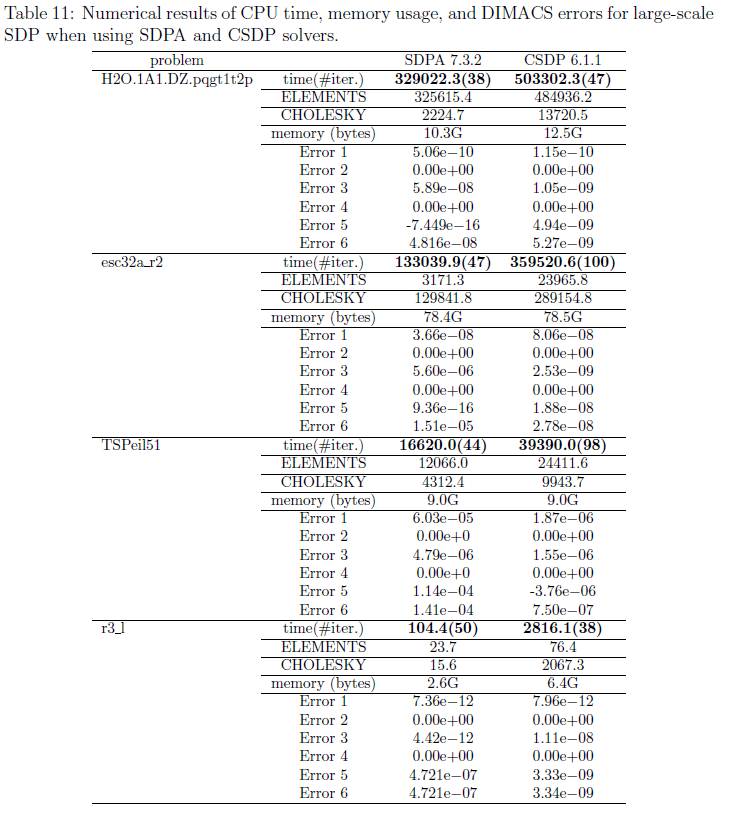
以下の結果等から考察してみると 4-way のシステムでは affinity の設定が重要となる。計算サーバ2においても affinity の設定の効果を見てみないとわからないが、ベストの設定を行えば、SDPA の性能的には Nehalem-EX 32 コア > Magny-Cours 48 コアになると予想される。
◯FH2+.1A1.STO6G.pqgt1t2p.dat-s
計算サーバ1: 53.01s
計算サーバ1: 45.68s (numactl -i all)
計算サーバ2: 47.23s
◯Be.1S.SV.pqgt1t2p.dat-s
計算サーバ1: 2042.51s
計算サーバ1: 723.74s (numactl -i all)
計算サーバ2: 786.97s
○計算サーバ1 (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4個
メモリ : 256GB
◯計算サーバ2 (4CPU x 8 コア = 32 コア)
CPU : Intel Xeon X7550 (2.0GHz / 18MB L3) x 4個
メモリ : 512GB
◯FH2+.1A1.STO6G.pqgt1t2p.dat-s
計算サーバ1: 53.01s
計算サーバ1: 45.68s (numactl -i all)
計算サーバ2: 47.23s
◯Be.1S.SV.pqgt1t2p.dat-s
計算サーバ1: 2042.51s
計算サーバ1: 723.74s (numactl -i all)
計算サーバ2: 786.97s
○計算サーバ1 (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4個
メモリ : 256GB
◯計算サーバ2 (4CPU x 8 コア = 32 コア)
CPU : Intel Xeon X7550 (2.0GHz / 18MB L3) x 4個
メモリ : 512GB