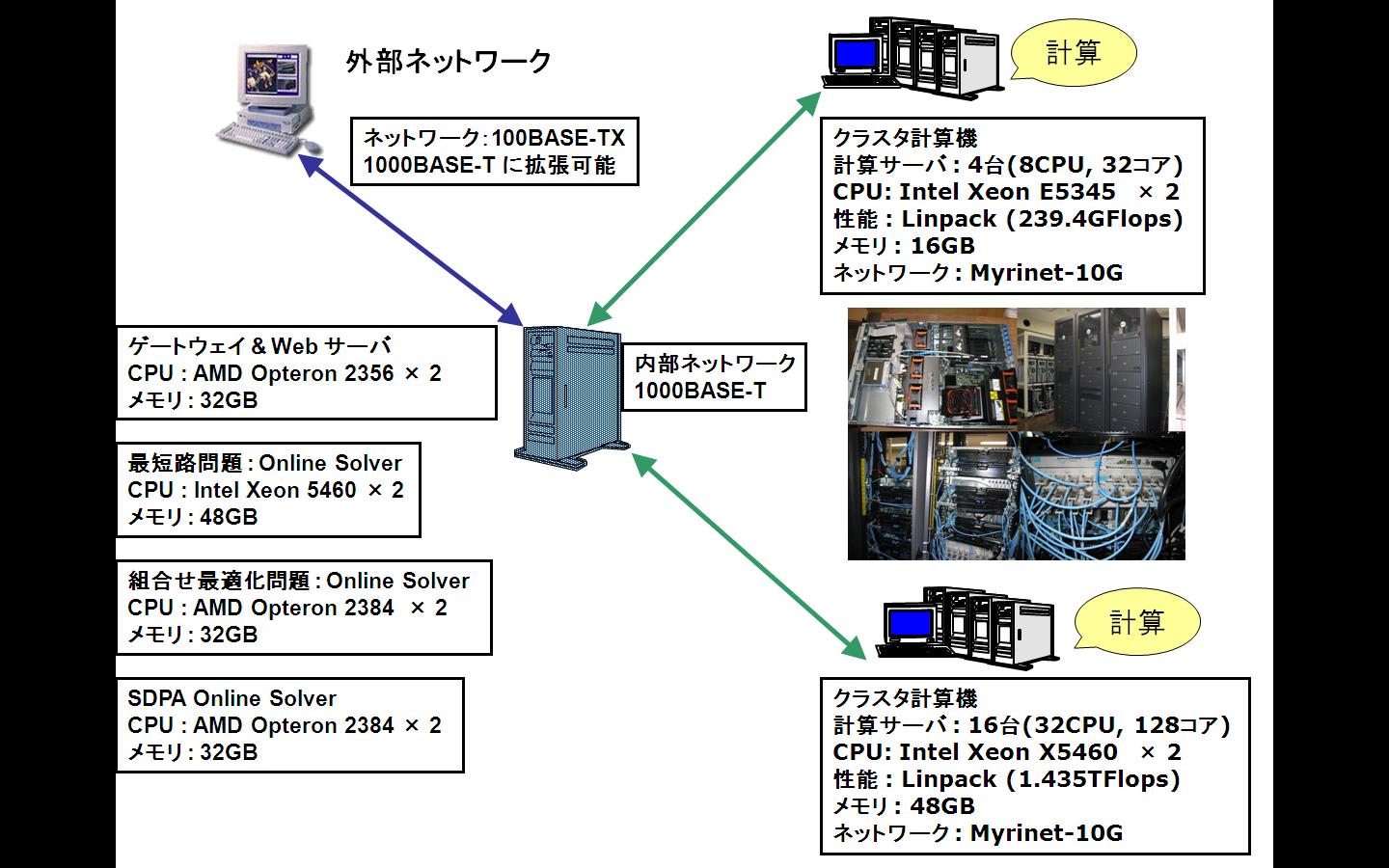
AMD Opteron (Shanghai 2384 2.7GHz)のサーバが二台納入されたので、Online Solver 用の外部向けサーバや計算サーバの一部を交代させることにした。現在でも最適化問題の規模と計算量が爆発的に増大しているので、多少計算サーバを増強しても焼け石に水的な感はあるが、それでも中小規模の問題では効果は非常に大きい。この AMD Shangahi マシンだが、以下のように性能を測定してみると、メモリバンド幅も大きく、高負荷(マルチスレッド)時の性能では Penryn 系 Xeon に匹敵する(
Nehalem には負ける)。
stream 8 スレッド
Function Rate (MB/s) Avg time Min time Max time
Copy: 21536.8626 0.0015 0.0015 0.0015
Scale: 21519.5972 0.0015 0.0015 0.0015
Add: 21420.0013 0.0023 0.0022 0.0023
Triad: 21212.3688 0.0023 0.0023 0.0023
1: Shanghai (AMD Opteron 2384 : 問題 theta6.dat-s)
SDPA 7.2.0 (1スレッド : GotoBLAS)
1m20.945s (18反復)
SDPA 7.2.0 (4スレッド : GotoBLAS)
41.415s (18反復)
SDPA 7.2.0 (8スレッド : GotoBLAS)
36.715s (18反復)
SDPA 7.x 開発版 (4スレッド: Pthread + GotoBLAS)
24.793s (18反復)
SDPA 7.x 開発版 (8スレッド: Pthread + GotoBLAS)
14.811s (18反復)
CSDP 6.0.1 (1スレッド : OpenMP + GotoBLAS)
1m15.116s(17反復)
CSDP 6.0.1 (4スレッド : OpenMP + GotoBLAS)
25.776s (17反復)
CSDP 6.0.1 (8スレッド : OpenMP + GotoBLAS)
18.217s (17反復)
Nehalem には負ける)。
stream 8 スレッド
Function Rate (MB/s) Avg time Min time Max time
Copy: 21536.8626 0.0015 0.0015 0.0015
Scale: 21519.5972 0.0015 0.0015 0.0015
Add: 21420.0013 0.0023 0.0022 0.0023
Triad: 21212.3688 0.0023 0.0023 0.0023
1: Shanghai (AMD Opteron 2384 : 問題 theta6.dat-s)
SDPA 7.2.0 (1スレッド : GotoBLAS)
1m20.945s (18反復)
SDPA 7.2.0 (4スレッド : GotoBLAS)
41.415s (18反復)
SDPA 7.2.0 (8スレッド : GotoBLAS)
36.715s (18反復)
SDPA 7.x 開発版 (4スレッド: Pthread + GotoBLAS)
24.793s (18反復)
SDPA 7.x 開発版 (8スレッド: Pthread + GotoBLAS)
14.811s (18反復)
CSDP 6.0.1 (1スレッド : OpenMP + GotoBLAS)
1m15.116s(17反復)
CSDP 6.0.1 (4スレッド : OpenMP + GotoBLAS)
25.776s (17反復)
CSDP 6.0.1 (8スレッド : OpenMP + GotoBLAS)
18.217s (17反復)