以下の opt クラスタ(16ノード, 32CPU, 192コア)と 4 GPU 搭載の計算サーバ(1ノード, 2CPU, 12コア)で SDPARA 7.5.0 の比較実験を行った。
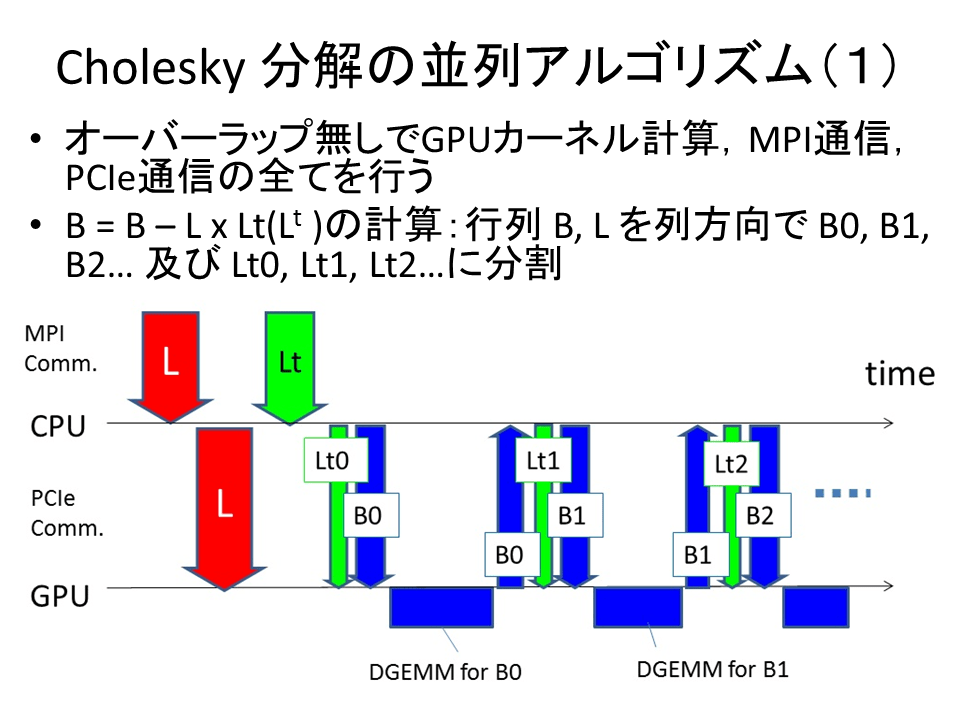
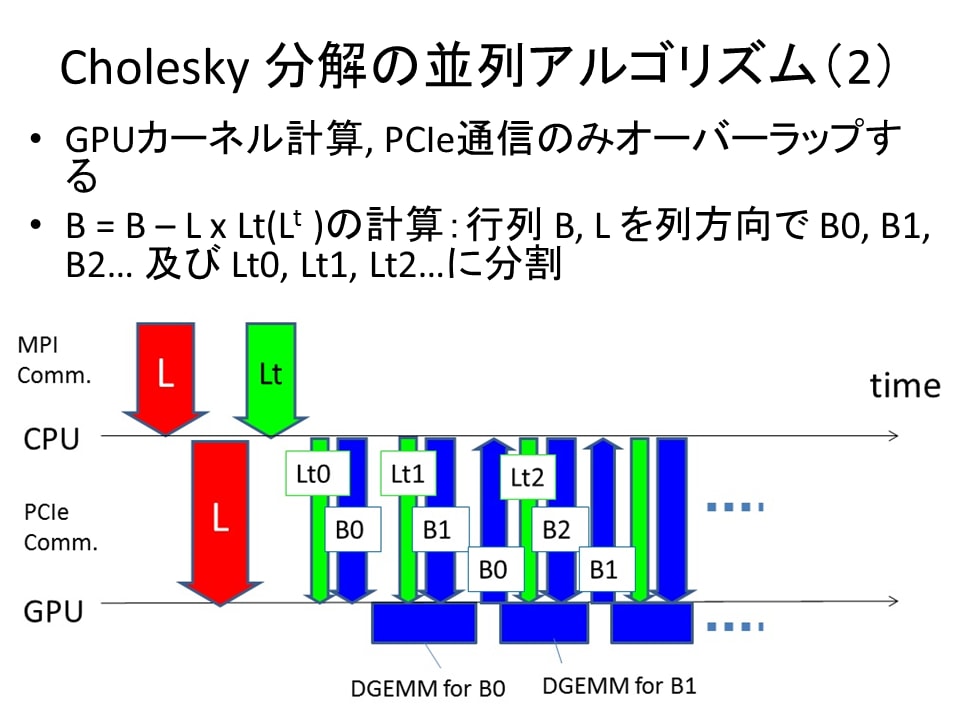
◯Cholesky 分解について
opt クラスタ : 35446秒
計算サーバ : 39768秒
32 CPU と 4 GPU では、Cholesky 分解に関してはあまり大きな差が無いことがわかる。
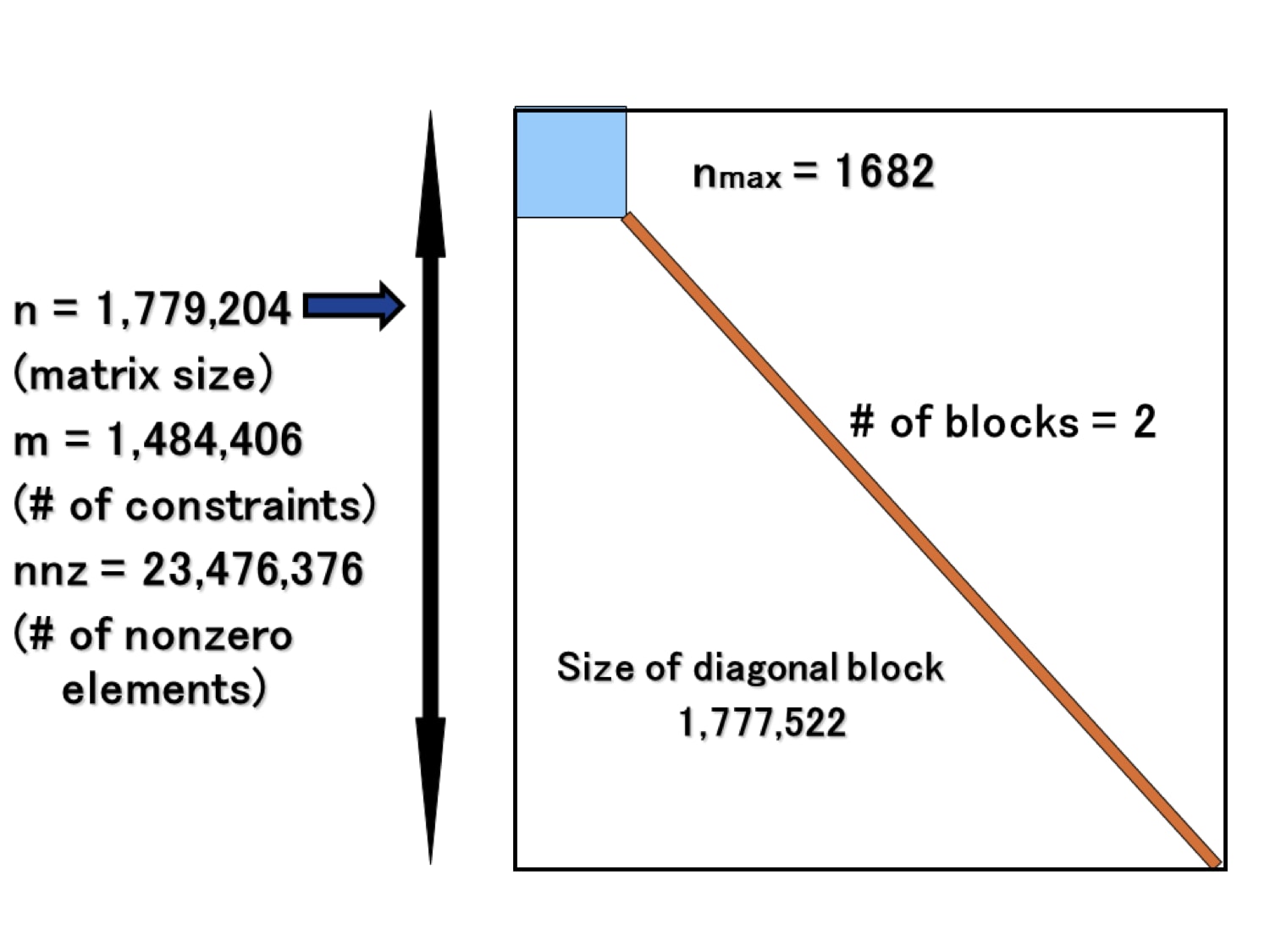
◯問題: tai24a.dat-s
Time(sec) Ratio(% : MainLoop)
Predictor time = 36111.259667, 99.795704
Corrector time = 56.431848, 0.155953
Make bMat time = 597.748313, 1.651915
Make bDia time = 73.065560, 0.201921
Make bF1 time = 0.000000, 0.000000
Make bF2 time = 0.000000, 0.000000
Make bF3 time = 0.000000, 0.000000
Make bPRE time = 0.000000, 0.000000
Make rMat time = 0.517326, 0.001430
Make gVec Mul = 0.159244, 0.000440
Make gVec time = 0.557191, 0.001540
copy gVec time = 0.000011, 0.000000
copy bMat time = 0.000000, 0.000000
symm bMat time = 0.000649, 0.000002
Cholesky bMat = 35446.006529, 97.957235
Ste Pre time = 0.007873, 0.000022
Ste Cor time = 0.411851, 0.001138
solve = 108.443750, 0.299691
copy DyVec = 0.144751, 0.000400
sumDz = 1.708230, 0.004721
makedX = 0.682788, 0.001887
symmetriseDx = 0.042061, 0.000116
makedXdZ = 2.433124, 0.006724
xMatTime = 0.358543, 0.000991
zMatTime = 0.495879, 0.001370
invzMatTime = 0.000000, 0.000000
xMatzMatTime = 0.000000, 0.000000
EigxMatTime = 0.172718, 0.000477
EigzMatTime = 0.176140, 0.000487
EigxMatzMatTime = 0.000000, 0.000000
updateRes = 1.600494, 0.004423
EigTime = 0.348858, 0.000964
sub_total_bMat = 35587.436326, 98.348085
Main Loop = 36185.184639, 100.000000
File Check = 0.000000, 0.000000
File Change = 0.006056, 0.000017
File Read = 11.672031, 0.032256
File Trans = 3.281213, 0.009068
Total = 36196.862726, 100.032273
○ OPT クラスタ
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.6 for x86_64
Time(sec) Ratio(% : MainLoop)
Predictor time = 52208.489161, 98.972120
Corrector time = 491.645597, 0.932017
Make bMat time = 6818.326969, 12.925566
Make bDia time = 143.903450, 0.272799
Make bF1 time = 0.000000, 0.000000
Make bF2 time = 0.000000, 0.000000
Make bF3 time = 0.000000, 0.000000
Make bPRE time = 0.000000, 0.000000
Make rMat time = 1.138909, 0.002159
Make gVec Mul = 0.260366, 0.000494
Make gVec time = 0.974972, 0.001848
copy gVec time = 0.000013, 0.000000
copy bMat time = 0.000001, 0.000000
symm bMat time = 5120.677215, 9.707316
Cholesky bMat = 39768.736191, 75.389965
Ste Pre time = 0.013926, 0.000026
Ste Cor time = 0.519987, 0.000986
solve = 985.750276, 1.868696
copy DyVec = 0.142678, 0.000270
sumDz = 2.018698, 0.003827
makedX = 2.146520, 0.004069
symmetriseDx = 0.061528, 0.000117
makedXdZ = 4.228492, 0.008016
xMatTime = 0.637930, 0.001209
zMatTime = 0.960215, 0.001820
invzMatTime = 0.000000, 0.000000
xMatzMatTime = 0.000000, 0.000000
EigxMatTime = 0.228020, 0.000432
EigzMatTime = 0.201835, 0.000383
EigxMatzMatTime = 0.000000, 0.000000
updateRes = 1.776776, 0.003368
EigTime = 0.429855, 0.000815
sub_total_bMat = 45932.375920, 87.074434
Main Loop = 52750.702889, 100.000000
File Check = 0.000000, 0.000000
File Change = 0.009525, 0.000018
File Read = 4.627067, 0.008772
File Trans = 0.051329, 0.000097
Total = 52755.339481, 100.008790
◯ 計算サーバ:Intel Xeon + 4 GPU マシン(1台)
CPU:Xeon X5690(3.46GHz,6コア)×2
メモリ:192GB(16GB×12)
HDD:SATA500GB×2(システム、システムバックアップ)
NIC : GbE x 1 & Inifiniband x 1
GPGPU:Tesla C2075×4
OS:CentOS 6.2

















{kind=link}