反復解法ライブラリ Lis は線形方程式及び固有値問題を反復法で解くためのライブラリで内部での 4 倍精度演算(実際には仮数部 104bit) や MPI, OpenMP による並列計算に対応している。
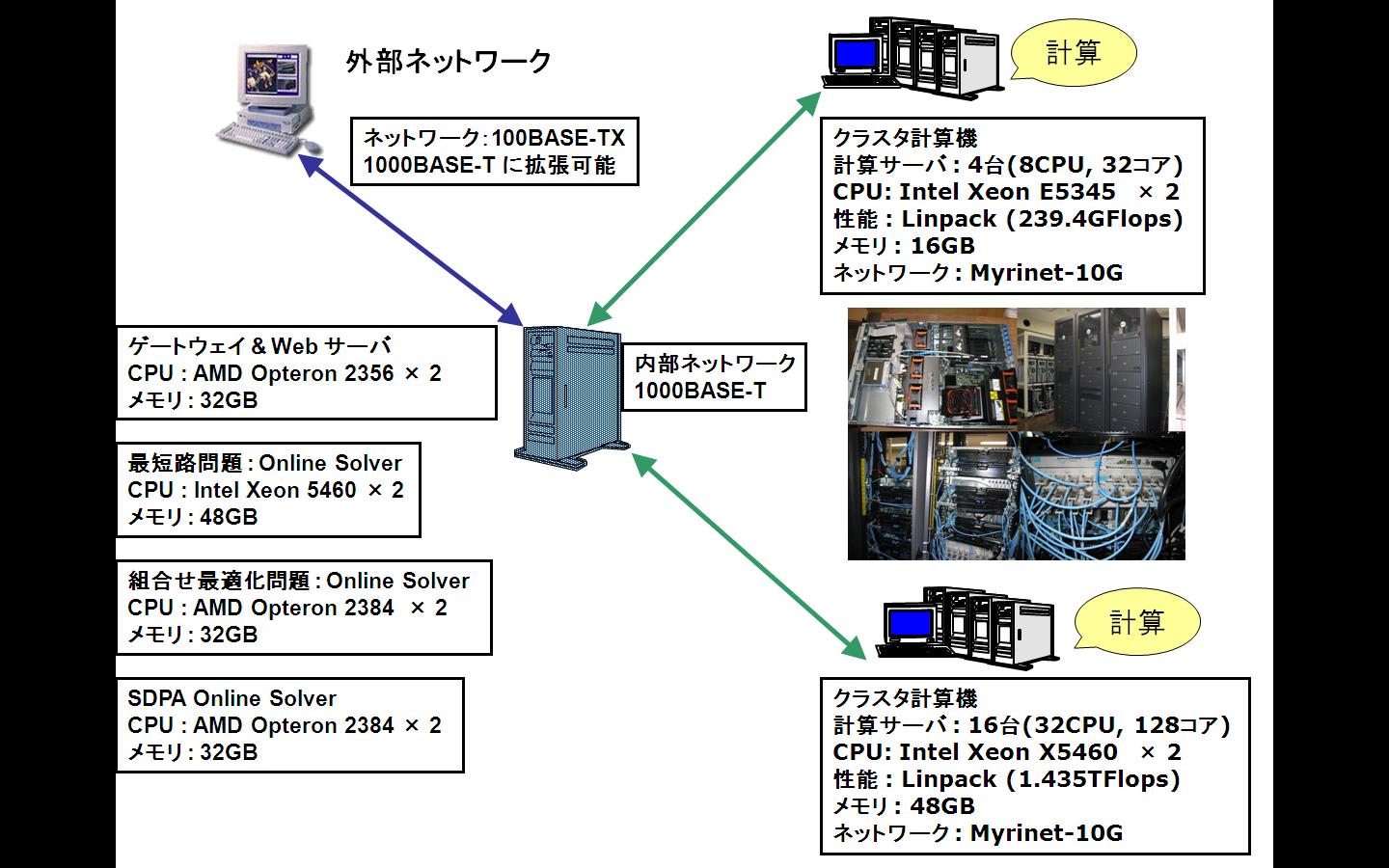
今回はパッケージに含まれる test4 を用いてみよう。実行には次のクラスタ計算機を用いる。もちろん OpenMP による実行ではクラスタ計算機でも 1 ノードしか使用しない。
●新 SDPA クラスタ (2008年)
16 Nodes, 32 CPUs, 128 CPU cores;
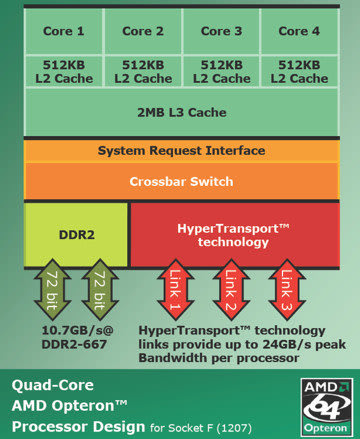
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
HDD : 6TB(RAID 5) / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.2 for x86_64
Linpack : R_max = 1.435TFlops, R_peak = 1.618TFlops, R_max / R_peak = 88.69%
A: 1 プロセス 1 スレッド
○ 倍精度
time ./test4 200000 2.0 -precision double
real 0m12.297s
○ 4倍精度
time ./test4 200000 2.0 -precision quad
real 0m41.726s
B: 1 プロセス 複数スレッド (OpenMP)
○ 倍精度
1 スレッド
real 0m14.147s
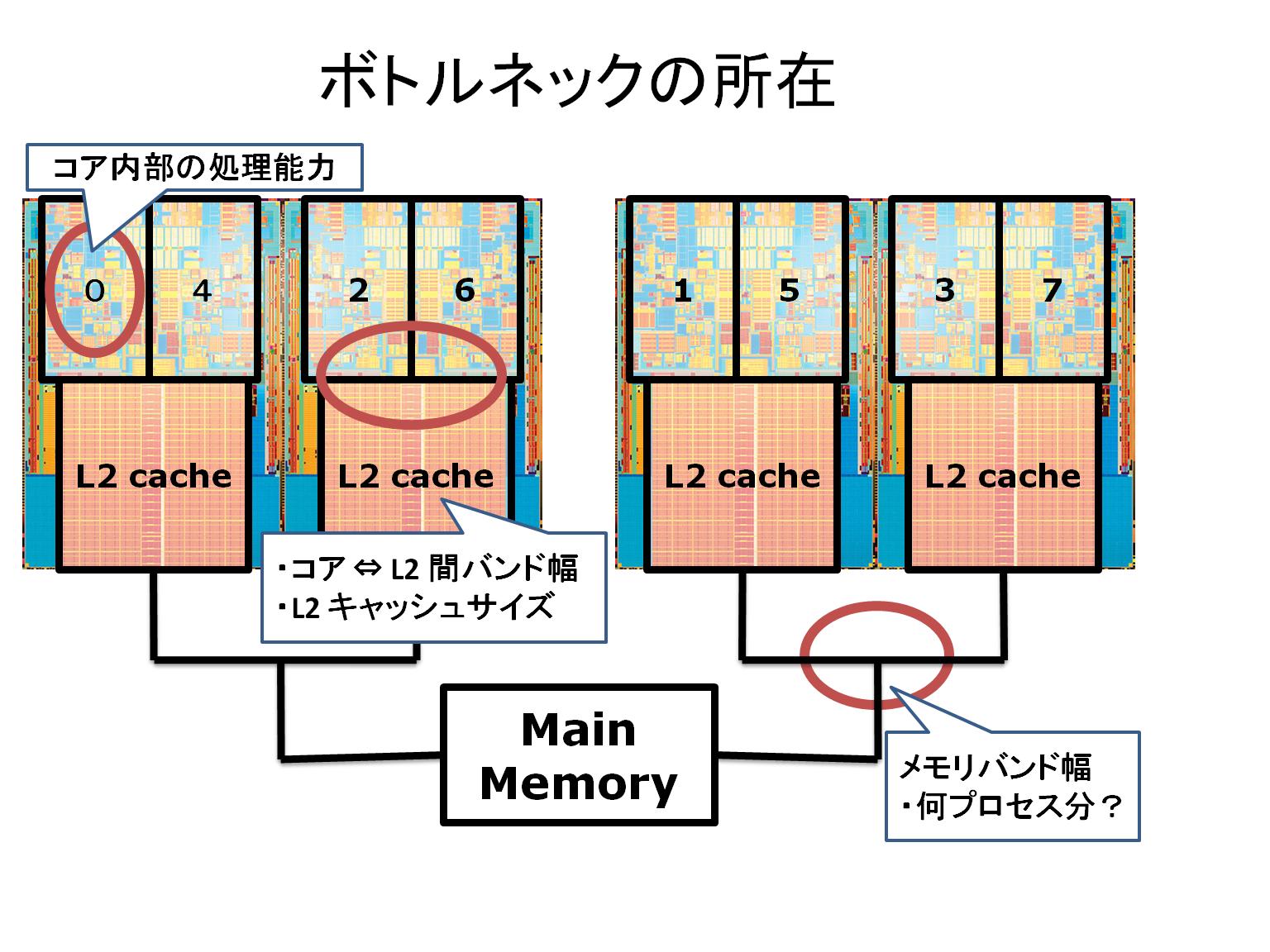
2 スレッド (time numactl --physcpubind=0,1 ./test4 200000 2.0 -precision double)
real 0m7.280s
2 スレッド (time numactl --physcpubind=0,2 ./test4 200000 2.0 -precision double)
real 0m9.704s
2 スレッド (time numactl --physcpubind=0,4 ./test4 200000 2.0 -precision double)
real 0m13.745s
4 スレッド (time numactl --physcpubind=0,2,1,3 ./test4 200000 2.0 -precision double)
real 0m5.058s
4 スレッド (time numactl --physcpubind=0,4,1,5 ./test4 200000 2.0 -precision double)
real 0m8.695s
4 スレッド (time numactl --physcpubind=0,4,2,6 ./test4 200000 2.0 -precision double)
real 0m12.533s
8 スレッド
real 0m9.098s
○ 4倍精度
1 スレッド
real 0m43.660s
2 スレッド (time numactl --physcpubind=0,1 ./test4 200000 2.0 -precision quad)
real 0m26.672s
2 スレッド (time numactl --physcpubind=0,2 ./test4 200000 2.0 -precision quad)
real 0m30.107s
2 スレッド (time numactl --physcpubind=0,4 ./test4 200000 2.0 -precision quad)
real 0m32.936s
4 スレッド (time numactl --physcpubind=0,2,1,3 ./test4 200000 2.0 -precision quad)
real 0m16.976s
4 スレッド (time numactl --physcpubind=0,4,1,5 ./test4 200000 2.0 -precision quad)
real 0m21.017s
4 スレッド (time numactl --physcpubind=0,4,2,6 ./test4 200000 2.0 -precision quad)
real 0m27.481s
8 スレッド
real 0m22.027s
OpenMP の場合では 4 スレッド (time numactl --physcpubind=0,2,1,3) が共に最高速ということなので予想通りの結果になった。