以前、作成した OR (オペレーションズ・リサーチ)研究ユニットが組織改変?で大型化して”超大規模グラフ解析プロジェクト”として再出発することになりました。計算量や要求されるメモリバンド幅を抑えた後に、超大規模スレッド並列処理で超大規模な最適化問題等を扱っていくという方針が最新の HPC 技術と結び付く形で大幅に強化されます。
ーー超大規模グラフ解析プロジェクトーー
○超大規模データを伴う最適化問題に対する高速計算システムの構築と評価
ー グラフ探索(最短路、幅優先探索、重要性計算)、数理計画問題(半正定値計画問題:SDP, 混合整数計画問題 MIP or MINLP 等)
○リアルタイム大規模グラフストリーム処理系及びグラフ最適化ライブラリの開発
○大規模グラフ処理向けオンデマンド階層型データストアの開発
○大規模グラフストリームデータの対話的な閲覧システム
ーーーーーーーーーーーーーーーーーーー
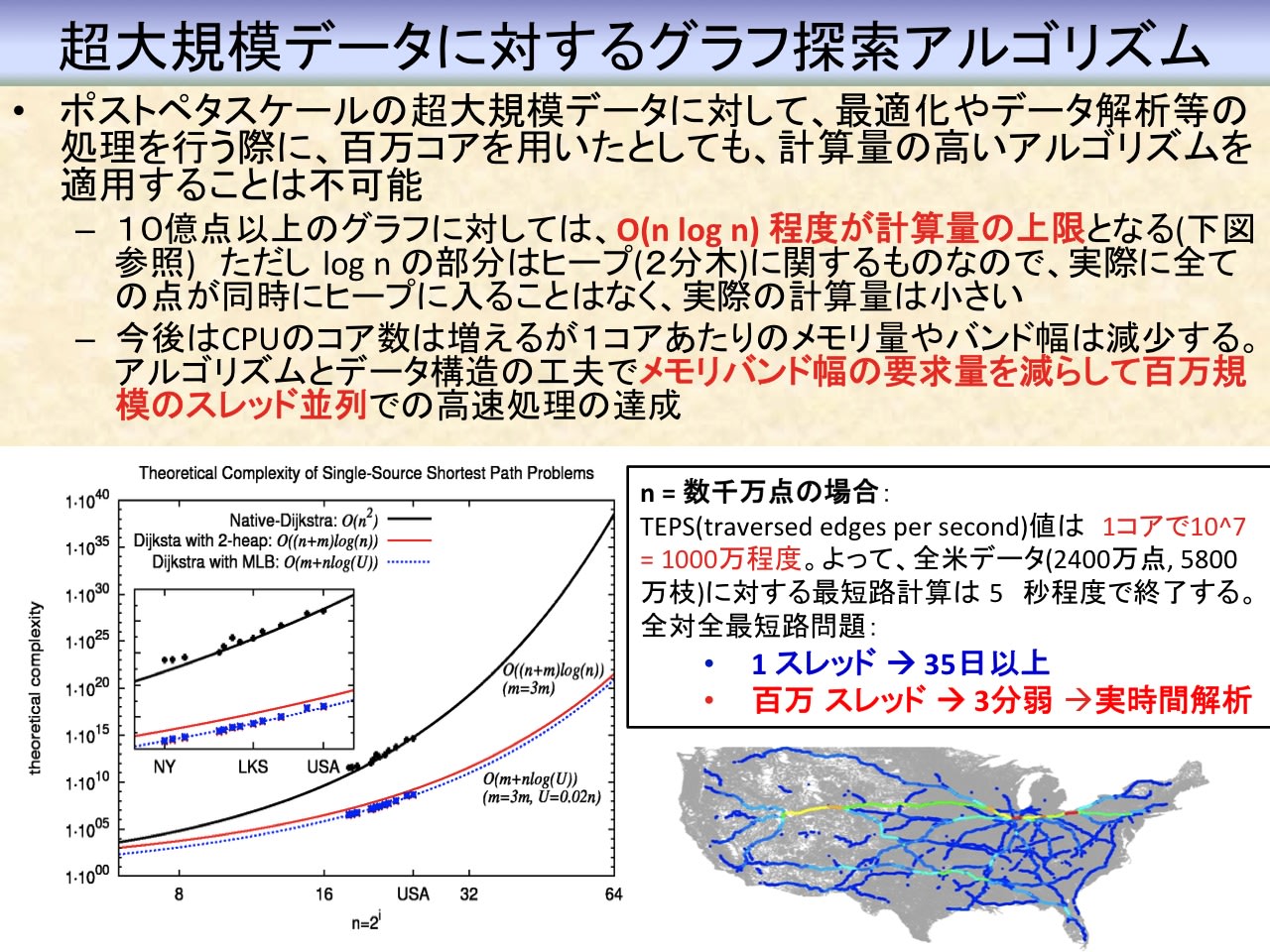
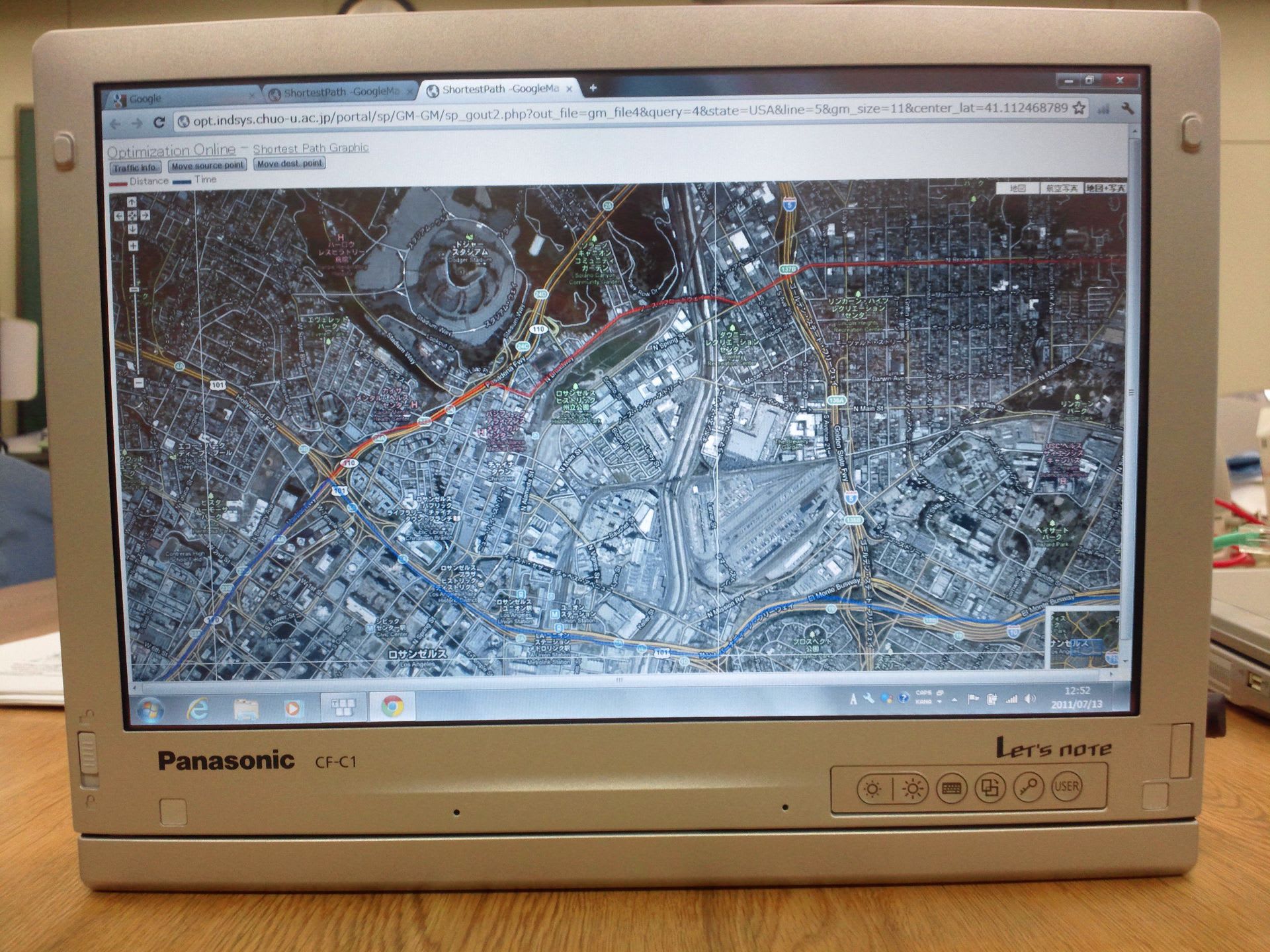
参考:百万スレッドによる、全米データに対する全対全最短路計算と重要性の算出
----------------------------------------------------------------------------------------------
参考
ーー OR 研究ユニット ーー
○1ユニット、2チーム制
A:超大規模データ&モデル化チーム
B:超高速計算チーム
○大学院生や学外の研究協力者も含める
○”超”と名前が付く以上、これままでの研究とは比較にならないほど大きなデータとモデルを扱い、高速に処理を行う
○計算機パワーとマンパワーの両方を重視する
○組み込み系からスーパーコンピュータまで計算機は何でも使う
ーー超大規模グラフ解析プロジェクトーー
○超大規模データを伴う最適化問題に対する高速計算システムの構築と評価
ー グラフ探索(最短路、幅優先探索、重要性計算)、数理計画問題(半正定値計画問題:SDP, 混合整数計画問題 MIP or MINLP 等)
○リアルタイム大規模グラフストリーム処理系及びグラフ最適化ライブラリの開発
○大規模グラフ処理向けオンデマンド階層型データストアの開発
○大規模グラフストリームデータの対話的な閲覧システム
ーーーーーーーーーーーーーーーーーーー
参考:百万スレッドによる、全米データに対する全対全最短路計算と重要性の算出
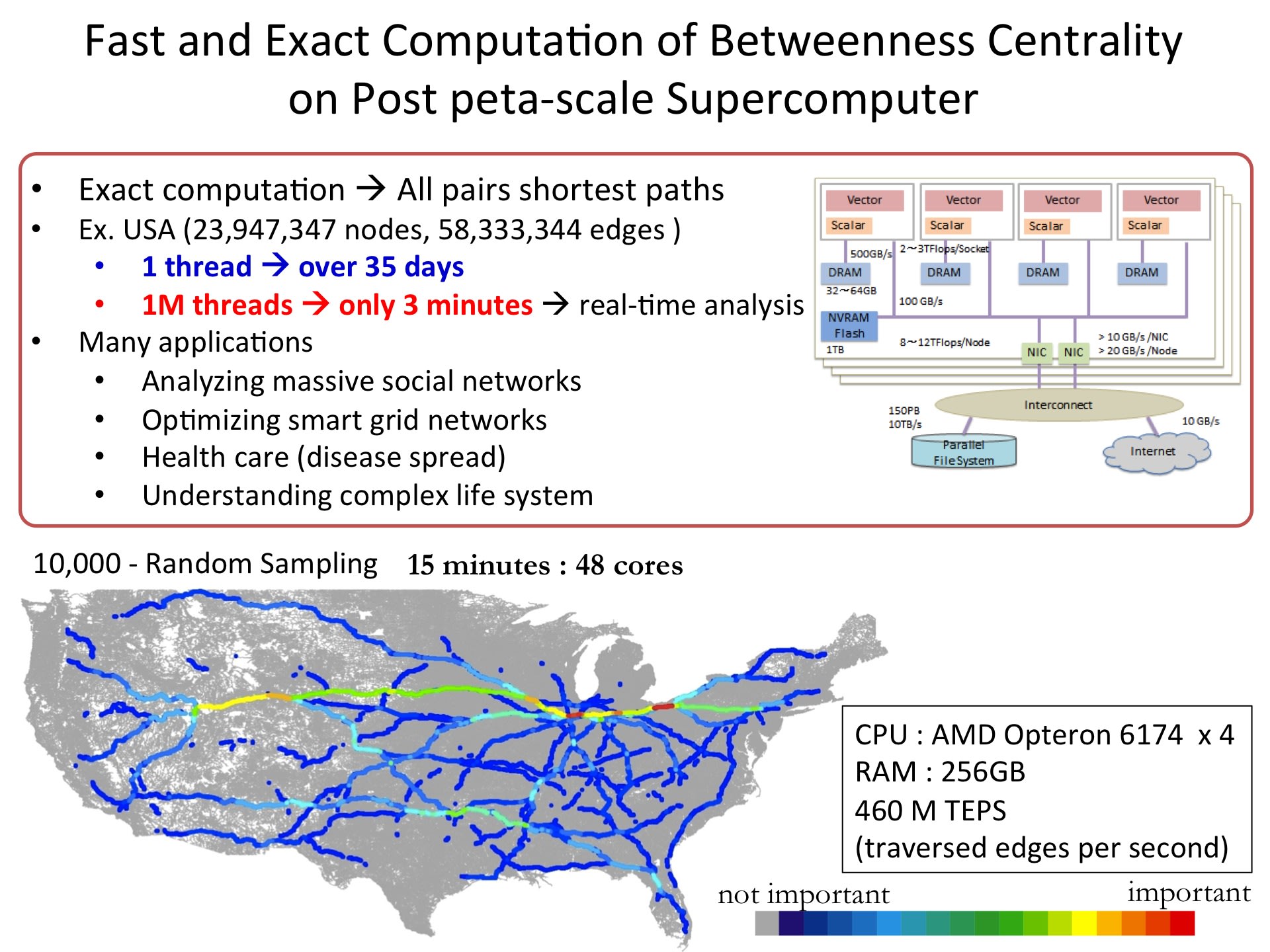
----------------------------------------------------------------------------------------------
参考
ーー OR 研究ユニット ーー
○1ユニット、2チーム制
A:超大規模データ&モデル化チーム
B:超高速計算チーム
○大学院生や学外の研究協力者も含める
○”超”と名前が付く以上、これままでの研究とは比較にならないほど大きなデータとモデルを扱い、高速に処理を行う
○計算機パワーとマンパワーの両方を重視する
○組み込み系からスーパーコンピュータまで計算機は何でも使う