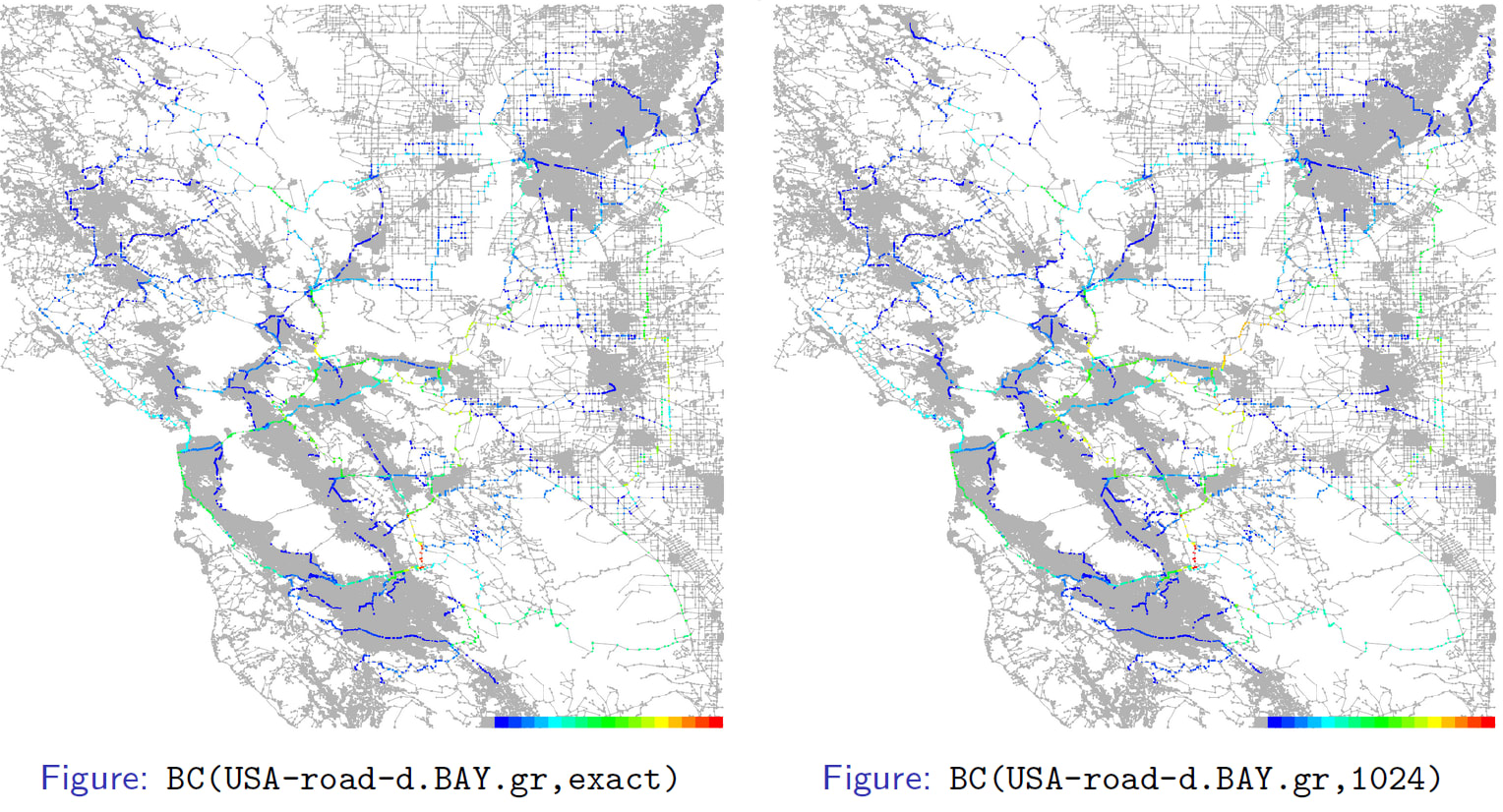
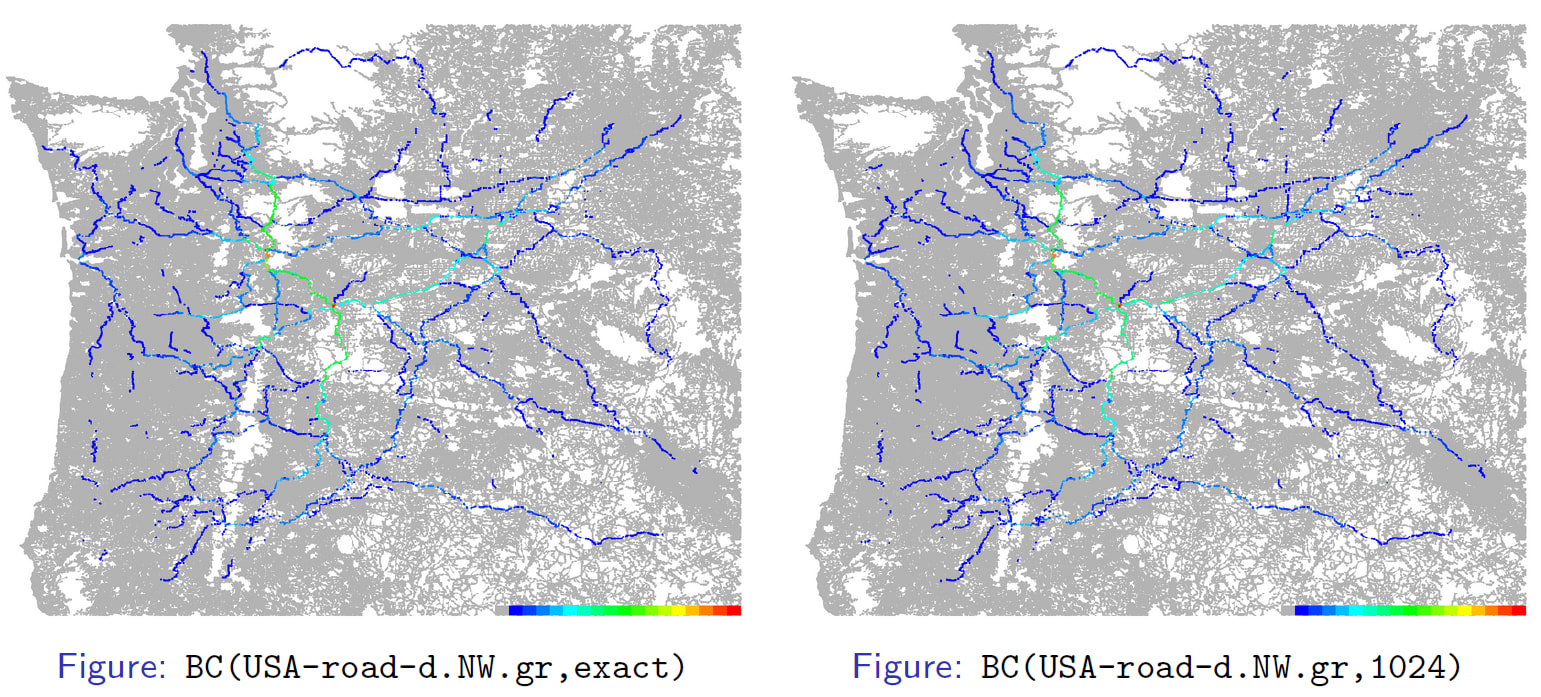
以下のように SCM(Schur Complement Matrix)が疎になるときの計算については、効果が薄いということでこれまでは見送ってきたのだが、様々な変更によって効果も見込めるようになってきた。これからも様々な

○問題 mater-4.dat-s
SDPA 7.3.3β (SCM シングルスレッド) : 50.07秒
SDPA 7.3.3β (SCM マルチスレッド) : 38.57秒
○問題 mater-6.dat-s
SDPA 7.3.3β (SCM シングルスレッド) : 4分12秒
SDPA 7.3.3β (SCM マルチスレッド) : 3分45秒
○サーバ (4 CPU x 6 コア = 24 コア)
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
OS : Fedora 14 for x86_64

○問題 mater-4.dat-s
SDPA 7.3.3β (SCM シングルスレッド) : 50.07秒
SDPA 7.3.3β (SCM マルチスレッド) : 38.57秒
○問題 mater-6.dat-s
SDPA 7.3.3β (SCM シングルスレッド) : 4分12秒
SDPA 7.3.3β (SCM マルチスレッド) : 3分45秒
○サーバ (4 CPU x 6 コア = 24 コア)
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
OS : Fedora 14 for x86_64