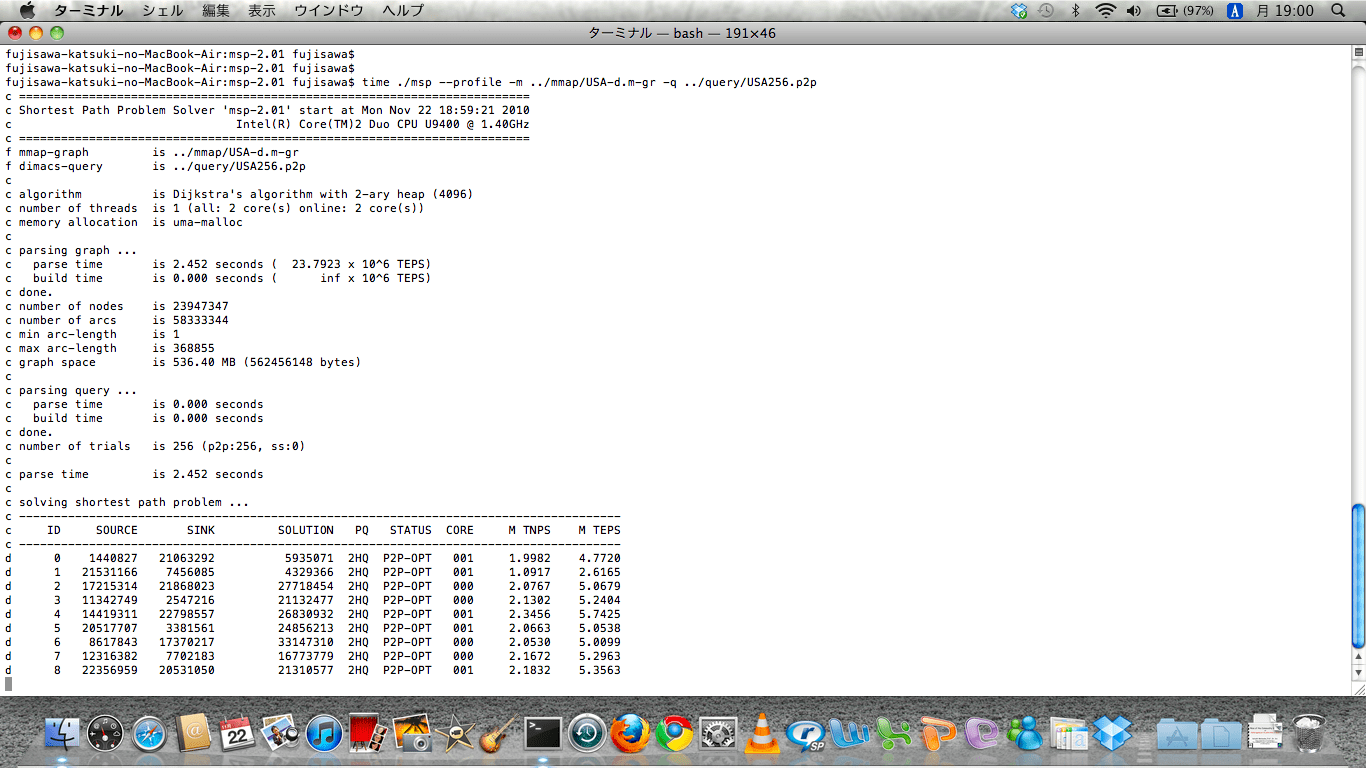
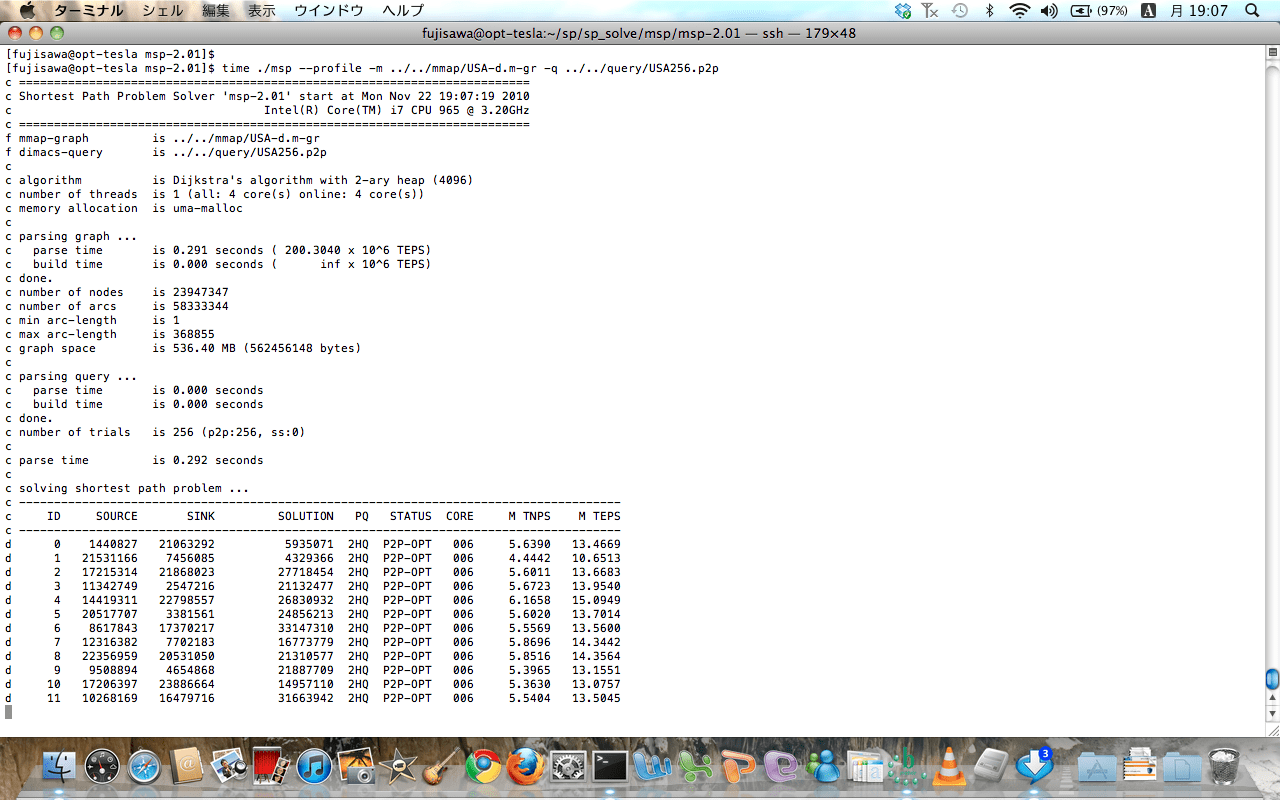
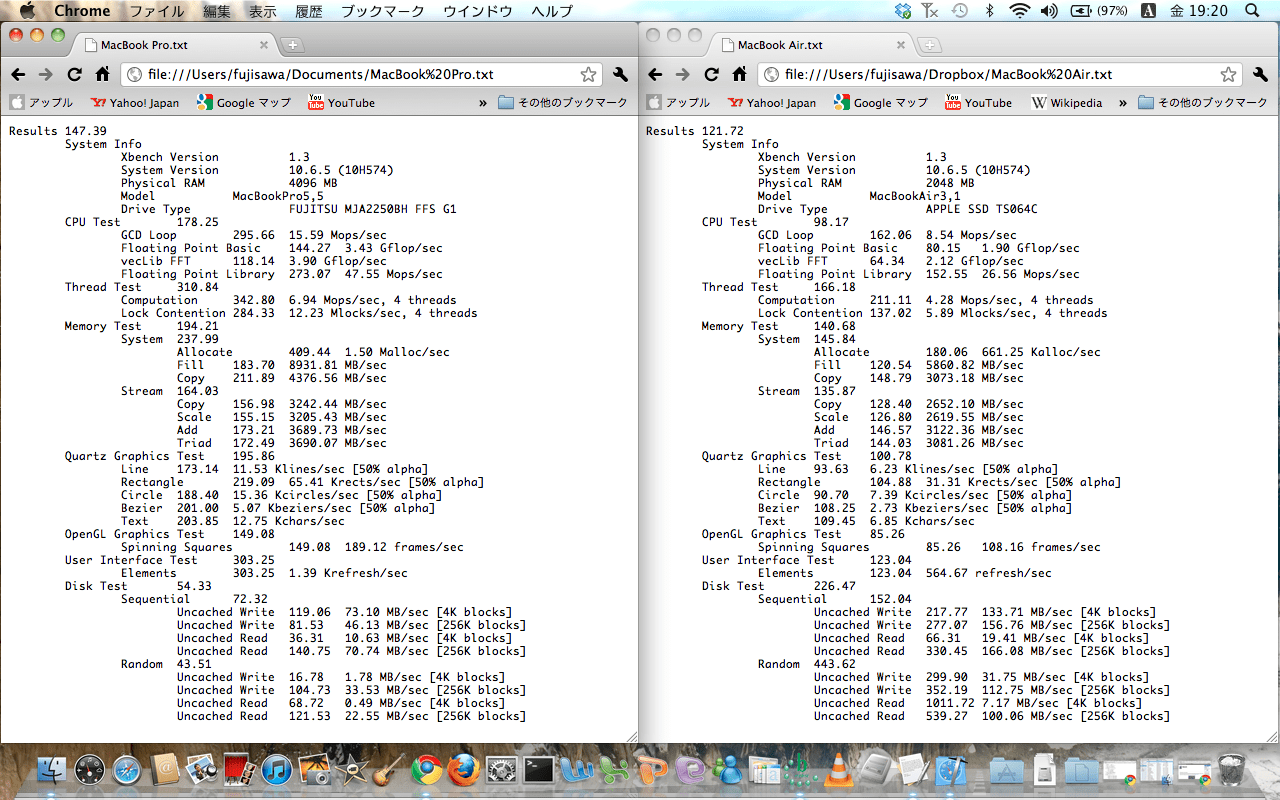
以下の計算サーバが SDPA の計算中に暴走したので、IPMI ツールでログを取得したところ、やはり内部にエラーが発生していた。これは修理が必要になる。
○サーバ (4 CPU x 6 コア = 24 コア)
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
OS : Fedora 13 for x86_64
「IPMIツールを使用したログ取得方法(PowerEdge 第9世代・Windows OS用)」
Severity : normal
Date and Time : Wed Dec 16 16:56:24 2009
Description : System Board SEL: event log sensor for System Board, log cleared was asserted
Severity : critical
Date and Time : Fri May 14 09:22:44 2010
Description : CPU3 Status: processor sensor for CPU3, thermal tripped was asserted
Severity : critical
Date and Time : Wed Nov 24 07:18:09 2010
Description : CPU3 VCORE: voltage sensor for CPU3, state asserted
Severity : critical
Date and Time : Wed Nov 24 07:18:14 2010
Description : System Board PFault Fail Safe: voltage sensor for System Board, state asserted
○サーバ (4 CPU x 6 コア = 24 コア)
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
OS : Fedora 13 for x86_64
「IPMIツールを使用したログ取得方法(PowerEdge 第9世代・Windows OS用)」
Severity : normal
Date and Time : Wed Dec 16 16:56:24 2009
Description : System Board SEL: event log sensor for System Board, log cleared was asserted
Severity : critical
Date and Time : Fri May 14 09:22:44 2010
Description : CPU3 Status: processor sensor for CPU3, thermal tripped was asserted
Severity : critical
Date and Time : Wed Nov 24 07:18:09 2010
Description : CPU3 VCORE: voltage sensor for CPU3, state asserted
Severity : critical
Date and Time : Wed Nov 24 07:18:14 2010
Description : System Board PFault Fail Safe: voltage sensor for System Board, state asserted