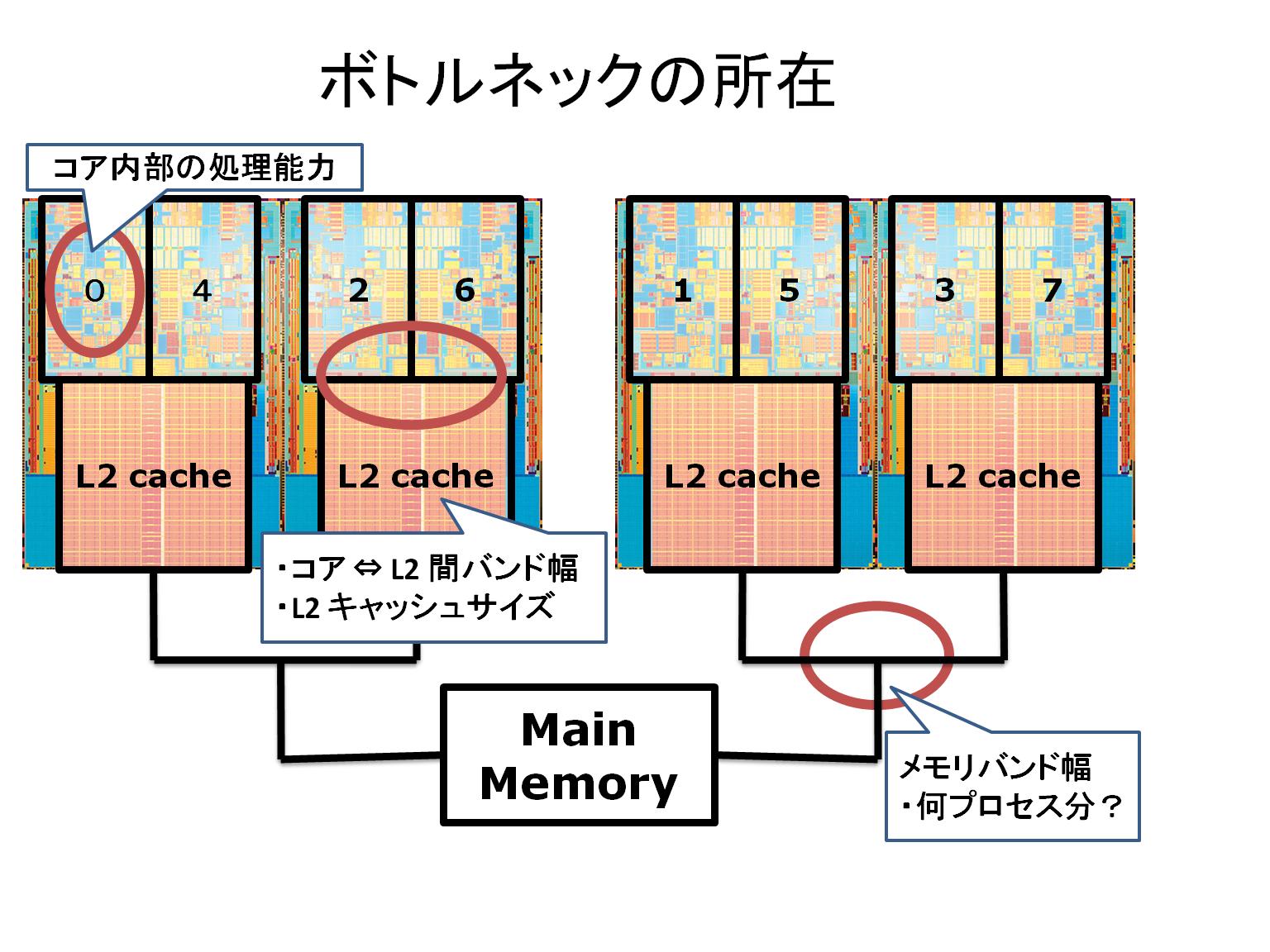
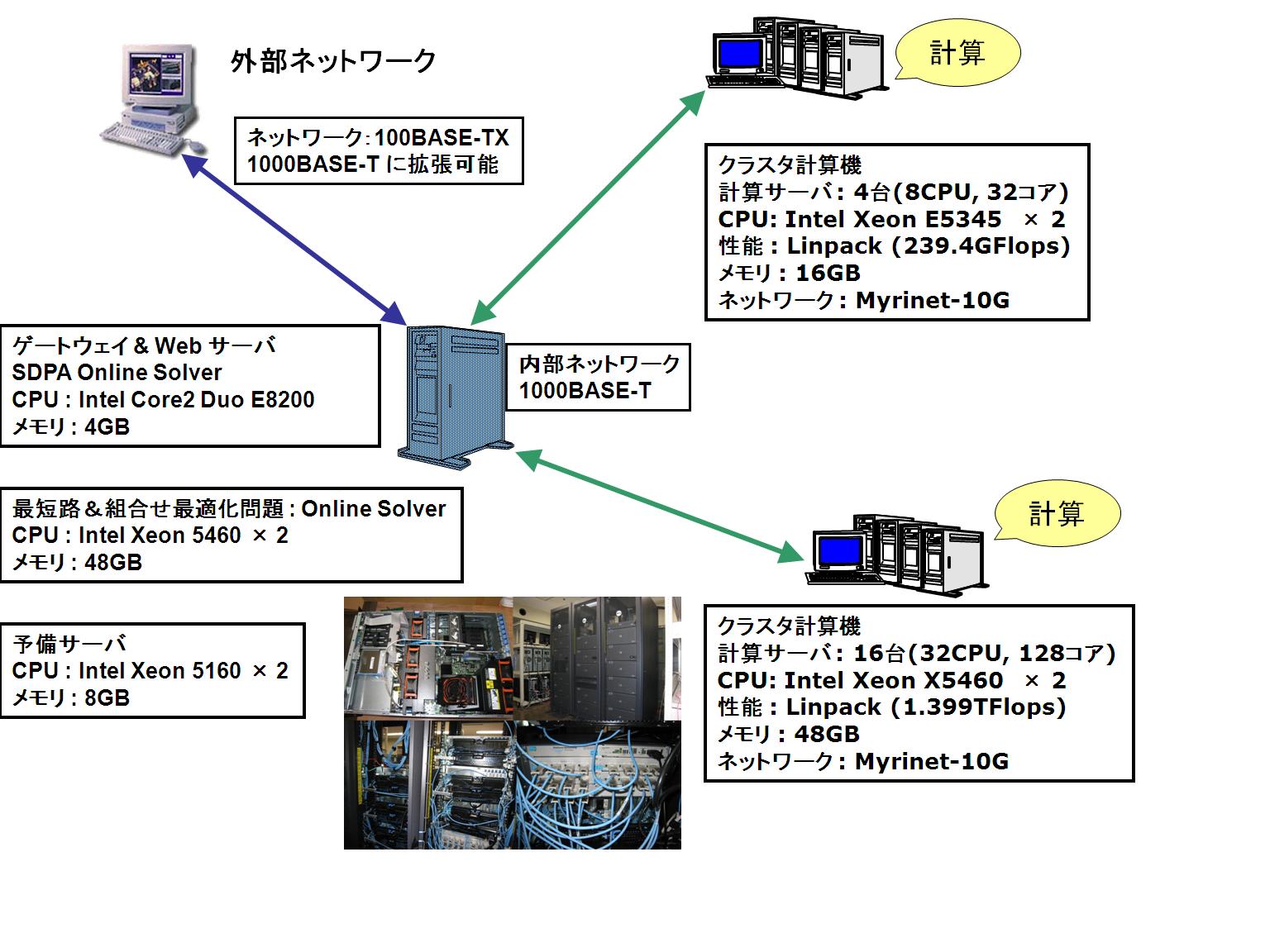
現在の SDPA サーバは自作マシン(しかも適当に?急いで作ったマシン)なので、本当はサーバには向かない(それでも現在まで異常は発生していないが)。よって、SDPA サーバも以下の仕様の PowerEdge SC1435 を購入して交替させる予定である。研究室の新しいマシンはみんな Intel Xeon になってしまったので、一台くらい AMD Opteron (Barcelona)があった方が良い。あと AMD Phenom は演算性能で Intel Core2 に劣り、TDP の値も大きいのだが、メモリバンド幅が大きい(最高で17.1GB/s)のが魅力なので、疎データ時の SDPA の性能評価用に一台購入しても良いだろう。
○ Dell PowerEdge SC1435
プロセッサ
[Quad-Core] AMD Opteron 2360SE (2.5GHz/2MB L3キャッシュ) x 2個
メモリ
16GB (2GBx8/2R/667MHz/SDRAM DIMM ECC)
RAID構成
RAID1 (HDD x2 SAS5iR)
ハードディスク
1TB 7,200 RPM (SATA HDD/3.5インチ) x 2個
ラックレール
1U ツールレスラックキット固定式(デルラック用)
○ Dell PowerEdge SC1435
プロセッサ
[Quad-Core] AMD Opteron 2360SE (2.5GHz/2MB L3キャッシュ) x 2個
メモリ
16GB (2GBx8/2R/667MHz/SDRAM DIMM ECC)
RAID構成
RAID1 (HDD x2 SAS5iR)
ハードディスク
1TB 7,200 RPM (SATA HDD/3.5インチ) x 2個
ラックレール
1U ツールレスラックキット固定式(デルラック用)