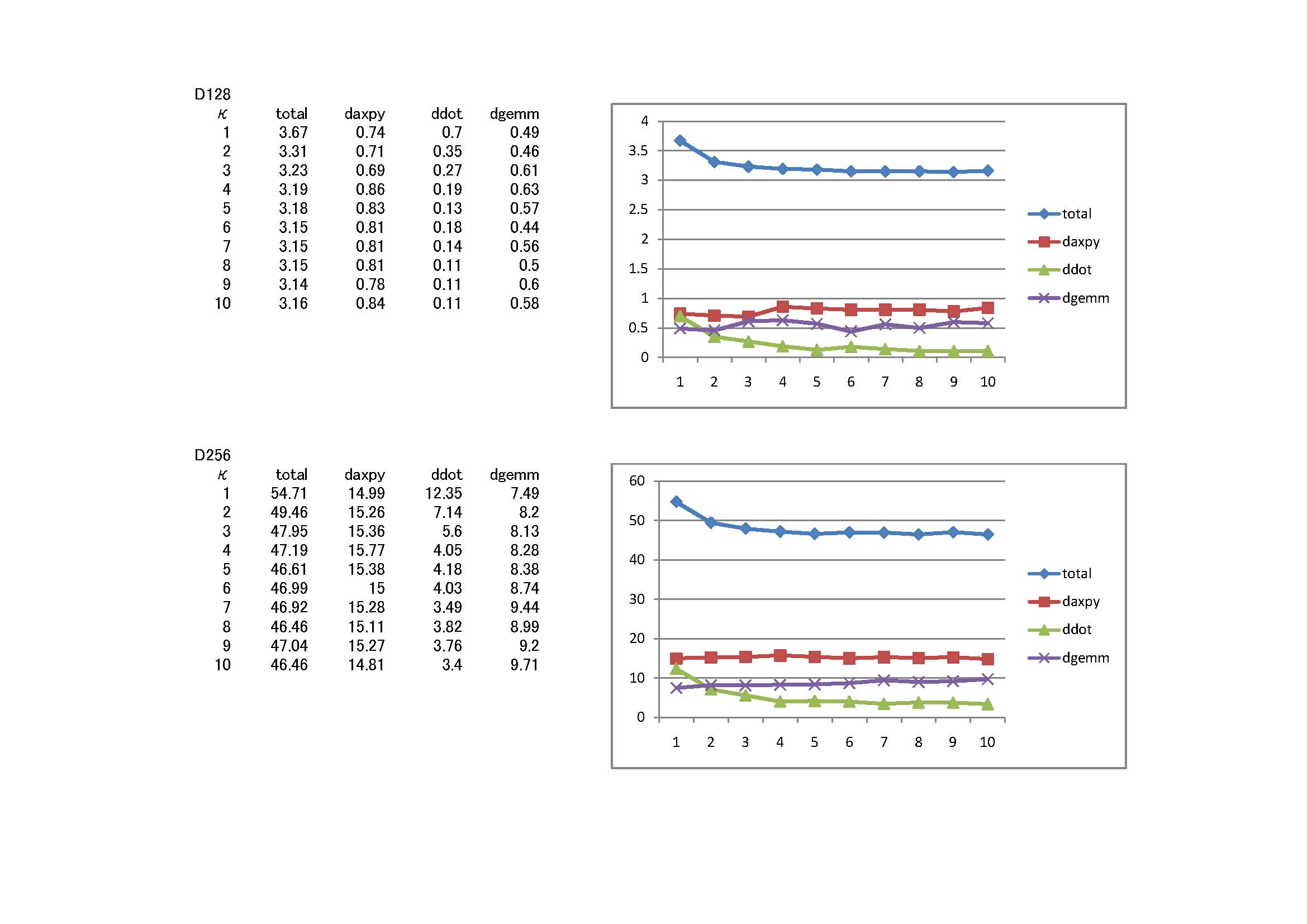
研究の合間?に Power クラスタの Linpack 測定を行った(227.6GFlops)。
HPLinpack benchmark input file
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any)
6 device out (6=stdout,7=stderr,file)
1 # of problems sizes (N)
60000 Ns
1 # of NBs
200 NBs
0 PMAP process mapping (0=Row-,1=Column-major)
1 # of process grids (P x Q)
4 Ps
8 Qs
16.0 threshold
1 # of panel fact
1 PFACTs (0=left, 1=Crout, 2=Right)
1 # of recursive stopping criterium
4 NBMINs (>= 1)
1 # of panels in recursion
2 NDIVs
1 # of recursive panel fact.
1 RFACTs (0=left, 1=Crout, 2=Right)
1 # of broadcast
1 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
1 # of lookahead depth
0 DEPTHs (>=0)
2 SWAP (0=bin-exch,1=long,2=mix)
64 swapping threshold
0 L1 in (0=transposed,1=no-transposed) form
0 U in (0=transposed,1=no-transposed) form
1 Equilibration (0=no,1=yes)
16 memory alignment in double (> 0)
----------------------------------------------------------------------------
- The matrix A is randomly generated for each test.
- The following scaled residual checks will be computed:
1) ||Ax-b||_oo / ( eps * ||A||_1 * N )
2) ||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 )
3) ||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo )
- The relative machine precision (eps) is taken to be 1.110223e-16
- Computational tests pass if scaled residuals are less than 16.0
============================================================================
T/V N NB P Q Time Gflops
----------------------------------------------------------------------------
WR01C2C4 60000 200 4 8 632.75 2.276e+02
----------------------------------------------------------------------------
||Ax-b||_oo / ( eps * ||A||_1 * N ) = 0.0147240 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 ) = 0.0035790 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo ) = 0.0006828 ...... PASSED
============================================================================
Finished 1 tests with the following results:
1 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
----------------------------------------------------------------------------
End of Tests.
============================================================================