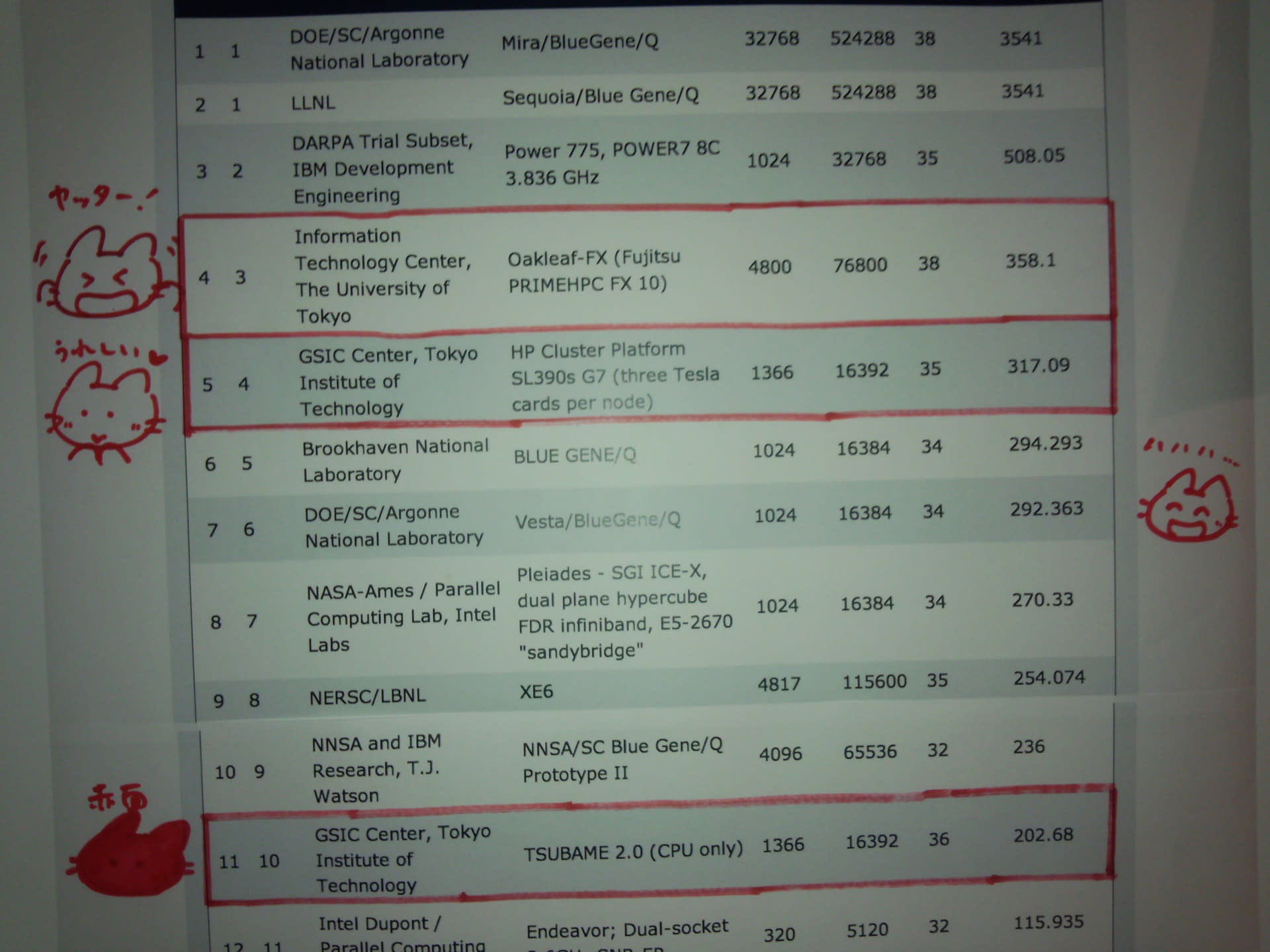
正式に TSUBAME2.0 の1ノードで TEPS 値の測定を行った。以下のように Scale 25, 24コアでの測定結果となっている。3.671GTEPS/kWという値は、このクラスの CPU では相当高めの値になる。
----------------------------------------------------------------------
Parallel Breadth-First Search for Graph500 Benchmark version 3.52
----------------------------------------------------------------------
CPU name is Intel(R) Xeon(R) CPU X5670 @ 2.93GHz
freq / RAM is 2933.374 MHz / 53.17 GB
#cpu, #nodes, #cores is 24 2 12
COMPILER is GCC (GNU C Compiler) version 4.3.4
----------------------------------------------------------------------
scale, edgefactor is 25 16
energy_loop is disable
#threads, #NUMAs is 24 2
mpol_bind is ON(mmap with mbind(MPOL_BIND))
mem_interleave is OFF
switching parameter is 0.000350 (n ~= 1.174405e+04)
queue buffer size is 16384
----------------------------------------------------------------------
SCALE: 25
nvtx: 33554432
edgefactor: 16
terasize: 8.58993459199999983e-03
A: 5.69999999999999951e-01
B: 1.90000000000000002e-01
C: 1.90000000000000002e-01
D: 5.00000000000000444e-02
generation_time: 3.18413941860198975e+01
construction_time: 3.12248620986938477e+01
nbfs: 64
min_time: 1.31865024566650391e-01
firstquartile_time: 1.41672849655151367e-01
median_time: 1.48192524909973145e-01
thirdquartile_time: 1.60642564296722412e-01
max_time: 2.27340793609619141e+00
mean_time: 2.52842102199792862e-01
stddev_time: 3.77578056422843644e-01
min_nedge: 5.36865498000000000e+08
firstquartile_nedge: 5.36865498000000000e+08
median_nedge: 5.36865498000000000e+08
thirdquartile_nedge: 5.36865498000000000e+08
max_nedge: 5.36865498000000000e+08
mean_nedge: 5.36865498000000000e+08
stddev_nedge: 0.00000000000000000e+00
min_TEPS: 2.36150094083811790e+08
firstquartile_TEPS: 3.40998940083618927e+09
median_TEPS: 3.67106491095643044e+09
thirdquartile_TEPS: 3.79863995016410017e+09
max_TEPS: 4.07132596201538277e+09
harmonic_mean_TEPS: 2.12332318600869393e+09
harmonic_stddev_TEPS: 3.99487487817118108e+08
----------------------------------------------------------------------
Parallel Breadth-First Search for Graph500 Benchmark version 3.52
----------------------------------------------------------------------
CPU name is Intel(R) Xeon(R) CPU X5670 @ 2.93GHz
freq / RAM is 2933.374 MHz / 53.17 GB
#cpu, #nodes, #cores is 24 2 12
COMPILER is GCC (GNU C Compiler) version 4.3.4
----------------------------------------------------------------------
scale, edgefactor is 25 16
energy_loop is disable
#threads, #NUMAs is 24 2
mpol_bind is ON(mmap with mbind(MPOL_BIND))
mem_interleave is OFF
switching parameter is 0.000350 (n ~= 1.174405e+04)
queue buffer size is 16384
----------------------------------------------------------------------
SCALE: 25
nvtx: 33554432
edgefactor: 16
terasize: 8.58993459199999983e-03
A: 5.69999999999999951e-01
B: 1.90000000000000002e-01
C: 1.90000000000000002e-01
D: 5.00000000000000444e-02
generation_time: 3.18413941860198975e+01
construction_time: 3.12248620986938477e+01
nbfs: 64
min_time: 1.31865024566650391e-01
firstquartile_time: 1.41672849655151367e-01
median_time: 1.48192524909973145e-01
thirdquartile_time: 1.60642564296722412e-01
max_time: 2.27340793609619141e+00
mean_time: 2.52842102199792862e-01
stddev_time: 3.77578056422843644e-01
min_nedge: 5.36865498000000000e+08
firstquartile_nedge: 5.36865498000000000e+08
median_nedge: 5.36865498000000000e+08
thirdquartile_nedge: 5.36865498000000000e+08
max_nedge: 5.36865498000000000e+08
mean_nedge: 5.36865498000000000e+08
stddev_nedge: 0.00000000000000000e+00
min_TEPS: 2.36150094083811790e+08
firstquartile_TEPS: 3.40998940083618927e+09
median_TEPS: 3.67106491095643044e+09
thirdquartile_TEPS: 3.79863995016410017e+09
max_TEPS: 4.07132596201538277e+09
harmonic_mean_TEPS: 2.12332318600869393e+09
harmonic_stddev_TEPS: 3.99487487817118108e+08