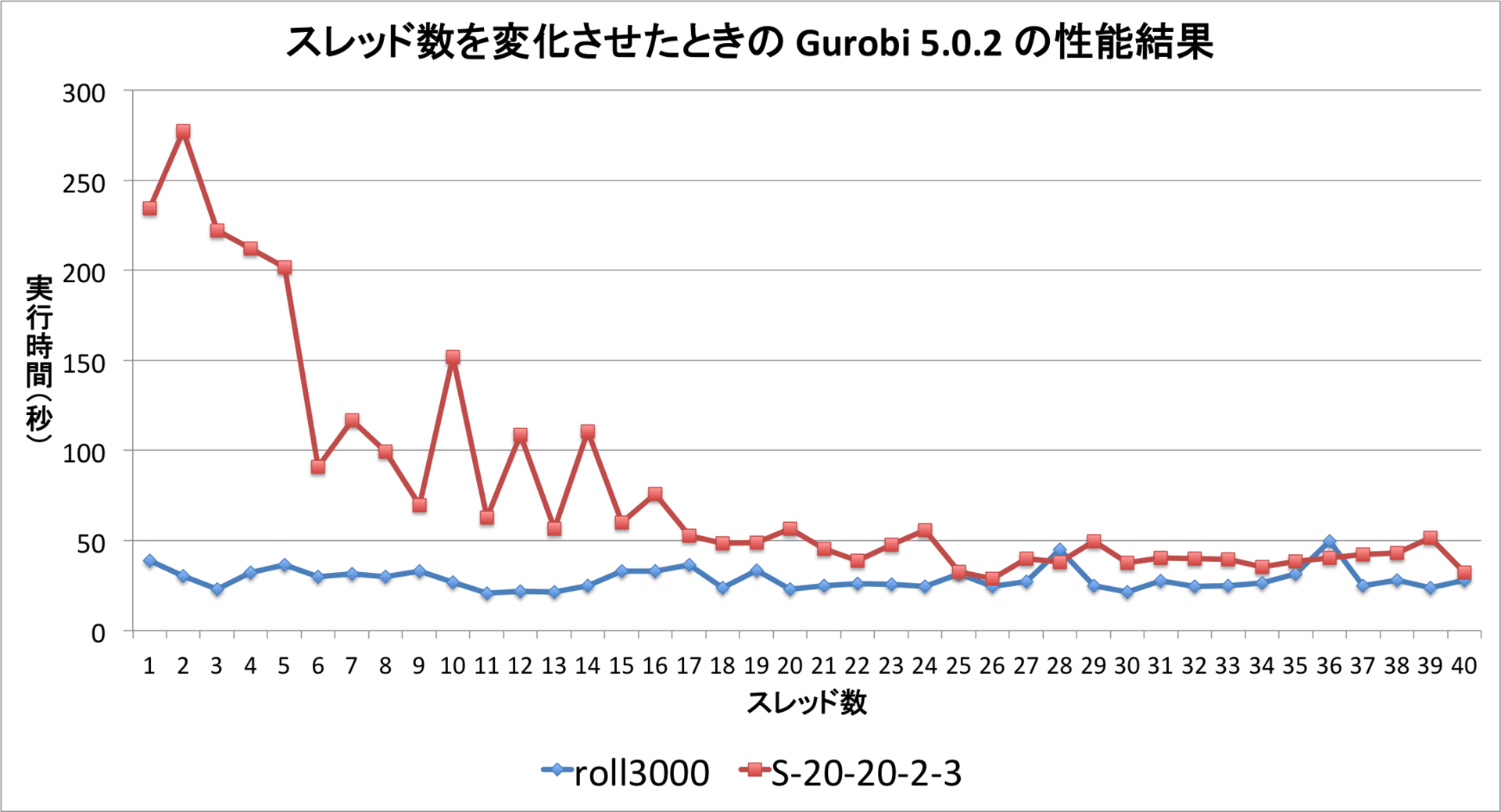
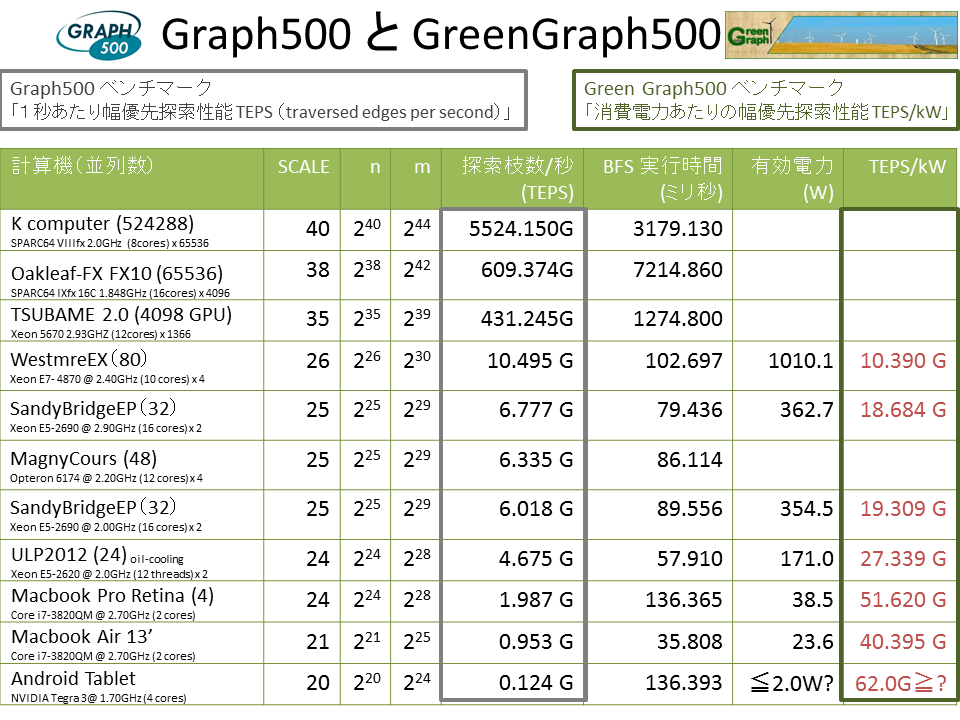
以下の計算サーバでの MIPLIB2010 を用いた Gurobi 5.0.2 と CPLEX 12.5 の比較実験結果について。
○計算サーバ (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4
Memory : 256GB (16 x 16GB / 1066MHz)
OS : Fedora 17 for x86_64
-----------------------------------+---------------+---------------+
Name | CPLEX | Gurobi |
-----------------------------------+---------------+---------------+
30n20b8 40 12
acc-tight5 14 29
aflow40b 85 56
air04 7 24
app1-2 72 133
ash608gpia-3col 17 38
bab5 664 162
beasleyC3 14 26
biella1 146 288
bienst2 28 5
binkar10_1 3 4
bley_xl1 26 18
bnatt350 470 1312
core2536-691 53 72
cov1075 3 6
csched010 326 872
danoint 235 582
dfn-gwin-UUM 17 19
eil33-2 14 124
eilB101 15 83
enlight13 2143 3
enlight14 6 2
ex9 7 12
glass4 79 18
gmu-35-40 468 126
iis-100-0-cov 150 323
iis-bupa-cov 2038 745
iis-pima-cov 213 203
lectsched-4-obj 6 3
m100n500k4r1 timeout timeout
macrophage 221 166
map18 190 72
map20 121 54
mcsched 8 26
mik-250-1-100-1 5 7
mine-166-5 27 27
mine-90-10 74 1061
msc98-ip 1492 436
mspp16 1756 1123
mzzv11 24 30
n3div36 timeout 812
n3seq24 timeout 457
n4-3 96 206
neos-1109824 16 131
neos-1337307 timeout 145
neos-1396125 8 9
neos13 100 47
neos-1601936 143 187
neos18 10 35
neos-476283 146 192
neos-686190 10 29
neos-849702 17 154
neos-916792 116 160
neos-934278 485 80
net12 153 77
netdiversion 204 212
newdano 867 257
noswot 46 9
ns1208400 156 179
ns1688347 12 27
ns1758913 92 154
ns1766074 30 16
ns1830653 38 116
opm2-z7-s2 142 101
pg5_34 94 53
pigeon-10 165 42
pw-myciel4 7 164
qiu 4 8
rail507 107 283
ran16x16 28 13
reblock67 51 285
rmatr100-p10 11 11
rmatr100-p5 31 20
rmine6 241 198
rocII-4-11 47 137
rococoC10-001000 64 268
roll3000 53 31
satellites1-25 60 260
sp98ic 286 195
sp98ir 8 29
tanglegram1 23 11
tanglegram2 2 1
timtab1 120 93
triptim1 85 128
unitcal_7 134 243
vpphard timeout 843
zib54-UUE 500 265
-----------------------------------+---------------+---------------+
solved/stopped/failed | 82/5/0 | 86/1/0 |
timelimit [sec] | 3600 | 3600 |
-----------------------------------+---------------+---------------+
○計算サーバ (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4
Memory : 256GB (16 x 16GB / 1066MHz)
OS : Fedora 17 for x86_64
-----------------------------------+---------------+---------------+
Name | CPLEX | Gurobi |
-----------------------------------+---------------+---------------+
30n20b8 40 12
acc-tight5 14 29
aflow40b 85 56
air04 7 24
app1-2 72 133
ash608gpia-3col 17 38
bab5 664 162
beasleyC3 14 26
biella1 146 288
bienst2 28 5
binkar10_1 3 4
bley_xl1 26 18
bnatt350 470 1312
core2536-691 53 72
cov1075 3 6
csched010 326 872
danoint 235 582
dfn-gwin-UUM 17 19
eil33-2 14 124
eilB101 15 83
enlight13 2143 3
enlight14 6 2
ex9 7 12
glass4 79 18
gmu-35-40 468 126
iis-100-0-cov 150 323
iis-bupa-cov 2038 745
iis-pima-cov 213 203
lectsched-4-obj 6 3
m100n500k4r1 timeout timeout
macrophage 221 166
map18 190 72
map20 121 54
mcsched 8 26
mik-250-1-100-1 5 7
mine-166-5 27 27
mine-90-10 74 1061
msc98-ip 1492 436
mspp16 1756 1123
mzzv11 24 30
n3div36 timeout 812
n3seq24 timeout 457
n4-3 96 206
neos-1109824 16 131
neos-1337307 timeout 145
neos-1396125 8 9
neos13 100 47
neos-1601936 143 187
neos18 10 35
neos-476283 146 192
neos-686190 10 29
neos-849702 17 154
neos-916792 116 160
neos-934278 485 80
net12 153 77
netdiversion 204 212
newdano 867 257
noswot 46 9
ns1208400 156 179
ns1688347 12 27
ns1758913 92 154
ns1766074 30 16
ns1830653 38 116
opm2-z7-s2 142 101
pg5_34 94 53
pigeon-10 165 42
pw-myciel4 7 164
qiu 4 8
rail507 107 283
ran16x16 28 13
reblock67 51 285
rmatr100-p10 11 11
rmatr100-p5 31 20
rmine6 241 198
rocII-4-11 47 137
rococoC10-001000 64 268
roll3000 53 31
satellites1-25 60 260
sp98ic 286 195
sp98ir 8 29
tanglegram1 23 11
tanglegram2 2 1
timtab1 120 93
triptim1 85 128
unitcal_7 134 243
vpphard timeout 843
zib54-UUE 500 265
-----------------------------------+---------------+---------------+
solved/stopped/failed | 82/5/0 | 86/1/0 |
timelimit [sec] | 3600 | 3600 |
-----------------------------------+---------------+---------------+