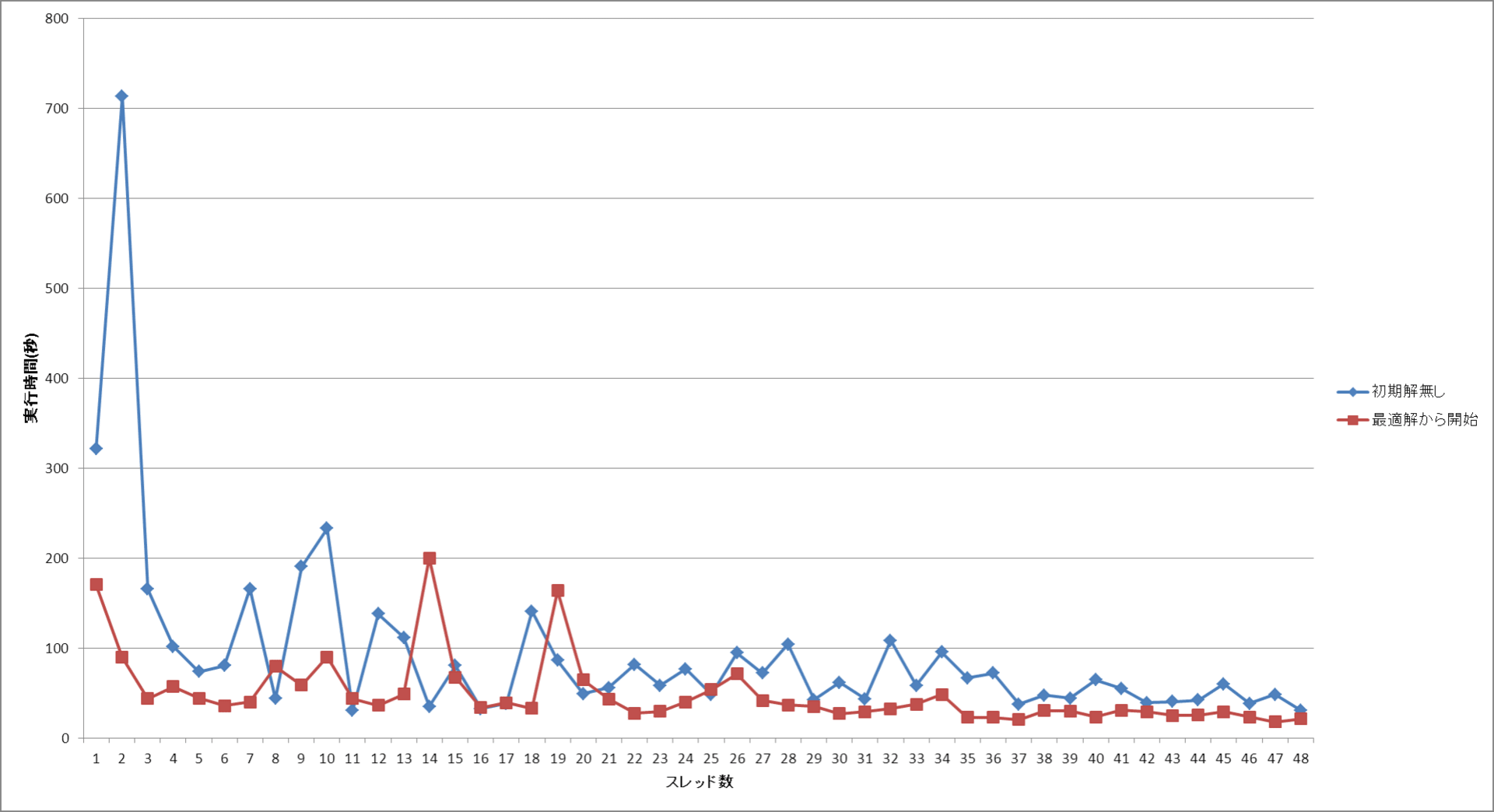
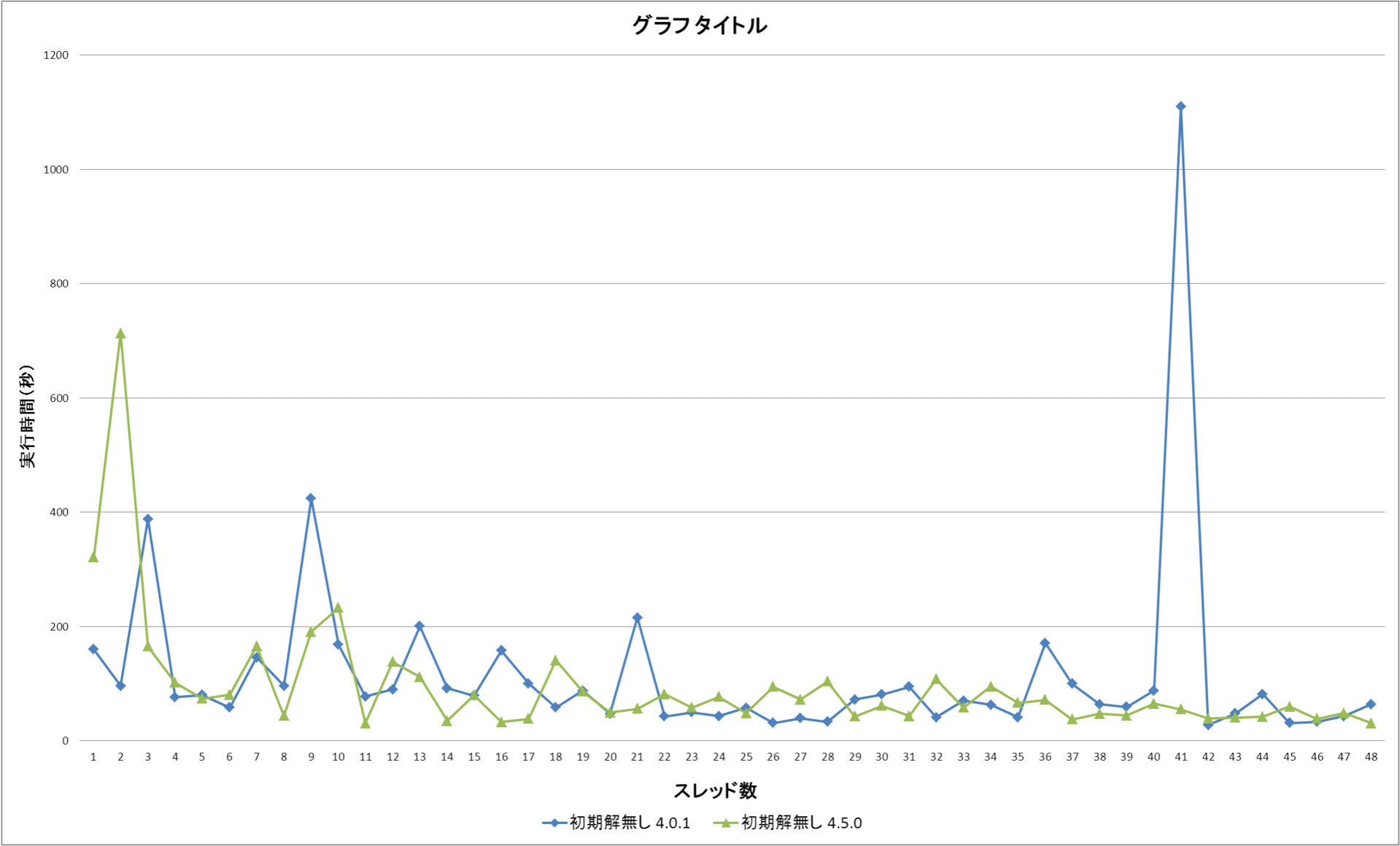
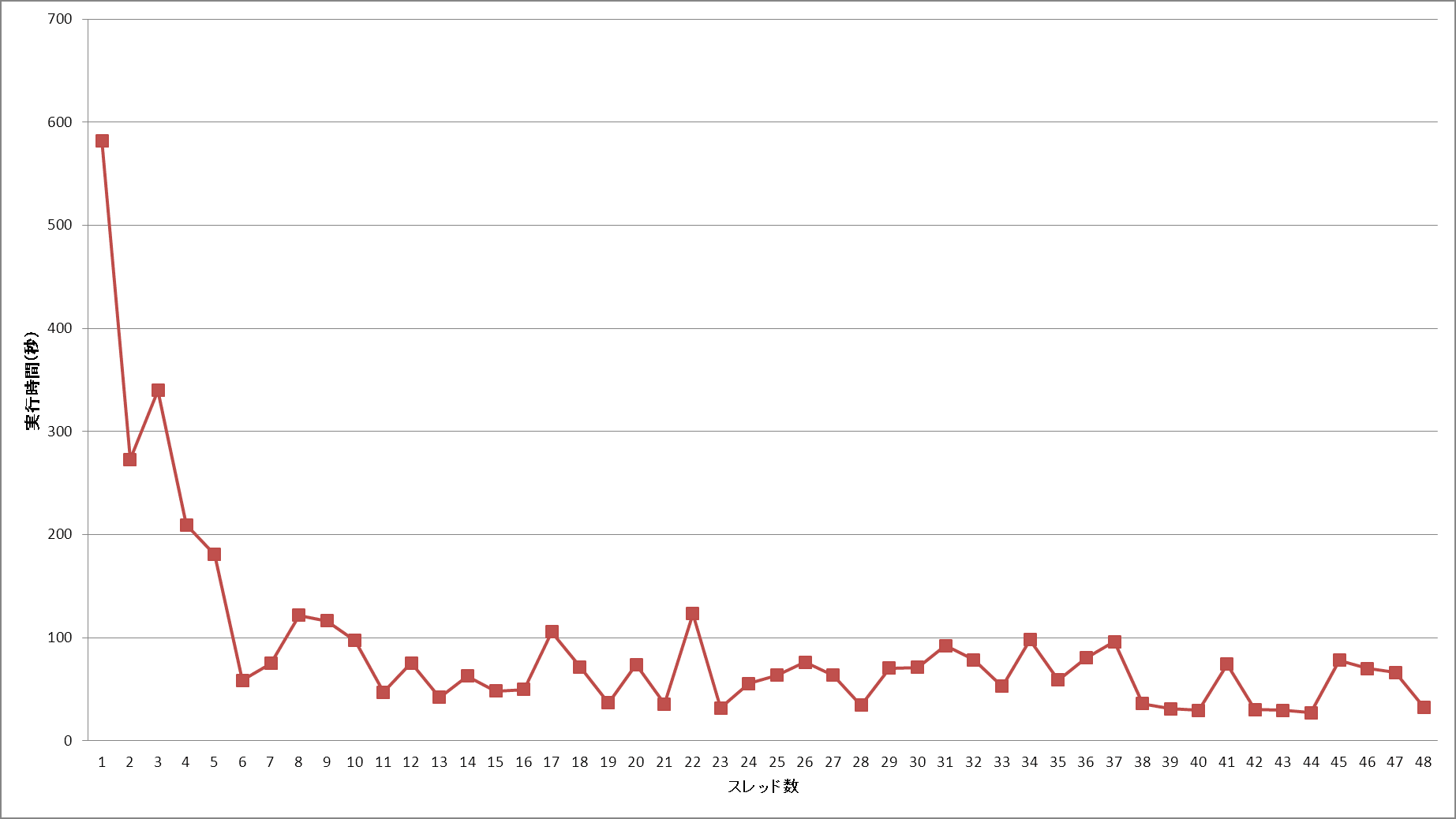
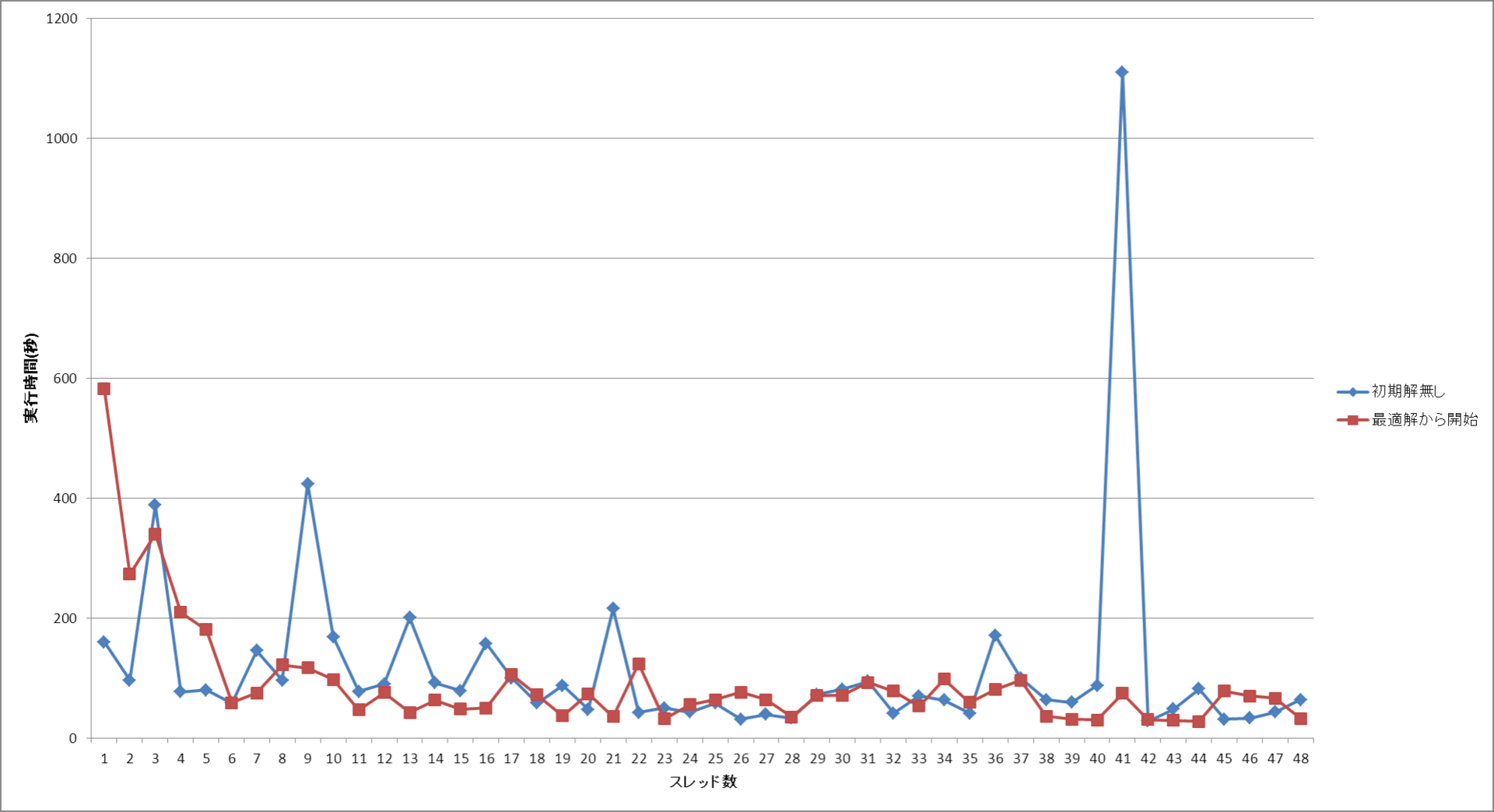
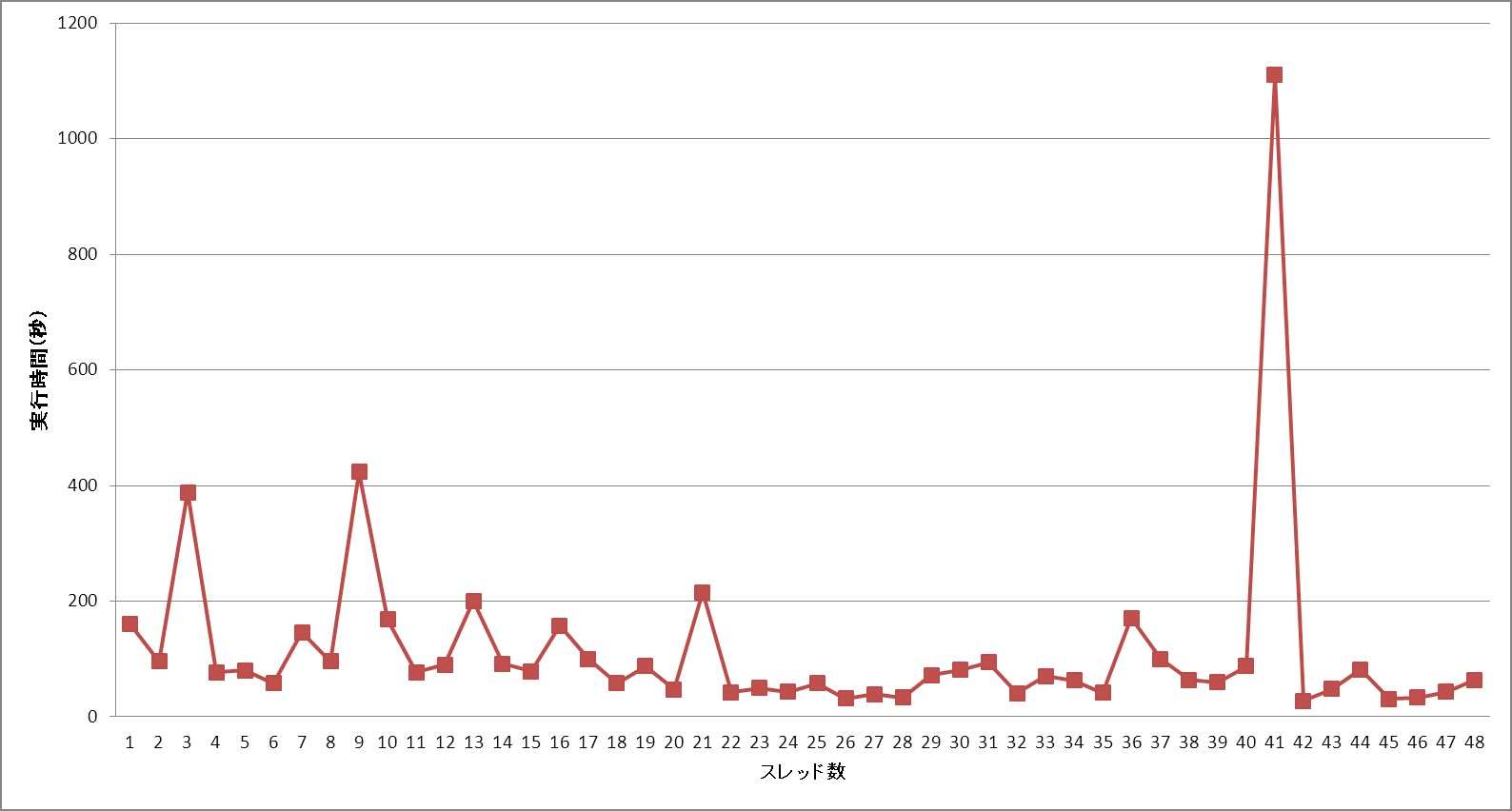
MPI 並列で SDP と言えば PDSDP が実は一番初めに出来たソフトウェアである。PDSDP と PCSDP は開発者がすでに民間企業に移ってしまって後継者?がいないという状況になっている。
○問題1:Be.1S.SV.pqgt1t2p.dat-s
SDPARA 7.3.3 : 173.45秒
SDPARA 7.3.2 : 923.40秒
PCSDP 1.0 : 1067.06秒
PDSDP 5.8 : 948.08秒(精度は良くない)
○問題2:nug12_r2.dat-s
SDPARA 7.3.3 : 29.69秒
SDPARA 7.3.2 : 33.29秒
PCSDP 1.0 : 139.53秒
PDSDP 5.8 : 662.48秒(精度は良くない)
○問題3:CH4.1A1.STO6G.noncore.pqg.dat-s
SDPARA 7.3.3 : 221.40秒
SDPARA 7.3.2 : 272.93秒
PCSDP 1.0 : 527.16秒
PDSDP 5.8 : 540.03秒
○新クラスタ計算機
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.5 for x86_64
○問題1:Be.1S.SV.pqgt1t2p.dat-s
SDPARA 7.3.3 : 173.45秒
SDPARA 7.3.2 : 923.40秒
PCSDP 1.0 : 1067.06秒
PDSDP 5.8 : 948.08秒(精度は良くない)
○問題2:nug12_r2.dat-s
SDPARA 7.3.3 : 29.69秒
SDPARA 7.3.2 : 33.29秒
PCSDP 1.0 : 139.53秒
PDSDP 5.8 : 662.48秒(精度は良くない)
○問題3:CH4.1A1.STO6G.noncore.pqg.dat-s
SDPARA 7.3.3 : 221.40秒
SDPARA 7.3.2 : 272.93秒
PCSDP 1.0 : 527.16秒
PDSDP 5.8 : 540.03秒
○新クラスタ計算機
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.5 for x86_64