「e-サイエンスに向けた革新的アルゴリズム基盤」シンポジウムのプログラムが確定しました。参加には事前申し込み等は必要ありませんが、参加予定の方はご一報いただけると幸いです。
日時:9月4日(日曜日)13時30分から17時00分まで
場所:公立はこだて未来大学(http://www.fun.ac.jp/)研究棟 R791室
プログラム(確定版)
1. 13:30~13:55 「計画概要」 加藤直樹(京都大学)
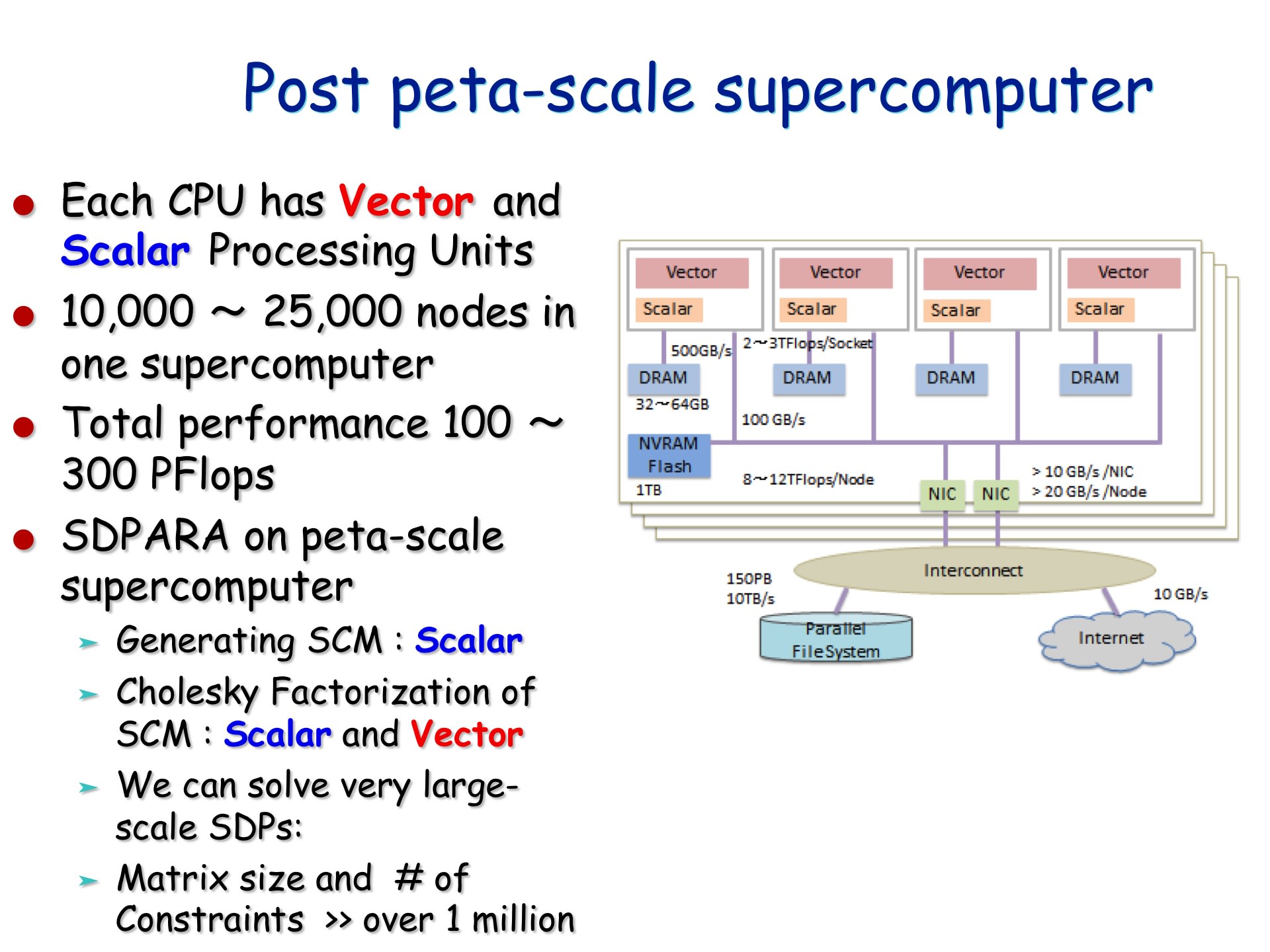
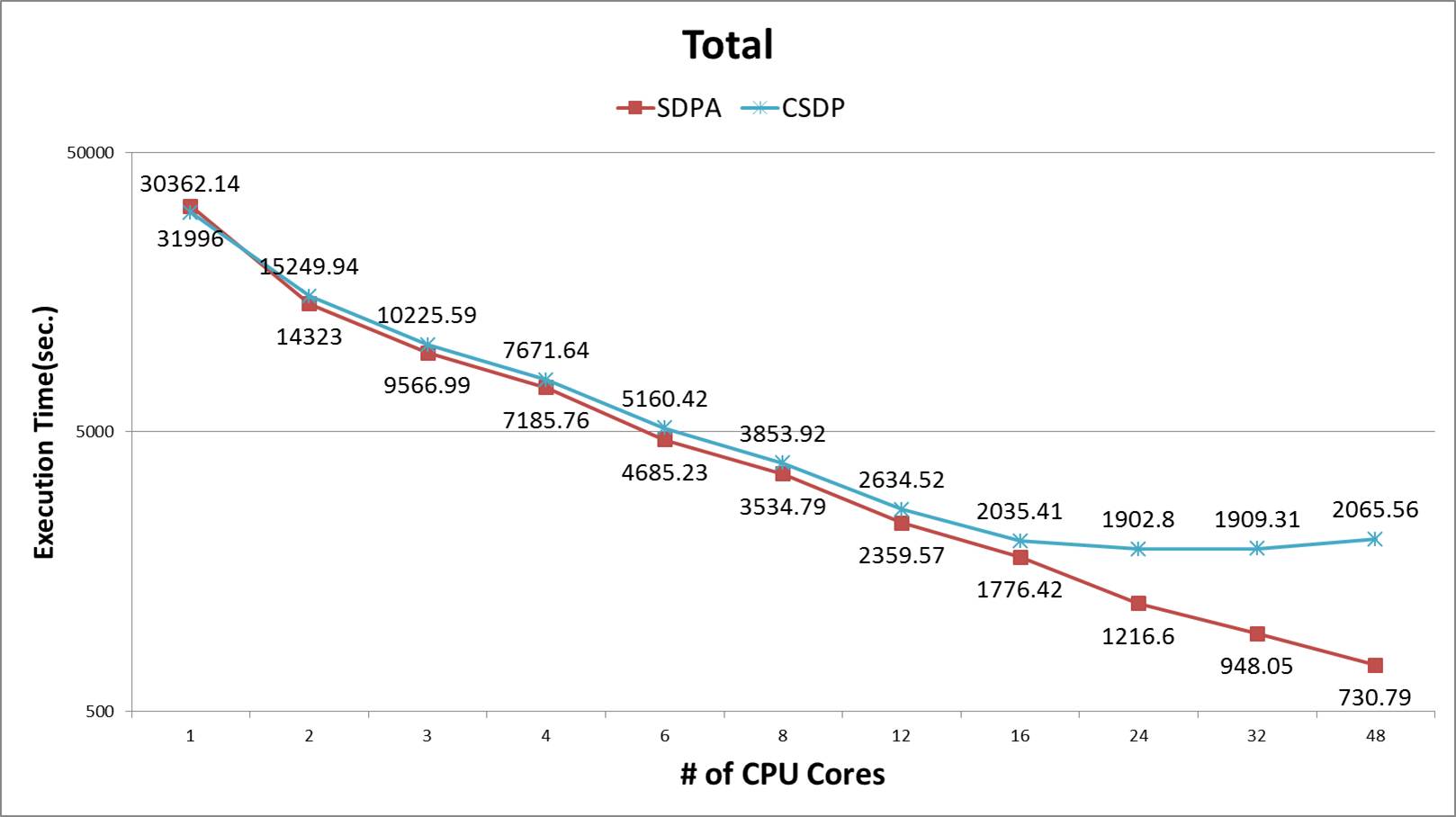
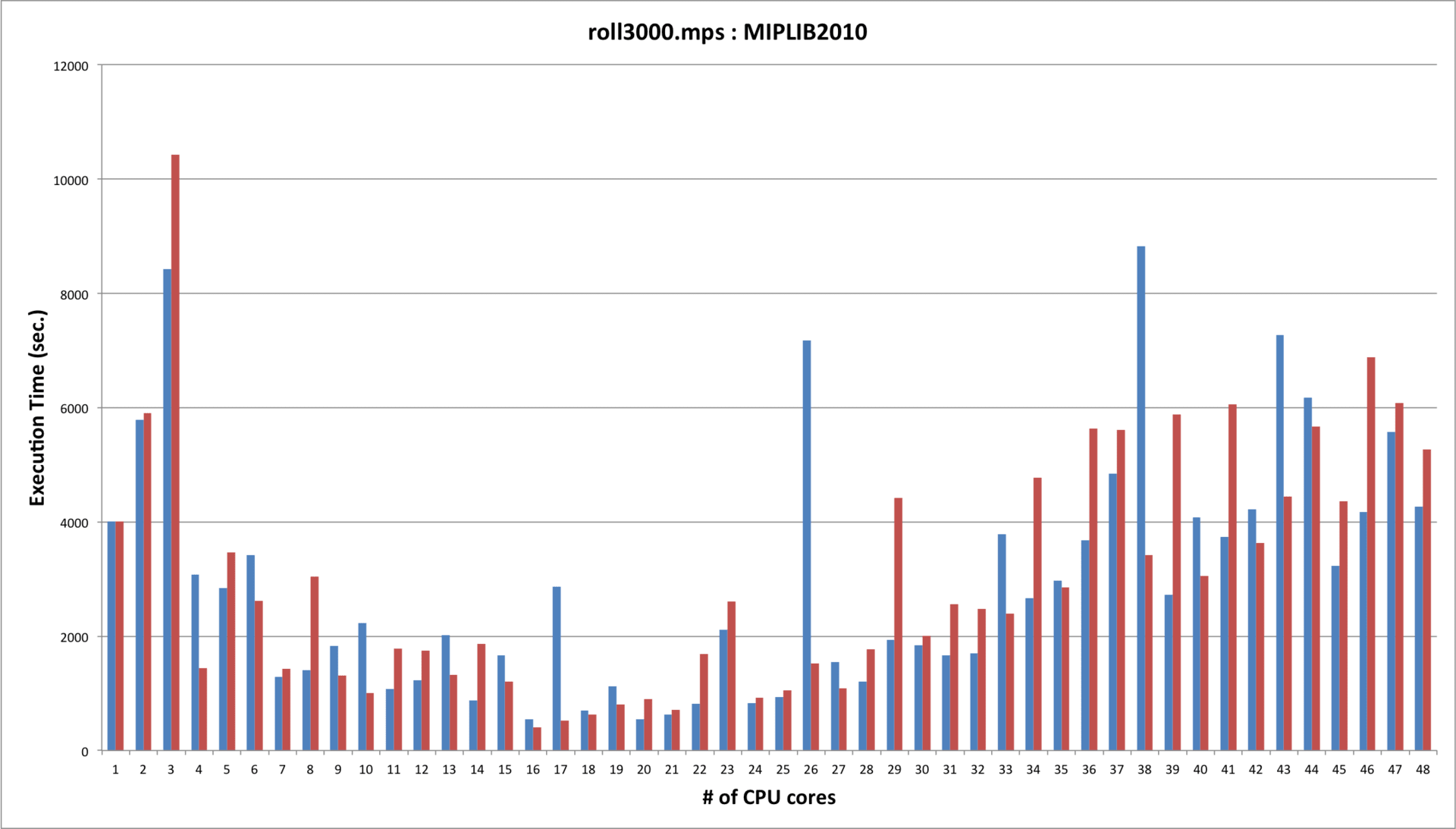
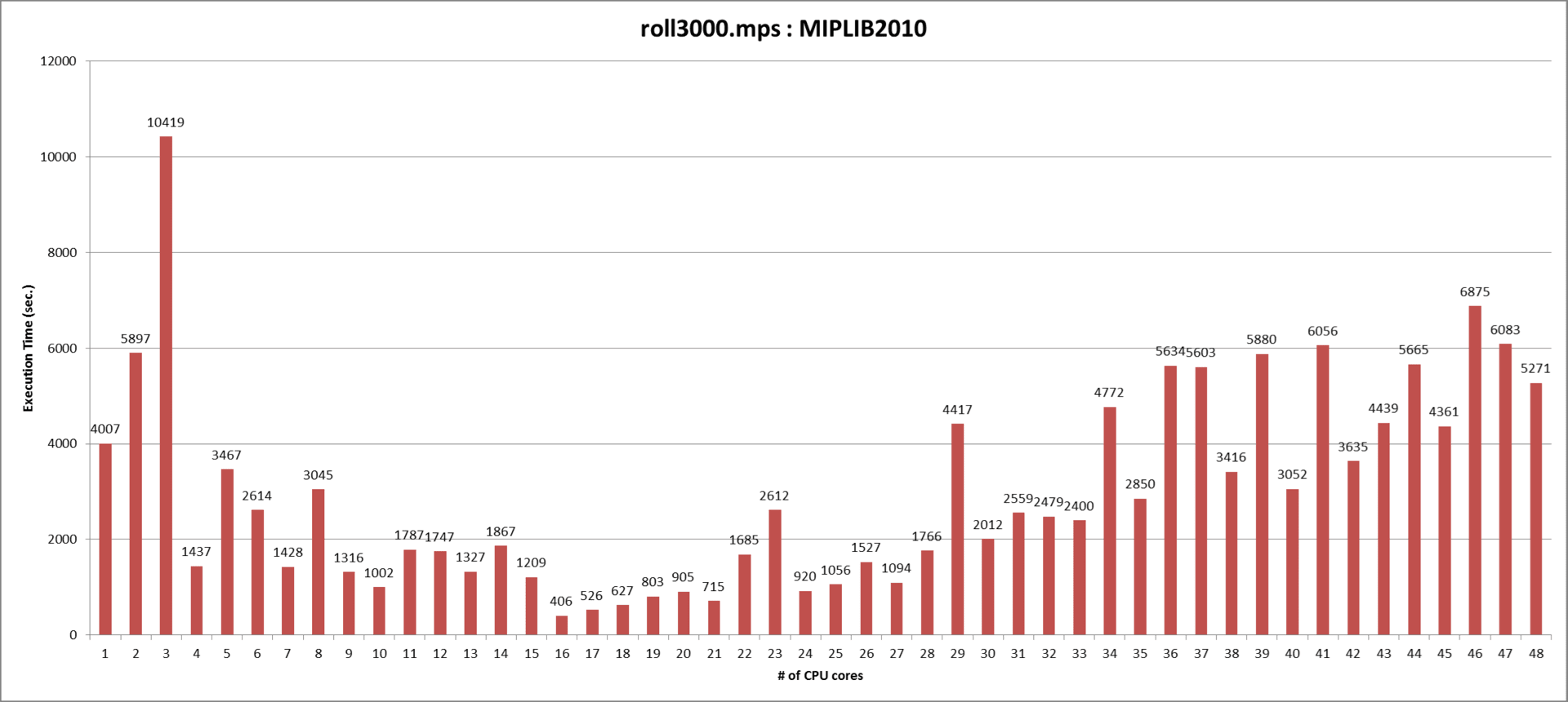
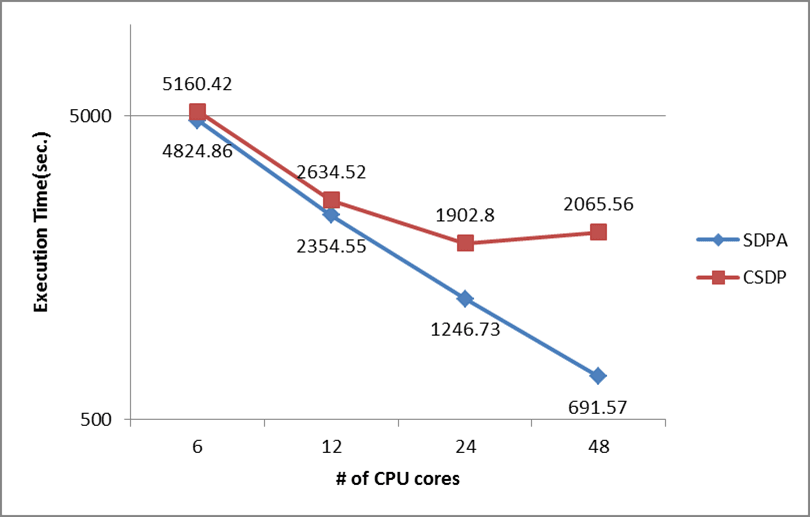
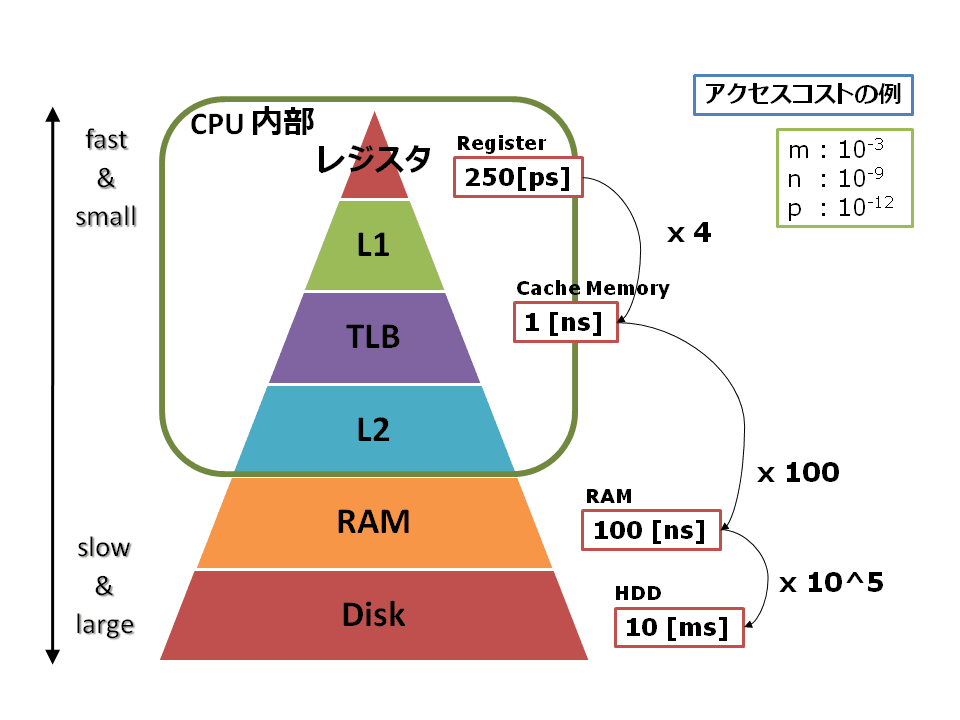
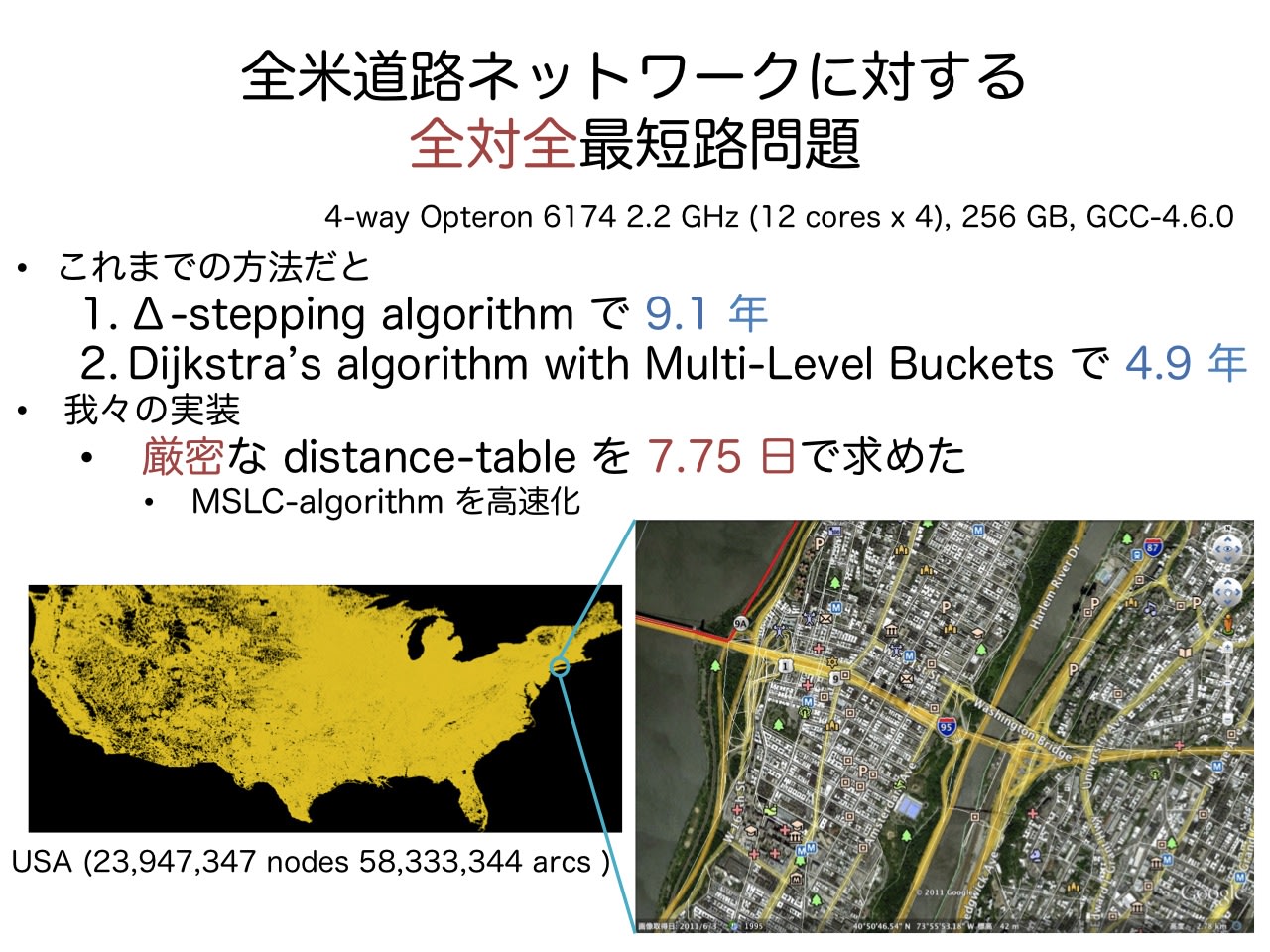
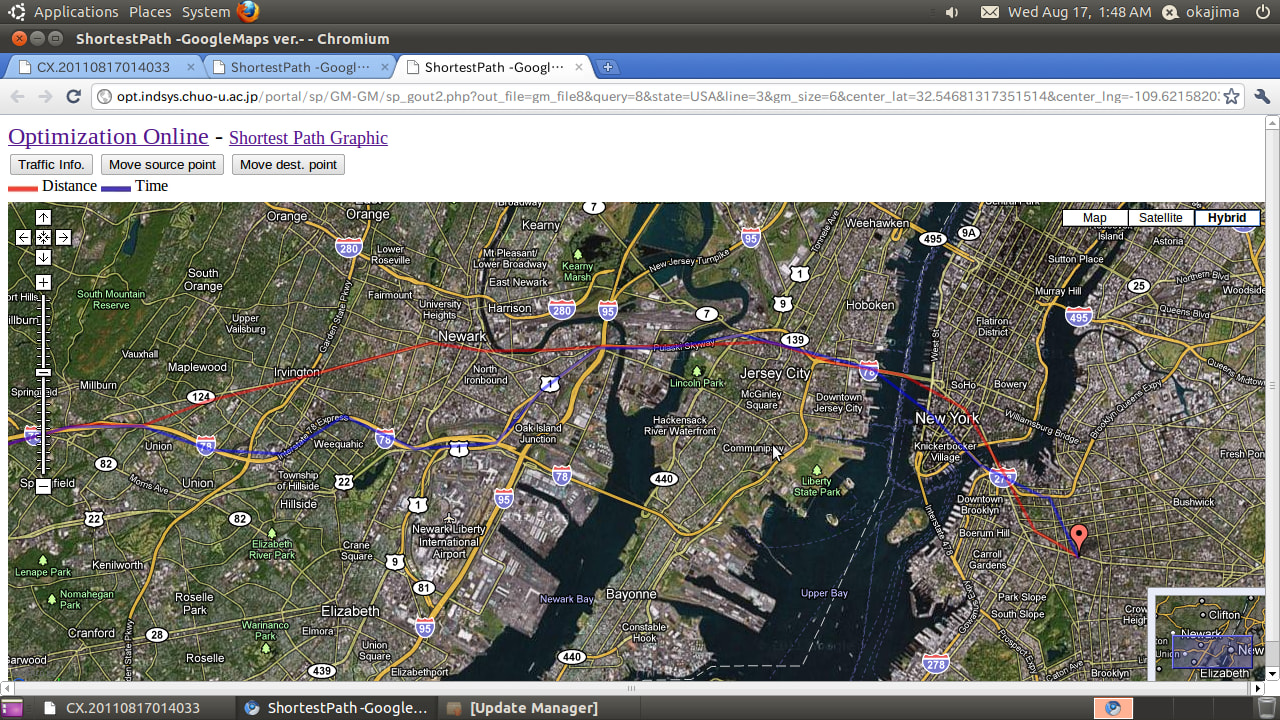
2. 13:55~14:20 「ポストペタスケールスパコンにおける超大規模グラフ最適化基盤」 藤澤克樹(中央大学)
3. 14:20~14:45 「建築・都市計画における避難計画問題と計算機技術」 瀧澤重志(京都大学)
4. 15:00~15:25 「生物高次情報データベース高速検索アルゴリズム」 渋谷哲朗(東京大学)
5. 15:25~15:50 「アルゴリズムの応用例: 物体の認識と画像検索」 徳山豪(東北大学)
6. 15:50~16:15 「ZDDを用いた新しい列挙アルゴリズムとその実応用への展開」: 湊真一(北海道大学)
7. 16:20~17:00 自由討論
日時:9月4日(日曜日)13時30分から17時00分まで
場所:公立はこだて未来大学(http://www.fun.ac.jp/)研究棟 R791室
プログラム(確定版)
1. 13:30~13:55 「計画概要」 加藤直樹(京都大学)
2. 13:55~14:20 「ポストペタスケールスパコンにおける超大規模グラフ最適化基盤」 藤澤克樹(中央大学)
3. 14:20~14:45 「建築・都市計画における避難計画問題と計算機技術」 瀧澤重志(京都大学)
4. 15:00~15:25 「生物高次情報データベース高速検索アルゴリズム」 渋谷哲朗(東京大学)
5. 15:25~15:50 「アルゴリズムの応用例: 物体の認識と画像検索」 徳山豪(東北大学)
6. 15:50~16:15 「ZDDを用いた新しい列挙アルゴリズムとその実応用への展開」: 湊真一(北海道大学)
7. 16:20~17:00 自由討論