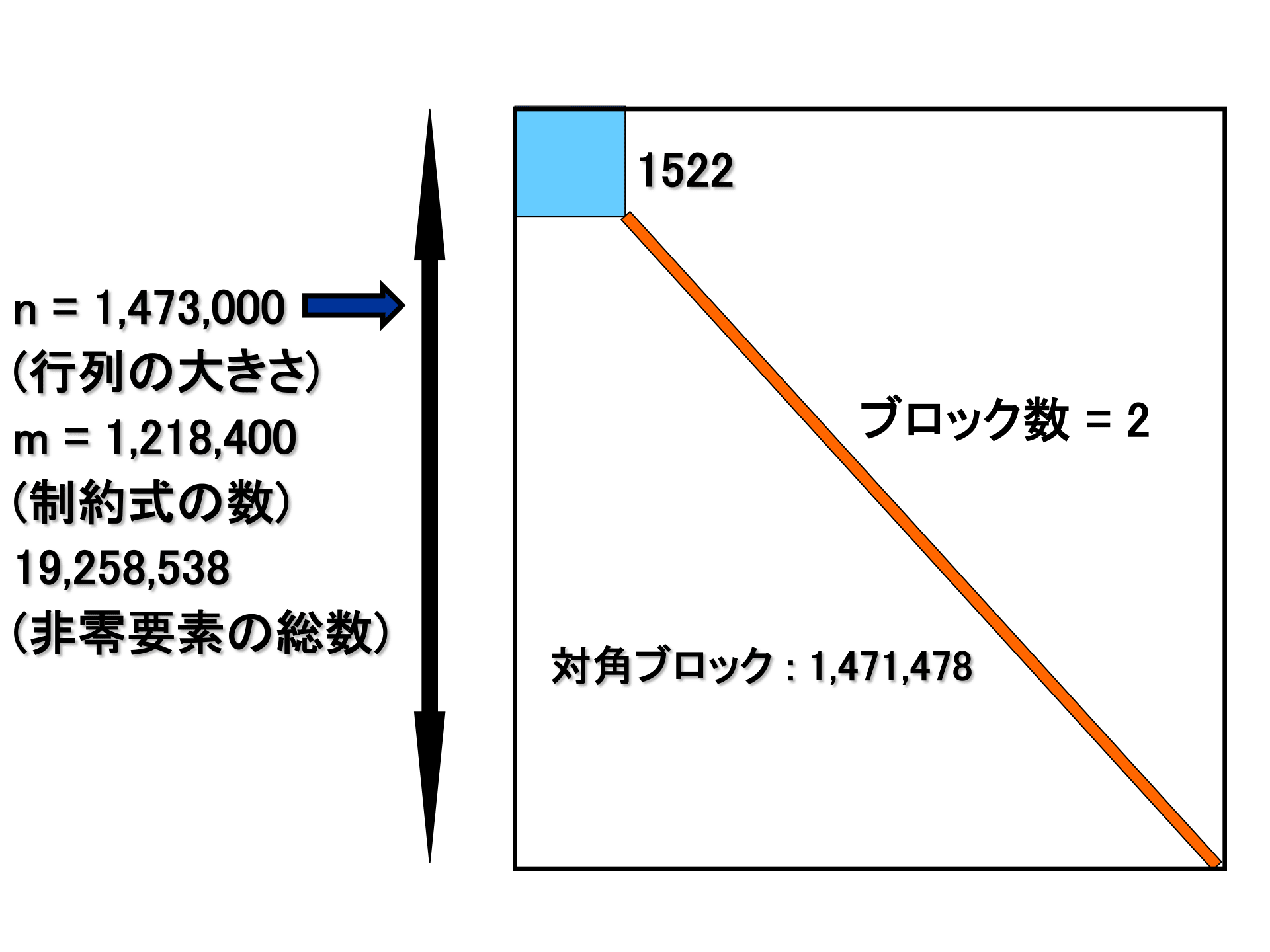
以下のような複数のクラスタ計算機を用いて最新の SDPARA の比較実験を行った。各クラスタ計算機で状況や設定が異なるため参考まで。
◯問題:N.4P.DZ.pqgt1t2p.dat-s
◯ OPT クラスタ(32CPU x 6コア = 192コア):529.37 秒
◯ OPT クラスタ(16CPU x 6コア = 96コア):921.33 秒
◯ SDPA クラスタ(16CPU x 4コア = 64コア):937.46 秒
◯ POWER クラスタ(8CPU x 4コア = 32コア):2658.90 秒
◯ OPTERON クラスタ(2PU x 48コア = 96コア):1811.80 秒
◯ OPTERON クラスタ(16 x 8コア = 96コア):2036.45 秒
参考 : SDPA
◯ OPTERON 1台 (1CPU x 48 コア = 48コア) : 2548.71秒
----------------------------------------------------------------------------------------------
○ OPT クラスタ
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.7 for x86_64
○ SDPA クラスタ
8 Nodes, 16 CPUs, 64 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.7 for x86_64
○ POWER クラスタ
4 Nodes, 8 CPUs, 32 CPU コア;
CPU : Intel Xeon E5345 2.33GHz (quad cores) x 2 / node
Memory : 16GB / node
HDD : 2TB(RAID 5) / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.7 for x86_64
◯ OPTERON クラスタ
2 Nodes, 8 CPUs, 96 CPU コア;
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4 / node
Memory : 256GB (16 x 16GB / 1066MHz) / node
NIC : GbE x 4 / node
OS : Fedora 15 for x86_64
◯問題:N.4P.DZ.pqgt1t2p.dat-s
◯ OPT クラスタ(32CPU x 6コア = 192コア):529.37 秒
◯ OPT クラスタ(16CPU x 6コア = 96コア):921.33 秒
◯ SDPA クラスタ(16CPU x 4コア = 64コア):937.46 秒
◯ POWER クラスタ(8CPU x 4コア = 32コア):2658.90 秒
◯ OPTERON クラスタ(2PU x 48コア = 96コア):1811.80 秒
◯ OPTERON クラスタ(16 x 8コア = 96コア):2036.45 秒
参考 : SDPA
◯ OPTERON 1台 (1CPU x 48 コア = 48コア) : 2548.71秒
----------------------------------------------------------------------------------------------
○ OPT クラスタ
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.7 for x86_64
○ SDPA クラスタ
8 Nodes, 16 CPUs, 64 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.7 for x86_64
○ POWER クラスタ
4 Nodes, 8 CPUs, 32 CPU コア;
CPU : Intel Xeon E5345 2.33GHz (quad cores) x 2 / node
Memory : 16GB / node
HDD : 2TB(RAID 5) / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.7 for x86_64
◯ OPTERON クラスタ
2 Nodes, 8 CPUs, 96 CPU コア;
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4 / node
Memory : 256GB (16 x 16GB / 1066MHz) / node
NIC : GbE x 4 / node
OS : Fedora 15 for x86_64