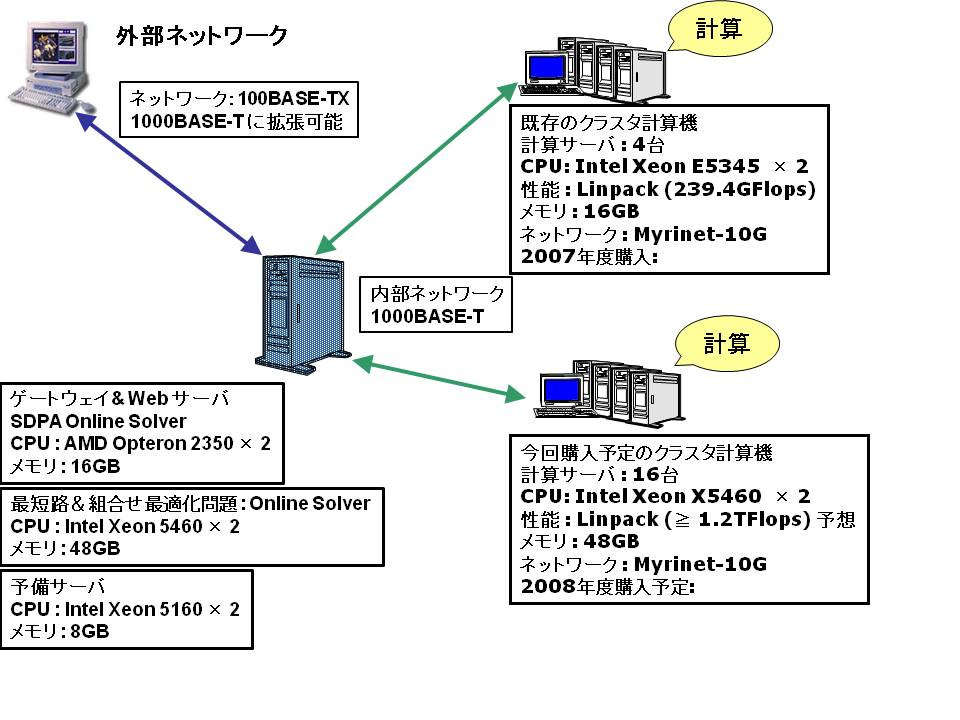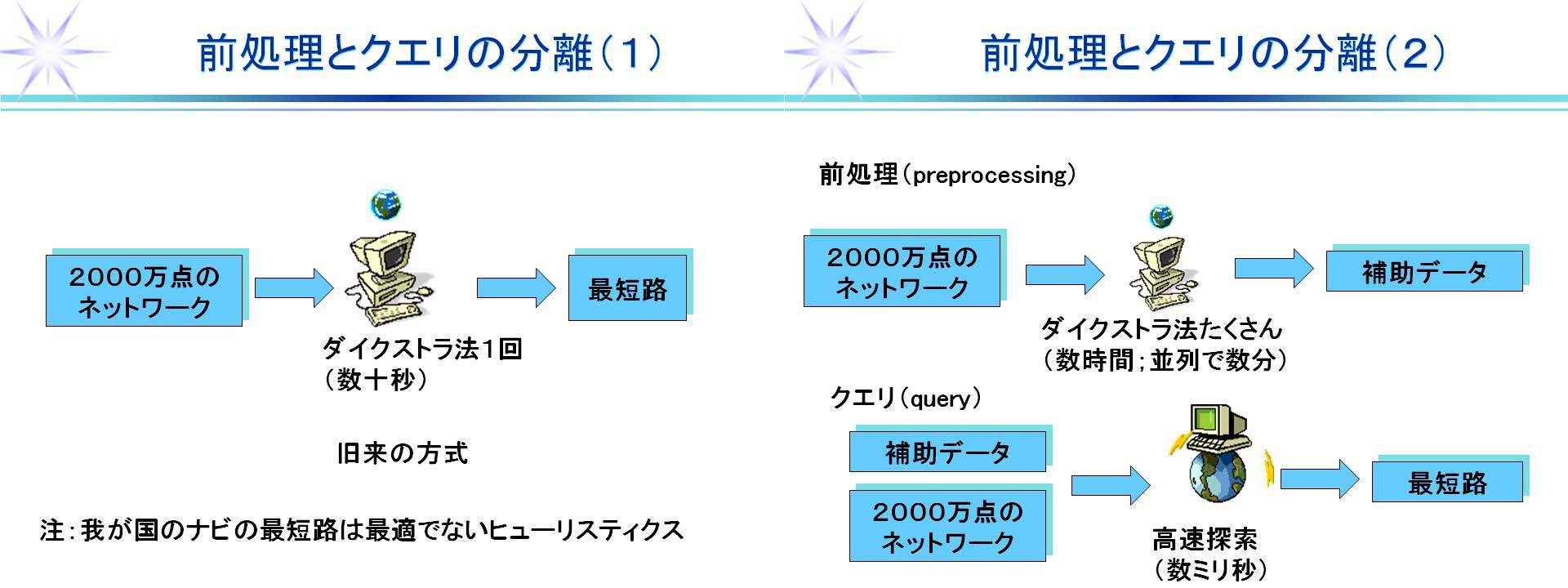
最短路 Online Solver から、一番大きな全米データ(#nodes: 23,947,347 | #arcs: 58,333,344)を選んでも、バケット法で 3~4秒、ヒープでも 5 秒程度で実行が終了する。図を見てもらえればわかるのだが、そもそも全米データ(2000万点以上)での前処理なしのダイクストラ法の実行に数十秒を要していたので、前処理+ダイクストラ法という発想になった。それが今では、数秒程度に短縮されている(データ読み込み等の時間も入っているので、query 自体は 1 ~ 2秒か?)。これは、やはり以下のマシンのパワーに依存するところも大きい(ただし、1 query は 1 スレッドでの実行)。
PowerEdge 2900
CPU : Intel X5460 (3.16GHz) × 2
メモリ : 48GB (4GB × 12)
HDD : 1TB × 6 (RAID5)
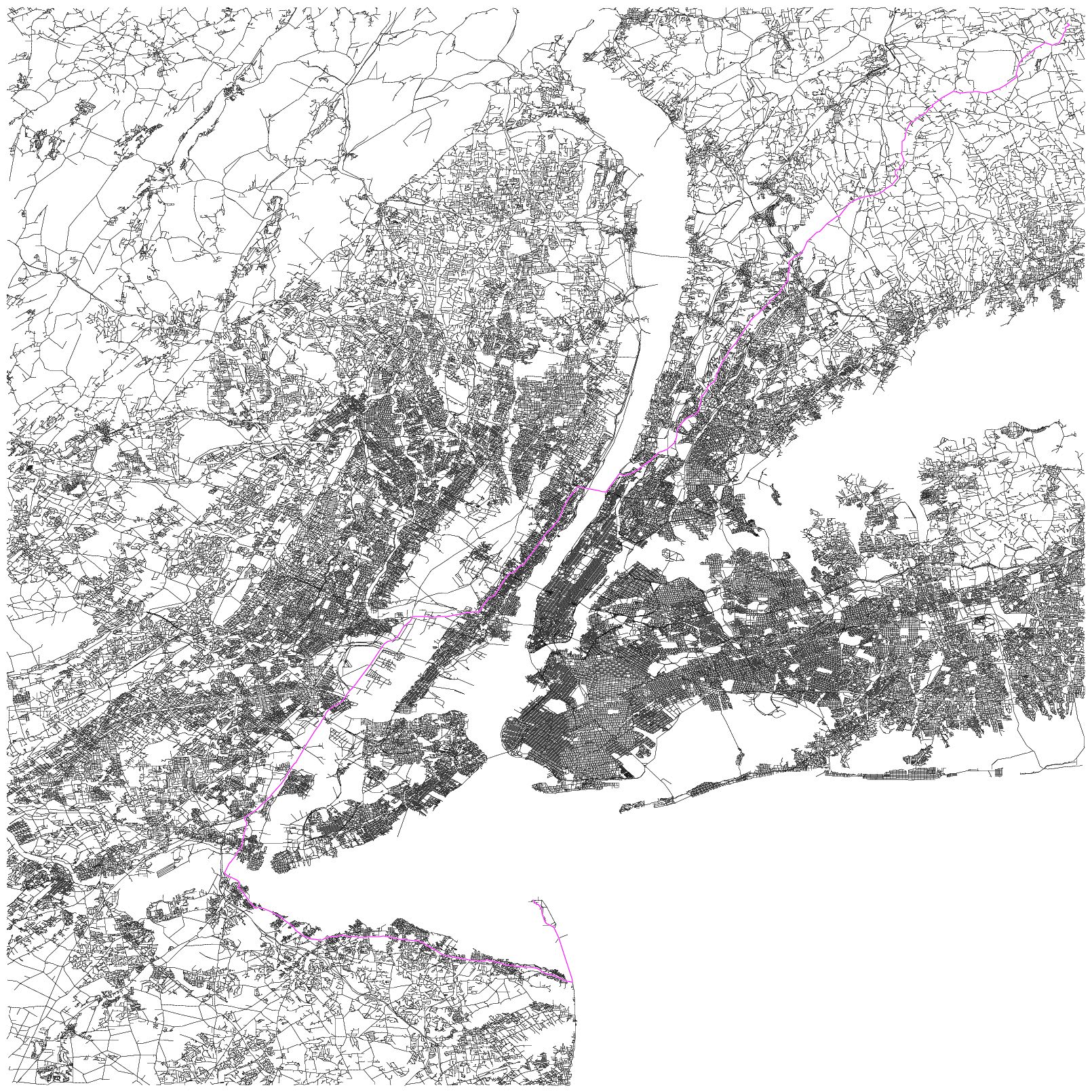
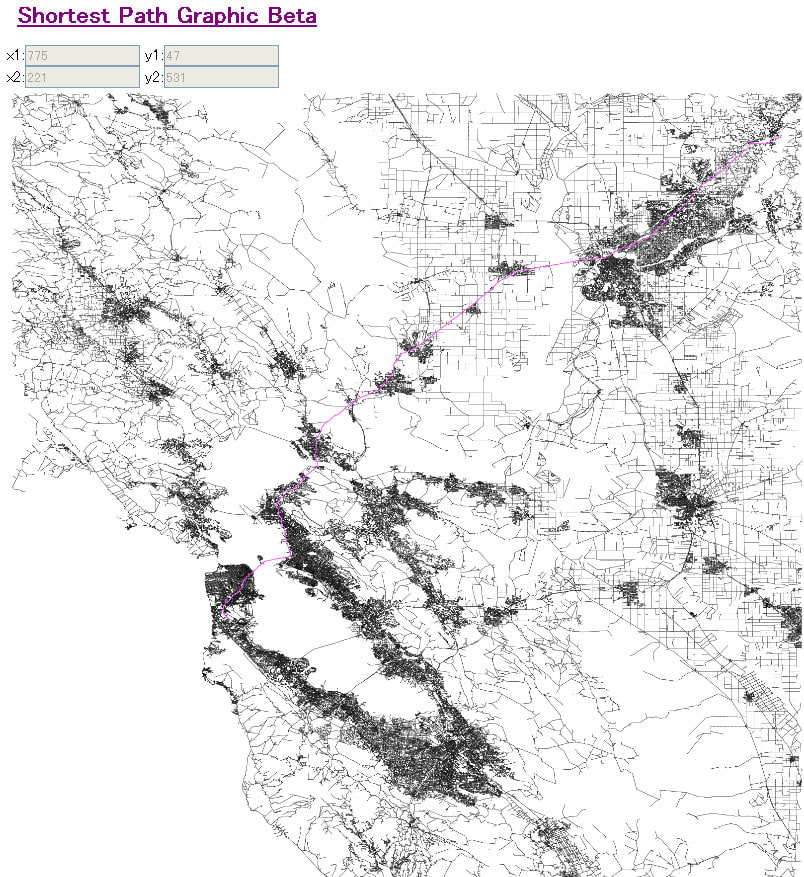
また図の中で前処理 + query で数ミリ秒という目標になっているが、これは最短距離だけ求めれば良い場合なので、最短路まで求めているこの Online Solver の方がより手間がかかっている。ちなみに Online Solver でも、NY(#nodes: 264,346 | #arcs: 733,846)だと、前処理なしでもミリ秒単位で最短路を求めることができる。前処理なしということは動的にグラフのトポロジーや枝長が変化しても構わないということである。
PowerEdge 2900
CPU : Intel X5460 (3.16GHz) × 2
メモリ : 48GB (4GB × 12)
HDD : 1TB × 6 (RAID5)
また図の中で前処理 + query で数ミリ秒という目標になっているが、これは最短距離だけ求めれば良い場合なので、最短路まで求めているこの Online Solver の方がより手間がかかっている。ちなみに Online Solver でも、NY(#nodes: 264,346 | #arcs: 733,846)だと、前処理なしでもミリ秒単位で最短路を求めることができる。前処理なしということは動的にグラフのトポロジーや枝長が変化しても構わないということである。