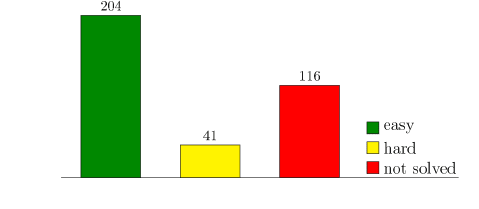
PGAS 言語 X10 を用いた SDP に対する内点法の実装に関する発表を以下の研究発表会で行います。実際には SDPA の X10 化になります。
第133回ハイパフォーマンスコンピューティング研究発表会
■日時: 2012年3月26日(月)~2012年3月27日(火)
■場所: 有馬ビューホテルうらら
■カーネルチューニング(14:55 - 16:10)
PGAS 言語 X10 を用いた半正定値計画問題の実装と性能評価
†渡部優(東工大、JST CREST)○,藤澤克樹(中央大、JST CREST),
鈴村豊大郎(東工大、IBM 東京基礎研、 JST CREST)
第133回ハイパフォーマンスコンピューティング研究発表会
■日時: 2012年3月26日(月)~2012年3月27日(火)
■場所: 有馬ビューホテルうらら
■カーネルチューニング(14:55 - 16:10)
PGAS 言語 X10 を用いた半正定値計画問題の実装と性能評価
†渡部優(東工大、JST CREST)○,藤澤克樹(中央大、JST CREST),
鈴村豊大郎(東工大、IBM 東京基礎研、 JST CREST)