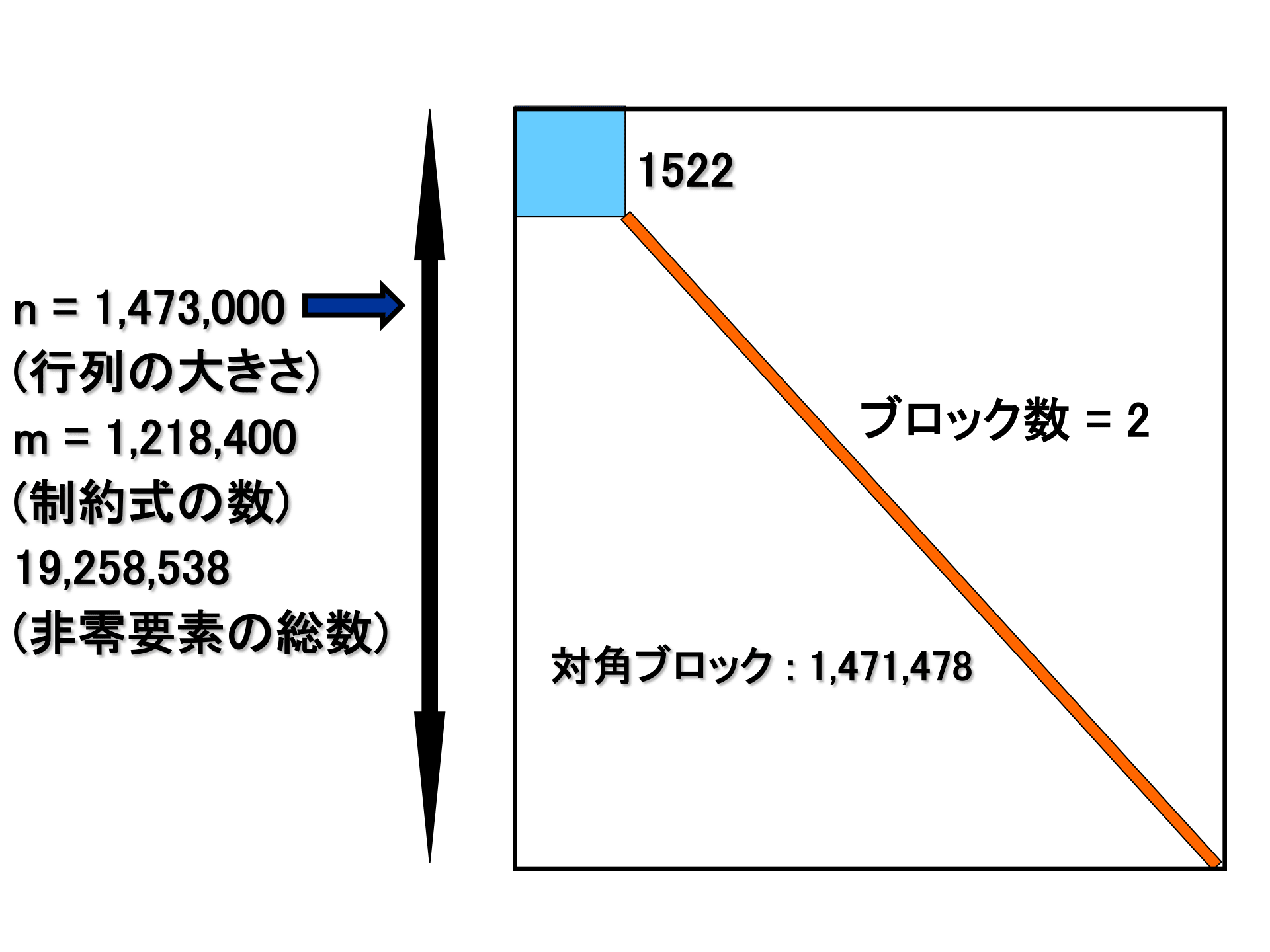
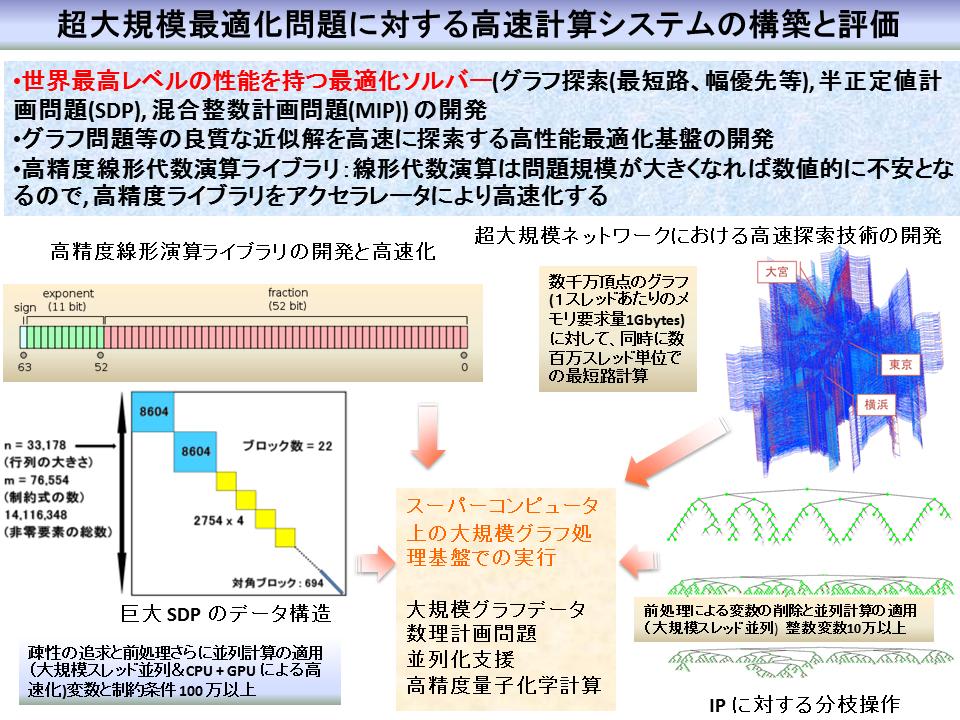
第1回 Graph CREST シンポジウムに関する情報の更新です。一部の講演の Abstract を記載します。
開催日:2012年3月23日(金)9:45 ~ 18:00
場所:中央大学後楽園キャンパス6号館3階6301室
参加費:無料
主催:JST CREST ポストペタスケールシステムにおける超大規模グラフ最適化基盤
Title: Benchmarks for Optimization Software
H.D. Mittelmann
School of Mathematical and Statistical Sciences
Arizona State University, USA
Abstract:
Under the title "Benchmarks for Optimization Software" we maintain extensive
evaluations of a large selection of optimization software. In this talk we
will report on the benchmarks in discrete optimization including those
based on MIPLIB 2010 as well as selected ones in continuous optimization.
[1] Benchmarks for Optimization Software, http://plato.asu.edu/bench.html
[2] MIPLIB 2010, http://miplib.zib.de, Math Prog Comp 3, 103-163 (2011)
Title: What is Linear and Mixed Integer Programming(LP/MIP)
Timo Berthold
Zuse Institute Berlin, Germany
Abstract:
Linear programming (LP) means the optimization of a linear function
subject to a set of linear constraints. In mixed-integer programming
(MIP), additionally, some of the variables are required to take integer
values. Linear and mixed-integer programming are two of the most essential
techniques in theory and practice of mathematical optimization.
Nowadays, linear programs with hundreds of thousands of variables and
constraints can be solved efficiently. Although this is not generally true
for mixed-integer programming - which is NP-hard -, state-of-the-art
software often is able to solve large, practically relevant problems.
This talk is supposed to be an introduction to the computational aspects
of LP and MIP. We present three commonly used algorithms to solve
large-scale, practically relevant problems of these types: the simplex algorithm for
LPs, the general cutting plane method and the branch-and-bound algorithm
for IPs. We discuss some of their pitfalls and ruses and showcase a few
algorithmic enhancements the today's MIP solvers are equipped with.
Title: First steps with Zimpl and SCIP
Ambros Gleixner, Stefan Heinz
Zuse Institute Berlin, Germany
Abstract:
In this tutorial, we demonstrate the usage of the modeling language Zimpl
and the mixed integer programming solver SCIP. We show how to model two
different formulations for the well-known binpacking problem and discuss
their limitations. Feeding them into SCIP we compare their computational
performance within a standalone branch-and-cut solver.
Zimpl is an algebraic modeling language featuring exact arithmetic. SCIP is
branch-cut-and-price framework targeted towards the need of researchers. It
allows total control of the solution process and the access of detailed
information down to the guts of the solver. Both tools are part of the ZIB
Optimization Suite (http://zibopt.zib.de), which is free for academic use
and available in source code.
Title: Using SCIP as a branch-and-price framework
Stefan Heinz
Zuse Institute Berlin, Germany
Abstract:
Column generation is a technique to handle large-scale linear programs
efficiently. In practice, it is widely used to solve real world problems
within a branch-and-price approach. Examples are rolling stock roster
planning, duty scheduling, and vehicle scheduling.
In this talk we are focusing on the branch-and-price feature of SCIP. We
illustrate using the steel mill slab problem, how the framework SCIP is
easily customized for all needs of branch-and-price approach.
We first present the basic idea of column generation and
branch-and-price. Second, we show step-by-step, how the framework SCIP can
be applied as a branch-and-price framework. Finally, we discuss some
pitfalls of the branch-and-price method which are easily avoidable within
the SCIP framework.
Title: Improving the accuracy of LP solvers
Ambros Gleixner
Zuse Institute Berlin, Germany
Abstract:
We describe an iterative refinement procedure for computing extended precision or exact solutions
to linear programming problems (LPs). Arbitrarily precise solutions can be computed by solving a
sequence of closely related LPs with limited precision arithmetic. The LPs solved at iterations of
this algorithm share the same constraint matrix as the original problem instance and are transformed
only by modification of the objective function, right-hand side, and variable bounds.
Exact computation is used to compute and store the exact representation of the transformed
problems, while numeric computation is used for computing approximate LP solutions and applying
iterations of the simplex algorithm. At all steps of the algorithm the LP bases encountered in the
transformed problems correspond directly to LP bases in the original problem description.
We demonstrate that this algorithm is effective in practice for computing extended precision
solutions and that this leads to direct improvement of the best known methods for solving LPs
exactly over the rational numbers. A proof-of-concept implementation is done within the SoPlex LP
solver.
Title: Primal Heuristics for MIP
Timo Berthold
Zuse Institute Berlin, Germany
Abstract:
In modern MIP-solvers like the state-of-the-art
branch-cut-and-price-framework SCIP, primal heuristics play a major role
in finding and improving feasible solutions at the early steps of the
solution process.
Primal heuristics in SCIP can be categorized in three groups:
* rounding and propagation heuristics
* diving and objective diving heuristics
* large neighborhood search heuristics
We give examples for each of these classes, concentrating on recently
propsed algorithms. Further, we discuss the question of how the quality of
a primal heuristic should be evaluated and introduce a new a new
performance measure, the "primal integral". It assess the impact of these
primal heuristics on the ability to find feasible solutions, in
particular early during search. Finally, we discuss some computational results.
Title: Three ideas for the Quadratic Assignment Problem
Domenico Salvagnin
University of Padova, Italy
Abstract:
We address the exact solution of the famous esc instances of the quadratic assignment problem. These
are extremely hard instances that remained unsolved―even allowing for a tremendous computing
power―by using all previous techniques from the literature. During this challenging task we found
that three ideas were particularly useful, and qualified as a breakthrough for our approach. The
present talk is about describing these ideas and their impact in solving esc instances. Our method
was able to solve, in a matter of seconds or minutes on a single PC, all easy cases (all esc16* plus
esc32e and esc32g). The three very hard instances esc32c, esc32d and esc64a were solved in less than
half an hour, in total, on a single PC. We also report the solution, in about 5 hours, of tai64c. By
using a facility-flow splitting procedure, we were also able to solve to proven optimality, for the
first time, esc32h (in about 2 hours) as well as “the big fish” esc128 (to our great surprise, the
solution of the latter required just a few seconds on a single PC).