








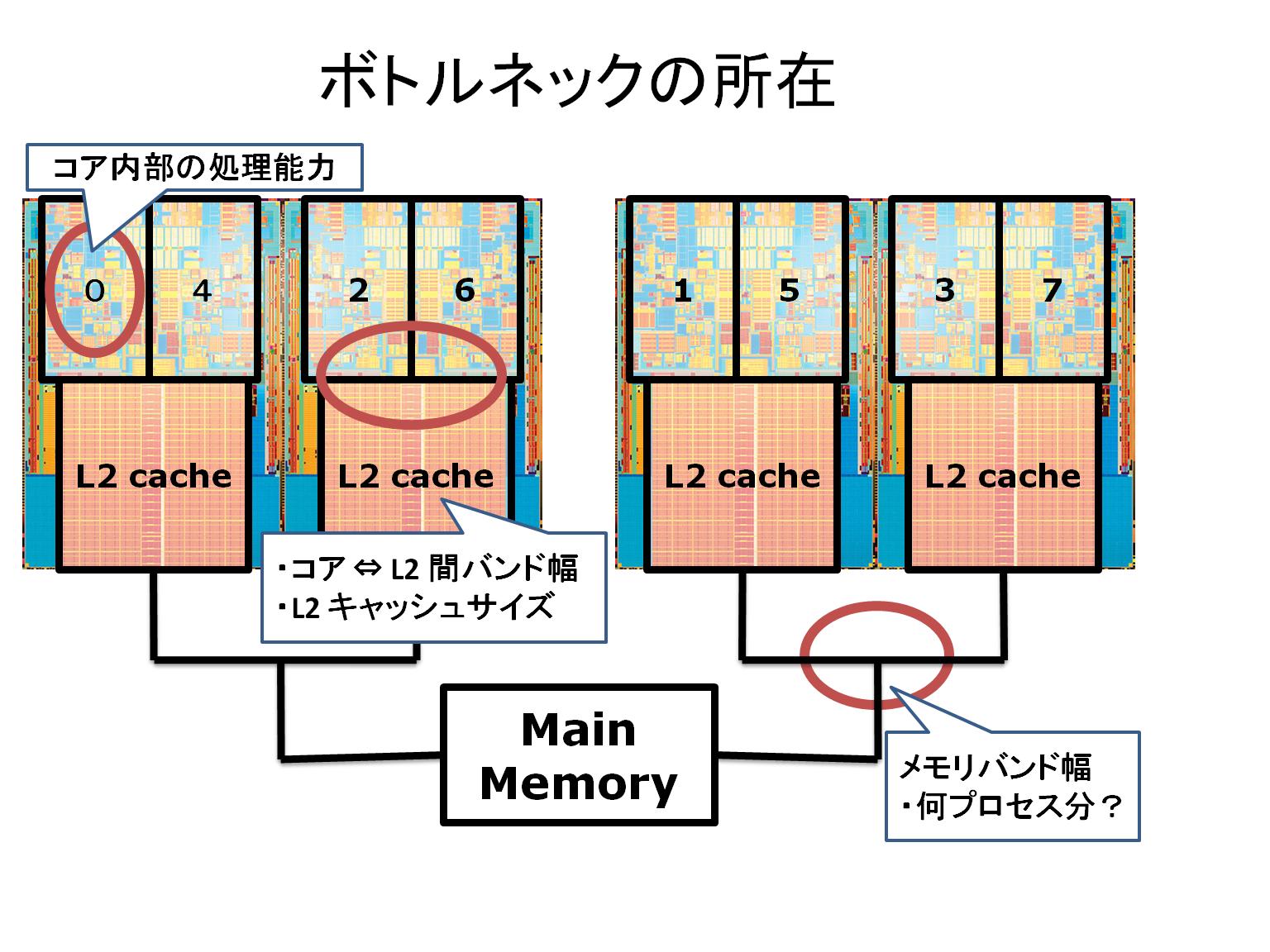
TORQUE を SDPA クラスタにインストールしたので、大規模実験が随分楽になった(もっと早めにすれば良かった)。CentOS 5.2 を使用しているので kernel 2.6.18 になるが、各コアに対するジョブの割り当ては思ったよりも優秀だ。例えば添付の図は Intel Xeon 5460 (クアッドコア) × 2 個のときの、各コアの通し番号を示しているが、このノードに MPI で4個のプロセスを割り当てたときには、コア 0, 2, 1, 3 のように同じ L2 キャッシュを共有しないようにコアを使用している。とは言っても実行中に コア 0 を使ったり、コア 4 を使ったりと動的に変化するので、やはり numactl で固定した方が良い。




