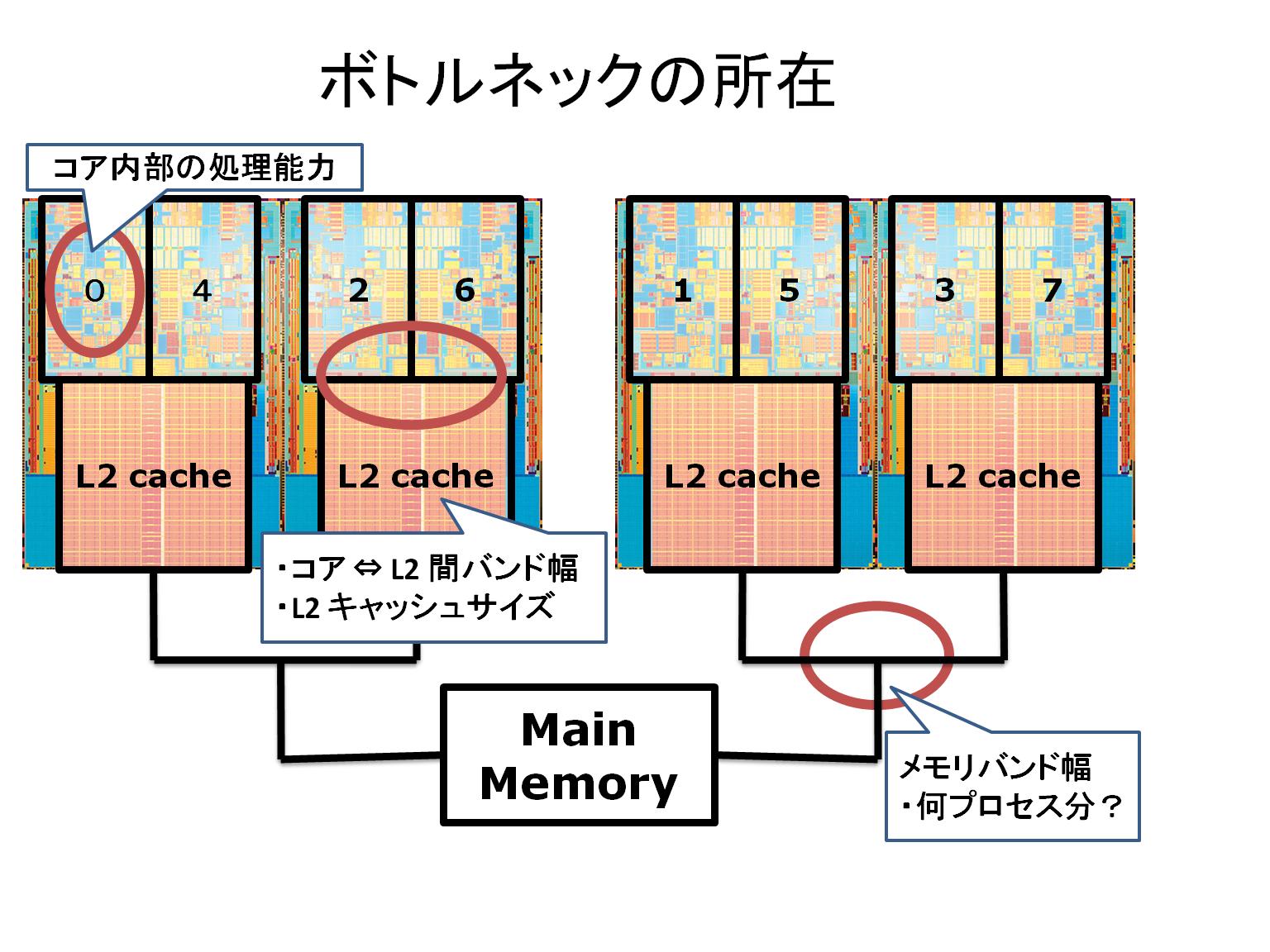
mpich2-mx-1.0.7..2 + mx 1.2.6 から mpich-mx_1.2.7..7.tar.gz + mx 1.2.6 に変更したところ、少しだけ性能が上がって 1.434TFlops = 88.62% になった。
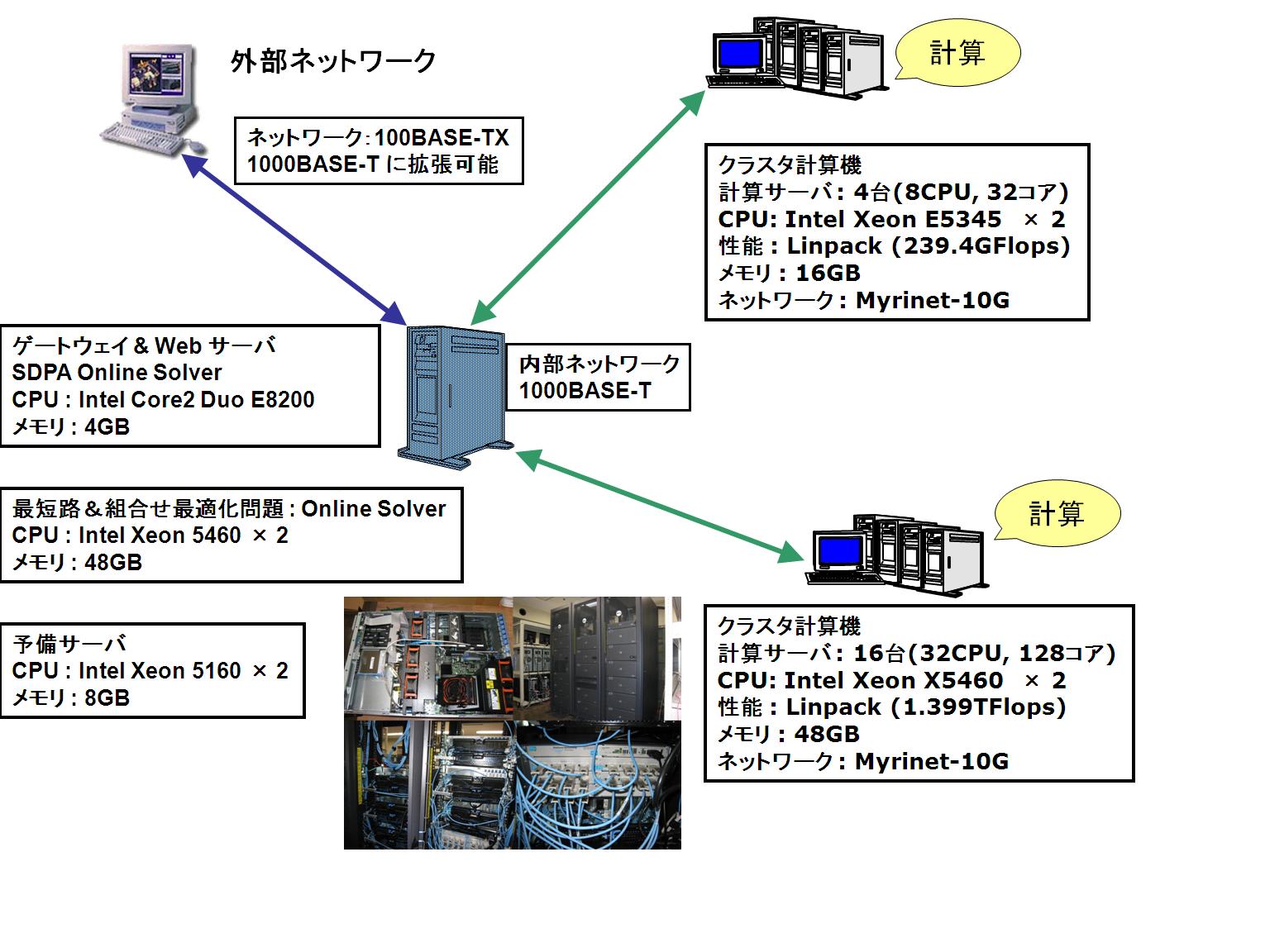
●新 SDPA クラスタ (2008年)
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
HDD : 6TB(RAID 5) / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.2 for x86_64
Linpack : R_max = 1.434TFlops, R_peak = 1.618TFlops, R_max / R_peak = 88.62%
============================================================================
T/V N NB P Q Time Gflops
----------------------------------------------------------------------------
WR11C2C4 310000 200 4 8 13848.83 1.434e+03
----------------------------------------------------------------------------
||Ax-b||_oo / ( eps * ||A||_1 * N ) = 0.0116097 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 ) = 0.0008188 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo ) = 0.0001353 ...... PASSED
============================================================================
●新 SDPA クラスタ (2008年)
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
HDD : 6TB(RAID 5) / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.2 for x86_64
Linpack : R_max = 1.434TFlops, R_peak = 1.618TFlops, R_max / R_peak = 88.62%
============================================================================
T/V N NB P Q Time Gflops
----------------------------------------------------------------------------
WR11C2C4 310000 200 4 8 13848.83 1.434e+03
----------------------------------------------------------------------------
||Ax-b||_oo / ( eps * ||A||_1 * N ) = 0.0116097 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 ) = 0.0008188 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo ) = 0.0001353 ...... PASSED
============================================================================