








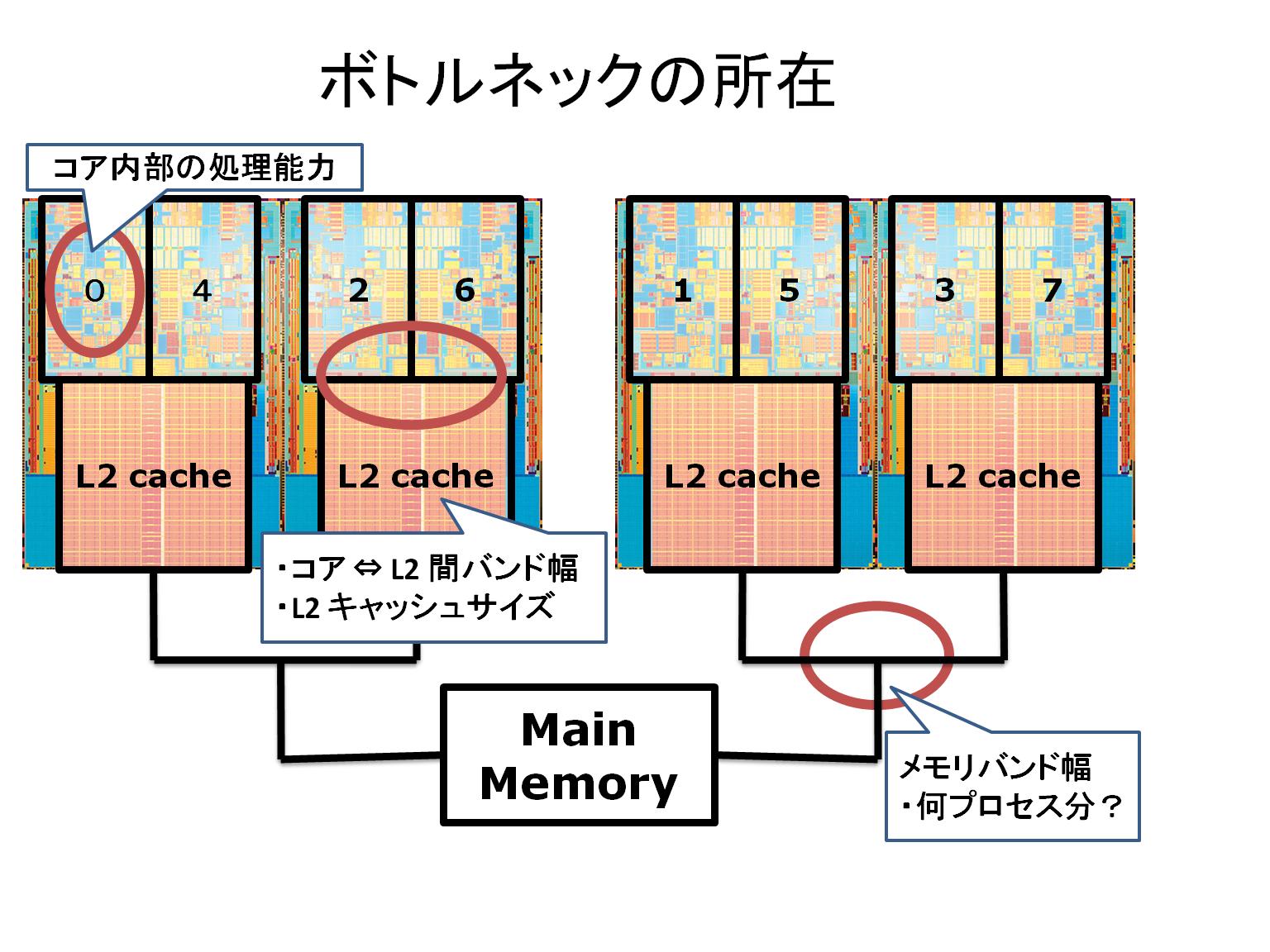
前回の続きで今度は CPU 数を増やしたときの結果を見てみよう。
1CPU の場合
mpiexec -machinefile ./hosts -n 1 numactl --physcpubind=0 ./simple_example
1m54.055s
2CPU の場合 (1 ノードで 2 プロセス)
mpiexec -machinefile ./hosts -n 2 numactl --physcpubind=0,1 ./simple_example
1m44.551s
2CPU の場合 (1 ノードで 1 プロセス)
mpiexec -machinefile ./hosts2 -n 2 numactl --physcpubind=0 ./simple_example
1m44.607s
4CPU の場合 (1 ノードで 4 プロセス)
mpiexec -machinefile ./hosts4 -n 4 numactl --physcpubind=0,1,2,3 ./simple_example
1m1.440s
4CPU の場合 (1 ノードで 2 プロセス)
mpiexec -machinefile ./hosts -n 4 numactl --physcpubind=0,1 ./simple_example
1m3.123s
4CPU の場合 (1 ノードで 1 プロセス)
mpiexec -machinefile ./hosts2 -n 4 numactl --physcpubind=0 ./simple_example
1m6.216s
8CPU の場合 (1 ノードで 8 プロセス)
mpiexec -machinefile ./hosts8 -n 8 numactl --physcpubind=0,1,2,3,4,5,6,7 ./simple_example
43.303s
8CPU の場合 (1 ノードで 4 プロセス)
mpiexec -machinefile ./hosts4 -n 8 numactl --physcpubind=0,1,2,3 ./simple_example
42.859s
8CPU の場合 (1 ノードで 2 プロセス)
mpiexec -machinefile ./hosts -n 8 numactl --physcpubind=0,1 ./simple_example
43.114s
8CPU の場合 (1 ノードで 1 プロセス)
mpiexec -machinefile ./hosts2 -n 8 numactl --physcpubind=0 ./simple_example
44.062s
というわけで、この場合では numactl --physcpubind=0,1,2,3 として 1 ノード, 4 プロセスで実行するのが良さそう。
1CPU の場合
mpiexec -machinefile ./hosts -n 1 numactl --physcpubind=0 ./simple_example
1m54.055s
2CPU の場合 (1 ノードで 2 プロセス)
mpiexec -machinefile ./hosts -n 2 numactl --physcpubind=0,1 ./simple_example
1m44.551s
2CPU の場合 (1 ノードで 1 プロセス)
mpiexec -machinefile ./hosts2 -n 2 numactl --physcpubind=0 ./simple_example
1m44.607s
4CPU の場合 (1 ノードで 4 プロセス)
mpiexec -machinefile ./hosts4 -n 4 numactl --physcpubind=0,1,2,3 ./simple_example
1m1.440s
4CPU の場合 (1 ノードで 2 プロセス)
mpiexec -machinefile ./hosts -n 4 numactl --physcpubind=0,1 ./simple_example
1m3.123s
4CPU の場合 (1 ノードで 1 プロセス)
mpiexec -machinefile ./hosts2 -n 4 numactl --physcpubind=0 ./simple_example
1m6.216s
8CPU の場合 (1 ノードで 8 プロセス)
mpiexec -machinefile ./hosts8 -n 8 numactl --physcpubind=0,1,2,3,4,5,6,7 ./simple_example
43.303s
8CPU の場合 (1 ノードで 4 プロセス)
mpiexec -machinefile ./hosts4 -n 8 numactl --physcpubind=0,1,2,3 ./simple_example
42.859s
8CPU の場合 (1 ノードで 2 プロセス)
mpiexec -machinefile ./hosts -n 8 numactl --physcpubind=0,1 ./simple_example
43.114s
8CPU の場合 (1 ノードで 1 プロセス)
mpiexec -machinefile ./hosts2 -n 8 numactl --physcpubind=0 ./simple_example
44.062s
というわけで、この場合では numactl --physcpubind=0,1,2,3 として 1 ノード, 4 プロセスで実行するのが良さそう。





