








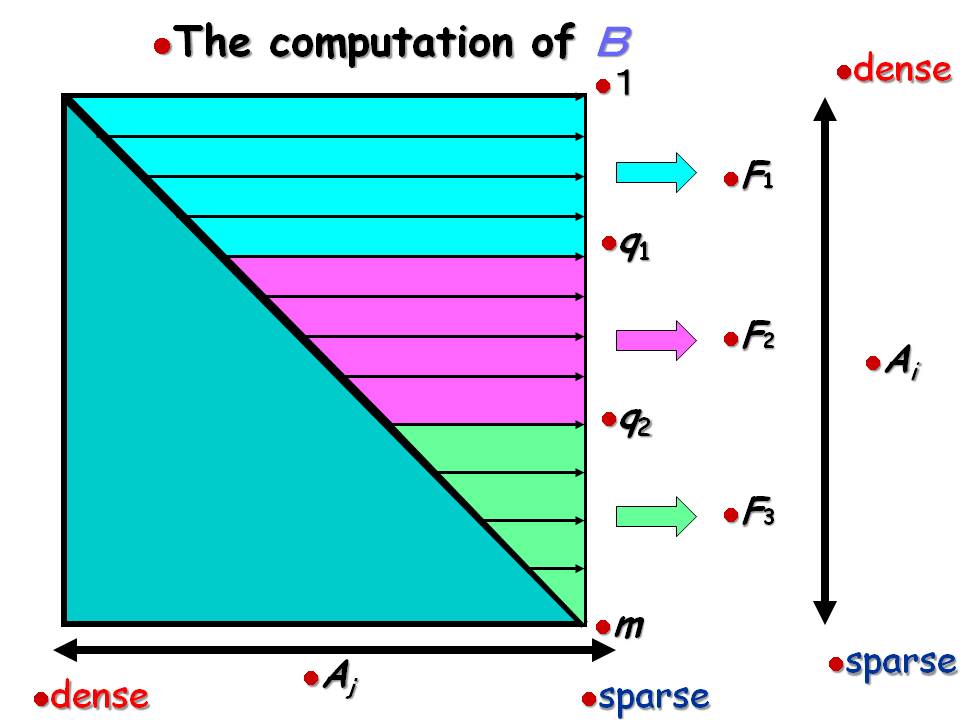
SDPA のアルゴリズムの中で Schur complement 行列の全要素(正確には上三角行列の全要素)を計算する必要があって、多くの場合ではこの部分がボトルネックになっている。図のように問題の疎性に応じて上から F1 式(密な場合), F3 式(疎な場合)を用いて計算を行っていく。各行の計算は独立に行うことができるので SDPARA ではこの部分を MPI などを用いて並列化を行っている。最近は 1 ノードでもマルチコアなので、MPI ではなく pthread を用いて同じように行単位の計算をマルチスレッドで行ってみた。この F3 の計算式が曲者で、計算量は少ないがデータ移動量は非常多い。この F3 計算式の並列化を普通に行うと全く性能が上がらないので、CPU の演算能力ではなく、2次キャッシュやメモリのバンド幅などがボトルネックの原因になっていると推測される。
しかし、この行単位の計算では列方向(つまり行列 A_j) のデータは共通に使えるので、特に隣接性が高い隣り合った二つの行の計算を2次キャッシュを共有する形で並列計算を行うと高速化されるようだ。具体的な計算結果についてはその2以降で報告する。
しかし、この行単位の計算では列方向(つまり行列 A_j) のデータは共通に使えるので、特に隣接性が高い隣り合った二つの行の計算を2次キャッシュを共有する形で並列計算を行うと高速化されるようだ。具体的な計算結果についてはその2以降で報告する。




