








私共の任期は 2012 年 2 月までですので、SCOPE 研究会の次の研究会(当然名前も変わるでしょうが)の幹事校を募集します。少し早いですが、つくば合宿などのノウハウの継承などを考えますと遅くても 2011年3月ぐらいまでには決定した方が良いと思います。ただし主査と幹事は同じ機関に所属していなくても構いません。また主査、幹事の所属機関と開催場所が一致する必要もありません。開催場所はこれまでの前例から言いましても、東京の交通の便の良いところが好ましいと思います。
現時点で確定している情報をお伝えします。随時更新しますので SCOPE つくばの HP もご覧下さい。
○一般講演 23件
1:筑波大学 7件
2:中央大学 5件
3:東京工業大学 2件
3:防衛大学 2件
3:京都大学 2件
3:東京大学 2件
7:慶應大学 1件
7:九州大学 1件
7:理化学研究所 1件
○特別講演 4件
○宿泊希望者53名、25日宿泊希望者9名
宿泊場所は大学会館、天久保、春日の3箇所
25日の夜に前夜祭(飲み会)を予定しています。場所と時間については HP やブログに掲示します。
○26日の予定 9時20分開始、18時終了、懇親会18時半開始
○27日の予定 9時開始、16時15分終了
○一般講演 23件
1:筑波大学 7件
2:中央大学 5件
3:東京工業大学 2件
3:防衛大学 2件
3:京都大学 2件
3:東京大学 2件
7:慶應大学 1件
7:九州大学 1件
7:理化学研究所 1件
○特別講演 4件
○宿泊希望者53名、25日宿泊希望者9名
宿泊場所は大学会館、天久保、春日の3箇所
25日の夜に前夜祭(飲み会)を予定しています。場所と時間については HP やブログに掲示します。
○26日の予定 9時20分開始、18時終了、懇親会18時半開始
○27日の予定 9時開始、16時15分終了
今後の SCOPE 研究会の予定についてお知らせします。
○つくば合宿 6月26日(土曜日)、27日(日曜日)
○第2回:7月10日(土曜日)
講演者1 講演題目
金森敬文氏(名古屋大学) : 密度比の推定と計算 ―smoothed analysis からのアプローチ
講演者2 講演題目
安井雄一郎氏(中央大学) : 大規模最短路問題に対するダイクストラ法の高速化
○第3回:10月2日(土曜日)
講演者1 題目未定
Karen Aardal Delft Institute of Applied Mathematics, Faculteit EWI, Technische Universiteit Delft (Netherlands)
講演者2 題目未定
Timo Berthold Zuse Institute Berlin (ZIB), Berlin (Germany)
また以下のように KSMAP 合宿が開催される予定です。こちらもよろしくお願いします。
【日程】: 2010年10月9日(土)~11日(月祝)
【場所】: 琵琶湖コンファレンスセンター (滋賀県彦根市)
http://www.biwako-cc.com/
(JR能登川駅にてシャトルバスの送迎がございます.)
○つくば合宿 6月26日(土曜日)、27日(日曜日)
○第2回:7月10日(土曜日)
講演者1 講演題目
金森敬文氏(名古屋大学) : 密度比の推定と計算 ―smoothed analysis からのアプローチ
講演者2 講演題目
安井雄一郎氏(中央大学) : 大規模最短路問題に対するダイクストラ法の高速化
○第3回:10月2日(土曜日)
講演者1 題目未定
Karen Aardal Delft Institute of Applied Mathematics, Faculteit EWI, Technische Universiteit Delft (Netherlands)
講演者2 題目未定
Timo Berthold Zuse Institute Berlin (ZIB), Berlin (Germany)
また以下のように KSMAP 合宿が開催される予定です。こちらもよろしくお願いします。
【日程】: 2010年10月9日(土)~11日(月祝)
【場所】: 琵琶湖コンファレンスセンター (滋賀県彦根市)
http://www.biwako-cc.com/
(JR能登川駅にてシャトルバスの送迎がございます.)
SCOPE つくば合宿についてはたくさんの一般講演及び宿泊申し込みありがとうございました。一般講演については23件と昨年よりも3件増えました。特別講演が4件ですので、全部で27件の発表となります。また後日プログラムについてはHPより発表させていただきます。
会場はつくば駅から徒歩10分ぐらいの場所ですので、2日間全て参加できなくても気軽に会場にお立ち寄り下さい。
SCOPE@ つくば HP
http://www.indsys.chuo-u.ac.jp/~jgoto/SCOPE/mirai10.html
会場はつくば駅から徒歩10分ぐらいの場所ですので、2日間全て参加できなくても気軽に会場にお立ち寄り下さい。
SCOPE@ つくば HP
http://www.indsys.chuo-u.ac.jp/~jgoto/SCOPE/mirai10.html
実行期間が2週間と短かったので、京大 T2K スパコンで実行したときには、スレッド数と性能向上の関係などの測定ができなかった。そこで、ほぼ同等の CPU を持つ計算サーバを用いて、スレッド数を変化させながら実行時間の測定を行ってみた。この場合、BLAS はシングルスレッドで動作させているので、スレッド数による性能向上は基本的に SCM(Schur complement matrix)を作成する際のマルチスレッド化の効果による。この CPU (Barcelona) でも、マルチスレッド化の効果は非常に大きいのだが、京大 T2K スパコンのように 4CPU X 4 スレッド、つまり全部で 16 スレッド使った場合でも性能向上が起きるかというと、Barcelona とチップセットの性能を考えると、それは怪しいところがある。
○問題 LiH.1Sigma+.STO6G.pqgt1t2p.dat-s
2CPU x 1 スレッド : 123.23s
2CPU x 2 スレッド : 64.27s
2CPU x 4 スレッド : 35.00s
○問題 FH2+.1A1.STO6G.pqgt1t2p.dat-s
2CPU x 1 スレッド : 720.37s
2CPU x 2 スレッド : 356.80s
2CPU x 4 スレッド : 186.29s
---------------------------------------------------------------------
○ソフトウェア SDPARA 7.3.2
○計算サーバ
CPU : AMD Opteron 2356 2.3GHz (quad cores)x 2
Memory : 32GB
OS : Vine Linux 5.1 for x86_64
○ 京大 T2K スパコン : SDPARA 7.3.2
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
○問題 LiH.1Sigma+.STO6G.pqgt1t2p.dat-s
2CPU x 1 スレッド : 123.23s
2CPU x 2 スレッド : 64.27s
2CPU x 4 スレッド : 35.00s
○問題 FH2+.1A1.STO6G.pqgt1t2p.dat-s
2CPU x 1 スレッド : 720.37s
2CPU x 2 スレッド : 356.80s
2CPU x 4 スレッド : 186.29s
---------------------------------------------------------------------
○ソフトウェア SDPARA 7.3.2
○計算サーバ
CPU : AMD Opteron 2356 2.3GHz (quad cores)x 2
Memory : 32GB
OS : Vine Linux 5.1 for x86_64
○ 京大 T2K スパコン : SDPARA 7.3.2
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
記事に掲載されているデータの中で NH3 に対する最も大きな SDP を解いたときの実行時間が 72025.6秒となっている。このときの SDPARA 7.3.2 の実行時間の内訳データを公開する。
1: Make bF3 とは、探索方向を求める際に必要な線形方程式の Ax=b の行列 A の要素を計算する部分で、元の問題が疎(Sparse)な場合では bF3 という関数が自動的に選択される。bF3 の計算時間が全体の 90% を占める。この bF3 関数は計算量が少なく、メモリやキャッシュのバンド幅に依存するので、CPU 数とコア数を増やすのが有効。
2: 線形方程式を解く部分 (Cholesky bMat と solve)を合わせても全体の 1% にも達しない。
3: 行列積などを用いる O(n^3) の部分は、それぞれ 1% 前後の割合。
Time(sec) Ratio(% : MainLoop)
Predictor time = 69667.382968, 96.761392
Corrector time = 1125.197473, 1.562793
Make bMat time = 68217.586398, 94.747762
Make bDia time = 0.054071, 0.000075
Make bF1 time = 0.470901, 0.000654
Make bF2 time = 0.000000, 0.000000
Make bF3 time = 64842.060968, 90.059477
Make bPRE time = 0.416426, 0.000578
Make rMat time = 478.294591, 0.664306
Make gVec Mul = 253.251834, 0.351743
Make gVec time = 259.539509, 0.360476
copy gVec time = 0.000017, 0.000000
copy bMat time = 27.810713, 0.038626
symm bMat time = 49.788584, 0.069152
Cholesky bMat = 511.755498, 0.710780
Ste Pre time = 0.006029, 0.000008
Ste Cor time = 547.911277, 0.760997
solve = 37.226793, 0.051704
copy DyVec = 0.220225, 0.000306
sumDz = 103.070958, 0.143156
makedX = 875.629523, 1.216166
symmetriseDx = 194.134001, 0.269634
makedXdZ = 1172.834662, 1.628956
xMatTime = 210.758996, 0.292724
zMatTime = 348.767075, 0.484404
invzMatTime = 0.000000, 0.000000
xMatzMatTime = 0.000000, 0.000000
EigxMatTime = 265.661827, 0.368979
EigzMatTime = 247.089794, 0.343184
EigxMatzMatTime = 0.000000, 0.000000
updateRes = 86.384080, 0.119979
EigTime = 512.751621, 0.712163
sub_total_bMat = 3781.567245, 5.252238
Main Loop = 71999.153643, 100.000000
File Check = 0.000000, 0.000000
File Change = 0.017756, 0.000025
File Read = 26.496288, 0.036801
File Trans = 196.762887, 0.273285
Total = 72025.667687, 100.036825
1: Make bF3 とは、探索方向を求める際に必要な線形方程式の Ax=b の行列 A の要素を計算する部分で、元の問題が疎(Sparse)な場合では bF3 という関数が自動的に選択される。bF3 の計算時間が全体の 90% を占める。この bF3 関数は計算量が少なく、メモリやキャッシュのバンド幅に依存するので、CPU 数とコア数を増やすのが有効。
2: 線形方程式を解く部分 (Cholesky bMat と solve)を合わせても全体の 1% にも達しない。
3: 行列積などを用いる O(n^3) の部分は、それぞれ 1% 前後の割合。
Time(sec) Ratio(% : MainLoop)
Predictor time = 69667.382968, 96.761392
Corrector time = 1125.197473, 1.562793
Make bMat time = 68217.586398, 94.747762
Make bDia time = 0.054071, 0.000075
Make bF1 time = 0.470901, 0.000654
Make bF2 time = 0.000000, 0.000000
Make bF3 time = 64842.060968, 90.059477
Make bPRE time = 0.416426, 0.000578
Make rMat time = 478.294591, 0.664306
Make gVec Mul = 253.251834, 0.351743
Make gVec time = 259.539509, 0.360476
copy gVec time = 0.000017, 0.000000
copy bMat time = 27.810713, 0.038626
symm bMat time = 49.788584, 0.069152
Cholesky bMat = 511.755498, 0.710780
Ste Pre time = 0.006029, 0.000008
Ste Cor time = 547.911277, 0.760997
solve = 37.226793, 0.051704
copy DyVec = 0.220225, 0.000306
sumDz = 103.070958, 0.143156
makedX = 875.629523, 1.216166
symmetriseDx = 194.134001, 0.269634
makedXdZ = 1172.834662, 1.628956
xMatTime = 210.758996, 0.292724
zMatTime = 348.767075, 0.484404
invzMatTime = 0.000000, 0.000000
xMatzMatTime = 0.000000, 0.000000
EigxMatTime = 265.661827, 0.368979
EigzMatTime = 247.089794, 0.343184
EigxMatzMatTime = 0.000000, 0.000000
updateRes = 86.384080, 0.119979
EigTime = 512.751621, 0.712163
sub_total_bMat = 3781.567245, 5.252238
Main Loop = 71999.153643, 100.000000
File Check = 0.000000, 0.000000
File Change = 0.017756, 0.000025
File Read = 26.496288, 0.036801
File Trans = 196.762887, 0.273285
Total = 72025.667687, 100.036825
SDPA 64bit を用いて1台のサーバのみで H2O と NH3 の問題を解いたので、スパコンとクラスタとサーバの3者での実験結果を比較してみる。スパコンとクラスタ上では SDPARA 7.3.2 を実行している。この場合では CPU(MPI) x コア数(Pthread) で並列計算数を表現している。SDPA 7.3.2 はスレッド並列に用いたコア数を示している。結論から言うと1サーバでもこの程度の大きさの問題ならば何とか解くことができるが、やはりスパコンやクラスタは必要だと感じる。
問題1: H2O
○京大 T2K スパコン(CPU x コア数)
27,523.8s(128 x 16) ~ 7.6 時間
○SDPA クラスタ(CPU x コア数)
49,037.9s(16 x 8) ~ 13.6 時間
○計算サーバ2(コア数)
809,261.3s(12) ~ 224.8時間(9.4日)
問題2: NH3
○京大 T2K スパコン(CPU x コア数)
68,593.4s(128 x 16) ~ 19.1 時間
○SDPA クラスタ(CPU x コア数)
146,763.2s(32 x 4) ~ 40.8 時間
○計算サーバ1(コア数)
943,486.0s(8) ~ 262.1時間(10.9日)
○ 京大 T2K スパコン : SDPARA 7.3.2
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
○ SDPA クラスタ : SDPARA 7.3.2
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.5 for x86_64
○計算サーバ1 : SDPA 7.3.2 (64bit)
CPU : Intel Xeon 5550 (2.66GHz / 8MB L3) x 2
Memory : 72GB (18 x 4GB / 800MHz)
OS : Fedora 12 for x86_64
○計算サーバ2 : SDPA 7.3.2 (64bit)
CPU : AMD Opteron 2435(2.6GHz / 6MB L3)x 2
Memory : 64GB(16 x 4GB / 800MHz)
OS : Fedora 12 for x86_64
問題1: H2O
○京大 T2K スパコン(CPU x コア数)
27,523.8s(128 x 16) ~ 7.6 時間
○SDPA クラスタ(CPU x コア数)
49,037.9s(16 x 8) ~ 13.6 時間
○計算サーバ2(コア数)
809,261.3s(12) ~ 224.8時間(9.4日)
問題2: NH3
○京大 T2K スパコン(CPU x コア数)
68,593.4s(128 x 16) ~ 19.1 時間
○SDPA クラスタ(CPU x コア数)
146,763.2s(32 x 4) ~ 40.8 時間
○計算サーバ1(コア数)
943,486.0s(8) ~ 262.1時間(10.9日)
○ 京大 T2K スパコン : SDPARA 7.3.2
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
○ SDPA クラスタ : SDPARA 7.3.2
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.5 for x86_64
○計算サーバ1 : SDPA 7.3.2 (64bit)
CPU : Intel Xeon 5550 (2.66GHz / 8MB L3) x 2
Memory : 72GB (18 x 4GB / 800MHz)
OS : Fedora 12 for x86_64
○計算サーバ2 : SDPA 7.3.2 (64bit)
CPU : AMD Opteron 2435(2.6GHz / 6MB L3)x 2
Memory : 64GB(16 x 4GB / 800MHz)
OS : Fedora 12 for x86_64
イノベーション・ジャパン2010に出展(展示)するか現在検討を行っている。CEATEC Japan 2010 への出展お誘いもあったので、こちらの出展も検討してみたのだが以下の理由で取り止めた。
1:出展料が恐ろしく高い(イノベーション・ジャパンは無料)
2:幕張が遠い(下手したら片道3時間)
3:アカデミック系はちょっと場違い(今まで行った感じでは)
イノベーション・ジャパン2010の方は”大規模動的ネットワークの最適化モデリングと高速計算による解決”といった感じの内容にする予定(SDPなどは関係無い)。研究途中なので今年本当に出展するかは未定。
1:出展料が恐ろしく高い(イノベーション・ジャパンは無料)
2:幕張が遠い(下手したら片道3時間)
3:アカデミック系はちょっと場違い(今まで行った感じでは)
イノベーション・ジャパン2010の方は”大規模動的ネットワークの最適化モデリングと高速計算による解決”といった感じの内容にする予定(SDPなどは関係無い)。研究途中なので今年本当に出展するかは未定。
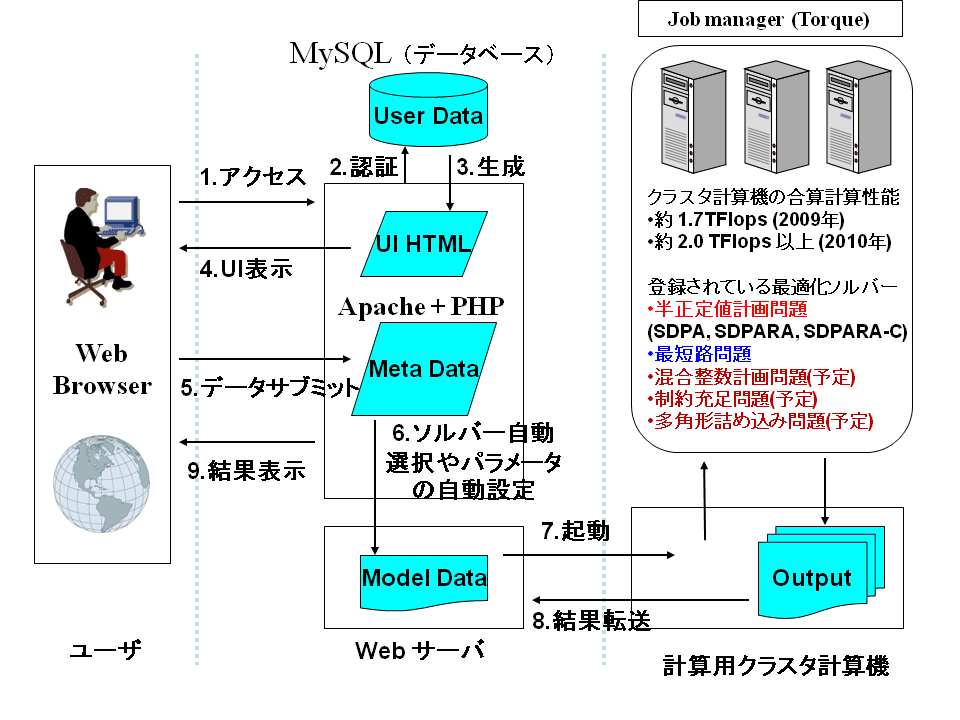
現在、新しい最適化問題用オンライン・ソルバーの開発が進んでいる。システム内容や画面についてはこちらのブログをご覧いただきたい。テキストファイルによる入出力、あるいは標準入出力を使うソフトウェアであれば、容易に追加できる仕様になっている。
添付の図にあるように現在、新しい最適化ソフトウェアの追加作業も行っている。このオンライン・ソルバーに追加した方が良いと思われる最適化ソフトウェアがあれば、ご要望等を送っていただきたい。
添付の図にあるように現在、新しい最適化ソフトウェアの追加作業も行っている。このオンライン・ソルバーに追加した方が良いと思われる最適化ソフトウェアがあれば、ご要望等を送っていただきたい。
SCOPE つくば合宿ですが、発表と宿泊申込の〆切が6月4日(金)となっております。発表や宿泊を考えておられる方はお忘れのないようにお願いします。
開催日 : 2010 年6月26日(土), 27日(日)
会 場 : 筑波大学 筑波キャンパス 春日地区 講堂
参加費 : 無料(ただし, 宿泊, 懇親会への参加は有料)
事前登録 : 不要(ただし, 筑波大学の宿泊施設利用希望の場合は必要)
[重要な日にち]
発表申込〆切 : 2010年6月4日(金)
宿泊申込〆切 : 2010年6月4日(金)
旅費補助申込〆切 : 2010年6月11日(金)
託児申込〆切 : 2010年6月17日(木)
SCOPE@つくば : 2010年6月26日(土), 27日(日)
開催日 : 2010 年6月26日(土), 27日(日)
会 場 : 筑波大学 筑波キャンパス 春日地区 講堂
参加費 : 無料(ただし, 宿泊, 懇親会への参加は有料)
事前登録 : 不要(ただし, 筑波大学の宿泊施設利用希望の場合は必要)
[重要な日にち]
発表申込〆切 : 2010年6月4日(金)
宿泊申込〆切 : 2010年6月4日(金)
旅費補助申込〆切 : 2010年6月11日(金)
託児申込〆切 : 2010年6月17日(木)
SCOPE@つくば : 2010年6月26日(土), 27日(日)
公開された記事には量子化学分野の超大規模SDPに対する計算時間が掲載されているが、こちらのクラスタでの計算結果と並べて掲載する。現在 SDPA 64bit 版で NH3 と H2O の計算を Dell の PowerEdge サーバ(1台)上で計算を行っている。スパコンやクラスタと比較した場合では大量の実行時間を要するものの、1台のサーバと SDPA 64bit 版で以下の全ての問題が解けそうである。この2ヶ月間の進歩は早いもので、今度どこかのスパコンで実行するときは、さらに巨大な問題に挑戦できるだろう。SDPARA の最新版を使いこなすのはスパコンと最適化の両方の知識と経験が必要なので難しいようだ。
京大 T2K スパコン(CPU x コア数) SDPA クラスタ(CPU x コア数)
1: H2O 27,523.8s(128 x 16) 49,037.9s(16 x 8)
2: NH3 68,593.4s(128 x 16) 146,763.2s(32 x 4)
3: CH3 72,025.6s(128 x 16) 154,043.3s(32 x 4)
4: O2 5,943.1s(128 x 16) 21,910.5s(64 x 2)
○ 京大 T2K スパコン
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
○ SDPA クラスタ
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.4 for x86_64
京大 T2K スパコン(CPU x コア数) SDPA クラスタ(CPU x コア数)
1: H2O 27,523.8s(128 x 16) 49,037.9s(16 x 8)
2: NH3 68,593.4s(128 x 16) 146,763.2s(32 x 4)
3: CH3 72,025.6s(128 x 16) 154,043.3s(32 x 4)
4: O2 5,943.1s(128 x 16) 21,910.5s(64 x 2)
○ 京大 T2K スパコン
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
○ SDPA クラスタ
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.4 for x86_64
7月10日に 2010 年度第2回の SCOPE 研究会を開催します。つくば合宿の2週間後ですが、こちらの研究会にも是非ご参加下さい。
2010年度 第2回研究会
日 時 : 2010年07月10日(土)14:00~
会 場 : 中央大学 後楽園キャンパス 6号館4階 6418号室
講演1
講演者 : 金森敬文氏 (名古屋大学 大学院情報科学研究科 計算機数理科学専攻)
講演題目 : 密度比の推定と計算 ―smoothed analysis からのアプローチ
講演概要:
2つの確率密度の比 (密度比) の推定は,機械学習における重要な課題のひと
つである.例えば,共変量シフト下での回帰分析,外れ値検出,ダイバージェ
ンス推定,条件付き確率密度の推定など,さまざまな統計的推論の問題が密度
比推定の枠組で定式化される.本発表では,密度比推定に対してカーネル関数
と最小2乗法を用いた学習アルゴリズムを提案し,その統計的ないし数値的性
質について考察する.計算効率や数値安定性などの性質は,計算対象となる関
数から定義される条件数と関係が深い.統計的推論においては,データがラン
ダムなので条件数もランダムな確率変数となる.ランダムネスのある状況下で,
学習アルゴリズムの計算効率を議論するために,計算量の分野で提案されてい
る "smoothed analysis" の考え方を利用する.この視点から,提案法は他の
方法と比べて,広いクラスの確率分布に対して条件数が小さな値に分布するこ
とを示す.これにより,提案法が大規模データに対して高い計算効率を持つこ
とが,理論的に裏付けられる.また,学習アルゴリズムを設計するための枠組
として,smoothed analysis の考え方を積極的に利用することの有用性につい
て,今後の可能性を探る.
講演2
講演者 : 安井雄一郎氏 (中央大学 理工学研究科 博士後期課程)
講演題目 : 大規模最短路問題に対するダイクストラ法の高速化
講演概要:
最短路問題はネットワーク上の経路探索などの多くの応用を持ち, また他の最適化
問題の子問題として用いられることも多く,適用範囲の広い組合せ最適化問題である.
そのため最短路問題を高速に解くことの重要性は非常に大きくなってきている.
最短路問題に対する解法にはダイクストラ法などの安定的かつ効率的な高速アルゴ
リズムが存在するが, 実問題は非常に大規模(約2,400万点, 約5,800万枝)になるため
高速化が不可欠である. そこで本研究では, バイナリ・ヒープを適用したダイクス
トラ法に対し,メモリ階層構造を考慮した汎用的かつ効率的な高速化を適用することで,
実行性能, グラフ特性に対する安定性, メモリ要求量, 並列実行など, 総合的に最も
優れたソルバーを開発することに成功した. 計算機上の律速箇所を解析するための
実験方法を合わせて示し, 本実装の有用性を裏付けていく.
2010年度 第2回研究会
日 時 : 2010年07月10日(土)14:00~
会 場 : 中央大学 後楽園キャンパス 6号館4階 6418号室
講演1
講演者 : 金森敬文氏 (名古屋大学 大学院情報科学研究科 計算機数理科学専攻)
講演題目 : 密度比の推定と計算 ―smoothed analysis からのアプローチ
講演概要:
2つの確率密度の比 (密度比) の推定は,機械学習における重要な課題のひと
つである.例えば,共変量シフト下での回帰分析,外れ値検出,ダイバージェ
ンス推定,条件付き確率密度の推定など,さまざまな統計的推論の問題が密度
比推定の枠組で定式化される.本発表では,密度比推定に対してカーネル関数
と最小2乗法を用いた学習アルゴリズムを提案し,その統計的ないし数値的性
質について考察する.計算効率や数値安定性などの性質は,計算対象となる関
数から定義される条件数と関係が深い.統計的推論においては,データがラン
ダムなので条件数もランダムな確率変数となる.ランダムネスのある状況下で,
学習アルゴリズムの計算効率を議論するために,計算量の分野で提案されてい
る "smoothed analysis" の考え方を利用する.この視点から,提案法は他の
方法と比べて,広いクラスの確率分布に対して条件数が小さな値に分布するこ
とを示す.これにより,提案法が大規模データに対して高い計算効率を持つこ
とが,理論的に裏付けられる.また,学習アルゴリズムを設計するための枠組
として,smoothed analysis の考え方を積極的に利用することの有用性につい
て,今後の可能性を探る.
講演2
講演者 : 安井雄一郎氏 (中央大学 理工学研究科 博士後期課程)
講演題目 : 大規模最短路問題に対するダイクストラ法の高速化
講演概要:
最短路問題はネットワーク上の経路探索などの多くの応用を持ち, また他の最適化
問題の子問題として用いられることも多く,適用範囲の広い組合せ最適化問題である.
そのため最短路問題を高速に解くことの重要性は非常に大きくなってきている.
最短路問題に対する解法にはダイクストラ法などの安定的かつ効率的な高速アルゴ
リズムが存在するが, 実問題は非常に大規模(約2,400万点, 約5,800万枝)になるため
高速化が不可欠である. そこで本研究では, バイナリ・ヒープを適用したダイクス
トラ法に対し,メモリ階層構造を考慮した汎用的かつ効率的な高速化を適用することで,
実行性能, グラフ特性に対する安定性, メモリ要求量, 並列実行など, 総合的に最も
優れたソルバーを開発することに成功した. 計算機上の律速箇所を解析するための
実験方法を合わせて示し, 本実装の有用性を裏付けていく.
しつこいようだが、mpack-0.6.6 の make の続き。我が家の Linux 仮想マシン軍団のメンバーはまだいるけれども、このくらいにしておく。
1: Momonga 6 + gcc 4.3.3 : 成功
2: Debian 504 + gcc 4.3.2 : 失敗
3: OpenSUSE 11.2 + gcc 4.4.1 : 成功
4: CentOS 4.8 + gcc 3.4.4(4.1.2) : 失敗
いろいろな Linux 上で SDPA などのサポートを行っているが、特に SDPARA の場合でかなり手こずるのが Ubuntu になる。クラスタ計算機に Ubuntu を入れるのはちょっと避けていただきたいところ。
1: Momonga 6 + gcc 4.3.3 : 成功
2: Debian 504 + gcc 4.3.2 : 失敗
3: OpenSUSE 11.2 + gcc 4.4.1 : 成功
4: CentOS 4.8 + gcc 3.4.4(4.1.2) : 失敗
いろいろな Linux 上で SDPA などのサポートを行っているが、特に SDPARA の場合でかなり手こずるのが Ubuntu になる。クラスタ計算機に Ubuntu を入れるのはちょっと避けていただきたいところ。
ずっと某スパコンと言ってきましたが、すでに結果等が公表されましたので、スパコン名も公表しますと京都大学 T2K スパコンになります。幾つか補足があります。
1:公表されている実行時間ですが、実行を開始してから合計 2048 コアを空いているノードから集めてくるようですので、この時間も最大で1時間ほどかかります。よって真の実行時間は公表値から 30 分から 1 時間を引いたものになります。スパコン自体は安定して動作していました。特定のノードや CPU が落ちて再実験の行うような事態は起こりませんでした。
2:今回解いた量子化学の問題では等式制約を二つの不等式制約に分解して組み入れていますが、この部分が対角部分(LPブロック)に入るので数値精度的な悪影響は少ないと推定されます。実際に大変精度良く最適解を求めることができました。
3:今回は期間的な都合上、性能効率を探る実験はほとんど出来ませんでした。しかし、この CPU(AMD Opteron)や HyperTransport の性能上それほど性能効率は高く無いかもしれません。Intel Xeon (特に Nehalem 以降)の方が性能効率は良さそうです。
1:公表されている実行時間ですが、実行を開始してから合計 2048 コアを空いているノードから集めてくるようですので、この時間も最大で1時間ほどかかります。よって真の実行時間は公表値から 30 分から 1 時間を引いたものになります。スパコン自体は安定して動作していました。特定のノードや CPU が落ちて再実験の行うような事態は起こりませんでした。
2:今回解いた量子化学の問題では等式制約を二つの不等式制約に分解して組み入れていますが、この部分が対角部分(LPブロック)に入るので数値精度的な悪影響は少ないと推定されます。実際に大変精度良く最適解を求めることができました。
3:今回は期間的な都合上、性能効率を探る実験はほとんど出来ませんでした。しかし、この CPU(AMD Opteron)や HyperTransport の性能上それほど性能効率は高く無いかもしれません。Intel Xeon (特に Nehalem 以降)の方が性能効率は良さそうです。
やっと終わった。48反復と思ったよりも長くかかってしまった。
76554 (= mDIM)
22 (= nBLOCK)
18 18 18 18 153 153 324 153 153 324 648 324 324 816 2754 2754 816 8604 8604 2754 2754 -694 (= bLOCKsTRUCT)
48 3.8e-11 3.8e-11 4.7e-14 -9.10e+01 -9.10e+01 1.4e-01 1.2e-01 1.00e-01
phase.value = pdOPT
mDIM の大きな問題なので相変わらず F3 の計算時間がほとんどを占めている。
Make bF3 time = 1495391.534023, 96.188692
CentOS を 5.4 から 5.5 にバージョンアップする過程でクラスタ計算機の一部が壊れてしまったので、壊れたノードだけ再インストールを行い、現在別の大きな SDP の実験を継続中。
76554 (= mDIM)
22 (= nBLOCK)
18 18 18 18 153 153 324 153 153 324 648 324 324 816 2754 2754 816 8604 8604 2754 2754 -694 (= bLOCKsTRUCT)
48 3.8e-11 3.8e-11 4.7e-14 -9.10e+01 -9.10e+01 1.4e-01 1.2e-01 1.00e-01
phase.value = pdOPT
mDIM の大きな問題なので相変わらず F3 の計算時間がほとんどを占めている。
Make bF3 time = 1495391.534023, 96.188692
CentOS を 5.4 から 5.5 にバージョンアップする過程でクラスタ計算機の一部が壊れてしまったので、壊れたノードだけ再インストールを行い、現在別の大きな SDP の実験を継続中。




