








昨日の続きで、roll3000.mps の問題に対して、スレッド数 2, 4, 8, 16, 32, 48 でそれぞれ7回ずつ計算を行った。現時点では特に統計処理は行っていないで、結果のみを掲載した。
2スレッド
1 : 5897.00
2 : 5787.80
3 : 6236.59
4 : 6041.58
5 : 5804.74
6 : 5994.20
7 : 5760.94
4スレッド
1 : 1437.00
2 : 2853.85
3 : 4183.15
4 : 2986.87
5 : 2927.55
6 : 2826.98
7 : 3167.58
8スレッド
1 : 3044.85
2 : 2485.03
3 : 1125.37
4 : 1055.43
5 : 965.62
6 : 1163.85
7 : 1523.26
16スレッド
1 : 406.17
2 : 837.75
3 : 2117.94
4 : 606.44
5 : 450.79
6 : 1675.71
7 : 1094.18
32スレッド
1 : 2479.35
2 : 1998.15
3 : 1803.23
4 : 1542.21
5 : 2403.46
6 : 3262.99
7 : 2516.65
48スレッド
1 : 5270.78
2 : 4389.12
3 : 6695.13
4 : 6877.30
5 : 4610.14
6 : 5493.50
7 : 6990.08
○計算サーバ (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4
Memory : 256GB (16 x 16GB / 1066MHz)
OS : Fedora 15 for x86_64
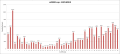
○参考:1から48スレッドまでの結果
2スレッド
1 : 5897.00
2 : 5787.80
3 : 6236.59
4 : 6041.58
5 : 5804.74
6 : 5994.20
7 : 5760.94
4スレッド
1 : 1437.00
2 : 2853.85
3 : 4183.15
4 : 2986.87
5 : 2927.55
6 : 2826.98
7 : 3167.58
8スレッド
1 : 3044.85
2 : 2485.03
3 : 1125.37
4 : 1055.43
5 : 965.62
6 : 1163.85
7 : 1523.26
16スレッド
1 : 406.17
2 : 837.75
3 : 2117.94
4 : 606.44
5 : 450.79
6 : 1675.71
7 : 1094.18
32スレッド
1 : 2479.35
2 : 1998.15
3 : 1803.23
4 : 1542.21
5 : 2403.46
6 : 3262.99
7 : 2516.65
48スレッド
1 : 5270.78
2 : 4389.12
3 : 6695.13
4 : 6877.30
5 : 4610.14
6 : 5493.50
7 : 6990.08
○計算サーバ (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4
Memory : 256GB (16 x 16GB / 1066MHz)
OS : Fedora 15 for x86_64
○参考:1から48スレッドまでの結果












2スレッドの計算時間と逐次版の計算時間の差が,本質的なオーバーヘッドのような気がします.そもそもオーバーヘッドは大きいはずです.このぐらいオーバーヘッドがあっても,探索に関連した種々のアルゴリズムの工夫で,それなりに速くできる可能性があるというのは朗報です(これは1インスタンスに限らず,MIPLIB2010のベンチマークインスタンス全体でも,多少は速くなりました.全インスタンスに対して,4スレッドと8スレッドで7回実験した結果の平均で評価しました).
この結果で気になるのは3スレッドの結果です.これはたまたま運が悪かったのか,あるいは,かなりの頻度で起こり得るのか知りたいです.申し訳ないですが,3スレッドも,あと6回実験してみて頂けないでしょうか?
SDPAはコア数に応じて,確実に加速する理想的な状態で実装されているようですね.Gurobiでの実験でもわかるように,MIPソルバではあり得ないです.それでも理想とする動作状態というのはあるので,そこを目指して頑張ります.先はまだまだ長そうです.
この問題(roll3000.mps)は小さい方だと思いますので、もっと大きな問題では多数コアの効果が見えてくるのではないでしょうか?
> 3スレッドも,あと6回実験してみて頂けないでしょうか?
今実験中ですが、Magny-Cours 48 コアマシンは計算需要が大きいので、他の研究の実験も行う必要があります。Affinity の実験を含めて Instanbul 24 コアマシンで実験を行ってもよろしいでしょうか?
> SDPAはコア数に応じて,確実に加速する理想的な状態で実装されているようですね.
加速率はともかく解きたい問題の大きさに対する絶対性能がまだ足りません。アイデアはいろいろありますので、こちらも頑張ります。
あと実験ですが,もちろんそちらの実験を優先してください.MIPの実験は急がないでも良いですし,そちらの実験の都合で,いくらでも遅らせてもらって良いです.現在,行って頂いた実験だけで十分助かりました.
今後の実験ですが,遅くなって良いので,48コアで行ってみて頂けないでしょうか.32コアまでの実験であれば,古い上に色々と大変なことはあっても,こちらの環境で都合をつけて試せると思います.