◯アルゴリズムによる高速化と計算機による高速化が明確に分離(区別)することが出来なくなった. つまり最新のアルゴリズムでは最新の計算機アーキテクチャでの実行を前提としたものが増えてきている.
◯計算量による理論的解析の優劣とソフトウェア実装後に計算機で実行したときの計算結果が大きく異なるという現象が見られる.その理由としては以下のような原因が考えられる
◯理論的な解析時に想定されている最悪な場合という現象が計算機上で扱うことのできる問題の範囲では起こらない. 例えば,現在の計算機においては整数型の変数は大きくても $2^{64}-1$ であるので,計算機で扱うことができる範囲では $\log_2 n$関数は大きくても 64 程度である(つまり定数とみなすこともできる).
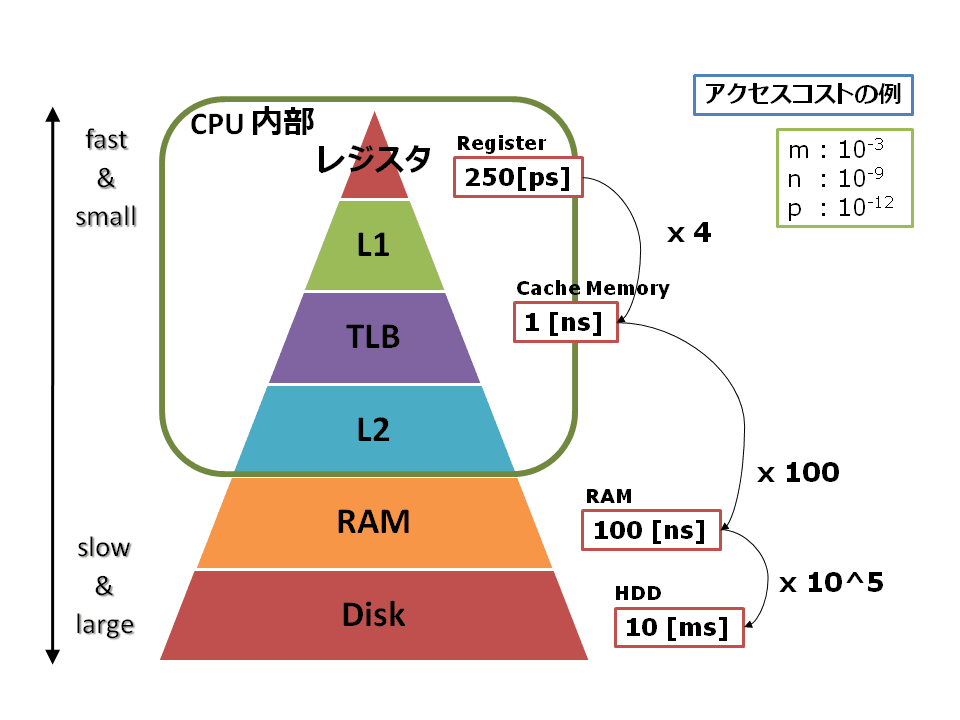
◯計算量の評価において,演算量とデータ移動量が混同されている(一般的には後者の方がコストが高い).

◯計算量による理論的解析の優劣とソフトウェア実装後に計算機で実行したときの計算結果が大きく異なるという現象が見られる.その理由としては以下のような原因が考えられる
◯理論的な解析時に想定されている最悪な場合という現象が計算機上で扱うことのできる問題の範囲では起こらない. 例えば,現在の計算機においては整数型の変数は大きくても $2^{64}-1$ であるので,計算機で扱うことができる範囲では $\log_2 n$関数は大きくても 64 程度である(つまり定数とみなすこともできる).
◯計算量の評価において,演算量とデータ移動量が混同されている(一般的には後者の方がコストが高い).