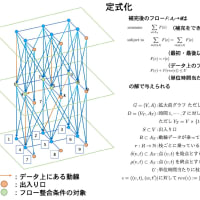
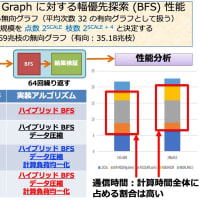
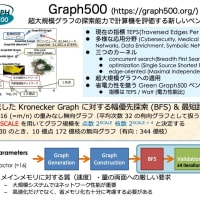
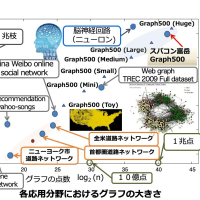
昨年、京大 T2K スパコンで実行した結果を再度解析中。データ量が非常に多いので大変だが、一番困るのはやり直しの実験が出来ないこと。
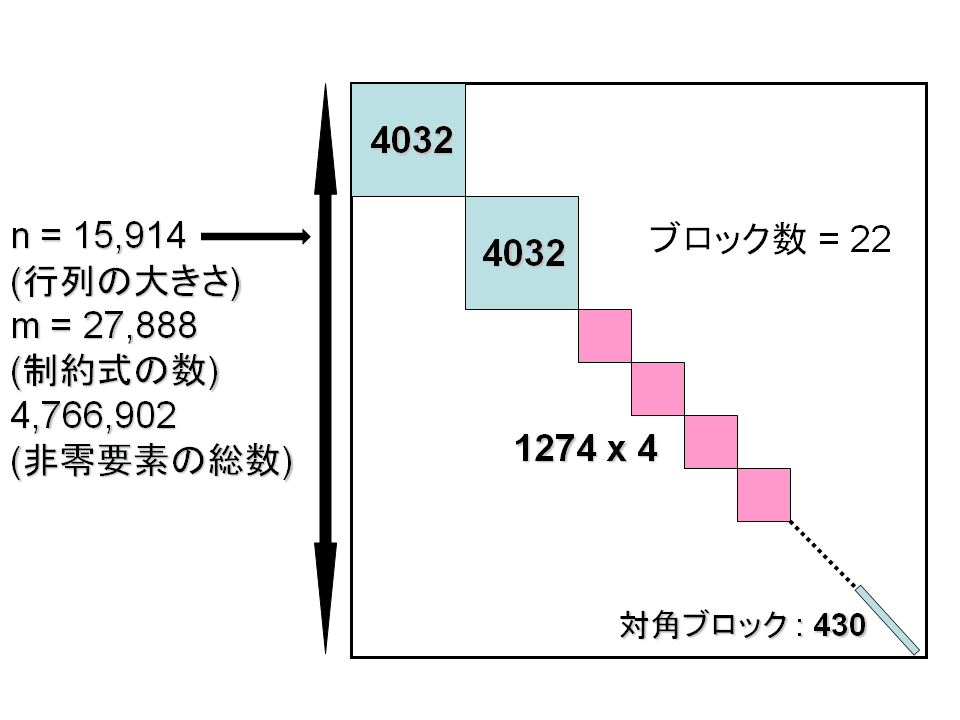
問題名 : H2O.1A1.DZ.pqgt1t2p.dat-s

○ 京大 T2K スパコン
○ELEMENTS : 25198.24秒
○CHOLESKY : 284.34秒
○全体:27523.88秒
○ OPT クラスタ
○ELEMENTS : 21582.47秒
○CHOLESKY : 370.74秒
○全体:22988.00秒
ELEMENTS の部分はコア数が増えれば基本的に性能が上がっていく種類の計算なので、CPU もクロック周波数も異なるとは言え 2048 コア時の計算が、192 コア時の計算よりも遅くなるというのはちょっと考えにくい。多分、もう一回実行できれば事情はかなり異なってくると思われるが、そこまでする価値は無いものと判断する。
○ OPT クラスタ
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.6 for x86_64
○ 京大 T2K スパコン
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64
問題名 : H2O.1A1.DZ.pqgt1t2p.dat-s
○ 京大 T2K スパコン
○ELEMENTS : 25198.24秒
○CHOLESKY : 284.34秒
○全体:27523.88秒
○ OPT クラスタ
○ELEMENTS : 21582.47秒
○CHOLESKY : 370.74秒
○全体:22988.00秒
ELEMENTS の部分はコア数が増えれば基本的に性能が上がっていく種類の計算なので、CPU もクロック周波数も異なるとは言え 2048 コア時の計算が、192 コア時の計算よりも遅くなるというのはちょっと考えにくい。多分、もう一回実行できれば事情はかなり異なってくると思われるが、そこまでする価値は無いものと判断する。
○ OPT クラスタ
1:PowerEdge M1000e(ブレードエンクロージャー) x 1台
2:PowerEdge M710HD(ブレードサーバ) x 16台
ブレードサーバの仕様:
CPU : インテル(R) Xeon(R) プロセッサー X5670(2.93GHz、12MB キャッシュ、6.4 GT/s QPI) x 2個
メモリ: 128GB (16X8GB/2R/1333MHz/DDR3 RDIMM/CPUx2)
Disk : 73GB x 2(1台のみ 300GB x 2)
NIC : GbE x 1 & Inifiniband QDR(40Gbps) x 1
OS : CentOS 5.6 for x86_64
○ 京大 T2K スパコン
128 Nodes, 512 CPUs, 2048 CPU cores; (今回使用した分のみ)
CPU : AMD Opteron 8356 2.3GHz (quad cores) x 4 / node
Memory 32GB / node
NIC : GbE x 2 and Infiniband x 4 / node
OS : RHEL 4.x for x86_64