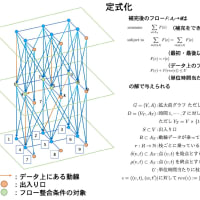
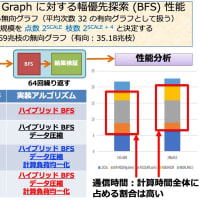
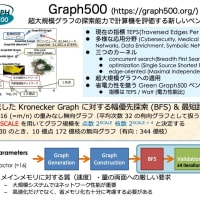
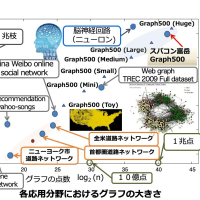
前回の SDPA に関する数値実験で何故24コアもある計算サーバ1が8コアの計算サーバ2に負けるのかという問題があるので、もう少し詳しく調べてみた。
ソフトウェア
○: SDPA 7.3.2β : GotoBLAS2 1.09 + MUMPS 4.9.2
○計算サーバ1
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
gcc : 4.4.2
OS : Fedora 12 for x86_64
環境変数 : OMP_NUM_THREADS = 24
○計算サーバ2
CPU : Intel Xeon 5550 (2.66GHz / 8MB L3) x 2
Memory : 72GB (18 x 4GB / 800MHz)
gcc : 4.4.2
OS : Fedora 12 for x86_64
環境変数 : OMP_NUM_THREADS = 8
●問題1 : FH2+.1A1.STO6G.pqgt1t2p.dat-s
計算サーバ1 : 66.1s(30回) 24スレッド
計算サーバ2 : 96.4s(30回) 8 スレッド
F3 式の計算にかかる時間は
計算サーバ1 : 76.9s (24スレッド合計)
計算サーバ2 : 135.1s (8スレッド合計)
となっていて、これは明らかに CPU 数が4個あって、メモリチャンネルも多い計算サーバ1の方が有利になる。
●問題2 : mcp2000-01.dat-s
計算サーバ1 : 95.9s(16回) 24スレッド
計算サーバ2 : 46.2s(16回) 8 スレッド
例えば固有値計算などでは以下のような差が付いている。
計算サーバ1 : 14.7s (24スレッド合計)
計算サーバ2 : 5.4s (8スレッド合計)
●問題3 : thetaG51.dat-s
計算サーバ1 : 118.8s(28回) 24スレッド
計算サーバ2 : 83.6s(28回) 8 スレッド
F3 式の計算にかかる時間は
計算サーバ1 : 35.3s (24スレッド合計)
計算サーバ2 : 65.1s (8スレッド合計)
また Cholesky 分解にかかる時間は
計算サーバ1 : 66.9s (24スレッド合計)
計算サーバ2 : 43.4s (8スレッド合計)
となっている。
F3 式のようにコア単位で独立かつ並列に計算できる部分に関しては、Istanbul 24 コアが有利で、行列積のように全てのコアを用いて計算する場合には Nehalem-ep 8 コアの方が速い。
ソフトウェア
○: SDPA 7.3.2β : GotoBLAS2 1.09 + MUMPS 4.9.2
○計算サーバ1
CPU : AMD Opteron 8439 (2.80GHz / 6MB L3) x 4
Memory : 128GB (32 x 4GB / 800MHz)
gcc : 4.4.2
OS : Fedora 12 for x86_64
環境変数 : OMP_NUM_THREADS = 24
○計算サーバ2
CPU : Intel Xeon 5550 (2.66GHz / 8MB L3) x 2
Memory : 72GB (18 x 4GB / 800MHz)
gcc : 4.4.2
OS : Fedora 12 for x86_64
環境変数 : OMP_NUM_THREADS = 8
●問題1 : FH2+.1A1.STO6G.pqgt1t2p.dat-s
計算サーバ1 : 66.1s(30回) 24スレッド
計算サーバ2 : 96.4s(30回) 8 スレッド
F3 式の計算にかかる時間は
計算サーバ1 : 76.9s (24スレッド合計)
計算サーバ2 : 135.1s (8スレッド合計)
となっていて、これは明らかに CPU 数が4個あって、メモリチャンネルも多い計算サーバ1の方が有利になる。
●問題2 : mcp2000-01.dat-s
計算サーバ1 : 95.9s(16回) 24スレッド
計算サーバ2 : 46.2s(16回) 8 スレッド
例えば固有値計算などでは以下のような差が付いている。
計算サーバ1 : 14.7s (24スレッド合計)
計算サーバ2 : 5.4s (8スレッド合計)
●問題3 : thetaG51.dat-s
計算サーバ1 : 118.8s(28回) 24スレッド
計算サーバ2 : 83.6s(28回) 8 スレッド
F3 式の計算にかかる時間は
計算サーバ1 : 35.3s (24スレッド合計)
計算サーバ2 : 65.1s (8スレッド合計)
また Cholesky 分解にかかる時間は
計算サーバ1 : 66.9s (24スレッド合計)
計算サーバ2 : 43.4s (8スレッド合計)
となっている。
F3 式のようにコア単位で独立かつ並列に計算できる部分に関しては、Istanbul 24 コアが有利で、行列積のように全てのコアを用いて計算する場合には Nehalem-ep 8 コアの方が速い。