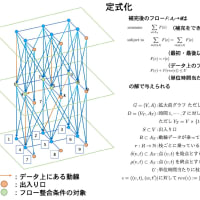
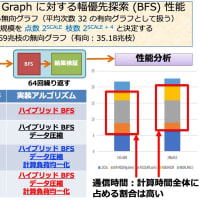
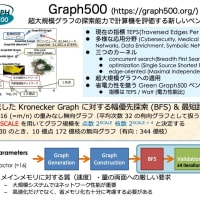
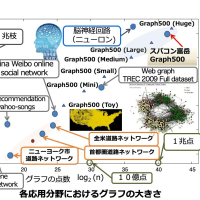
numactl コマンドを用いて以下のように 16, 32, 64, 128 プロセスで SDPARA を実行してみよう。問題(SDP)は非常に疎なものを選んでいるので、Schur complemet matrix は全て F3 式で計算を行う。
1: time mpiexec -n 16 numactl --physcpubind=0 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.16.0
250.810 秒
2: time mpiexec -n 32 numactl --physcpubind=0,4 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.32.0.4
275.275 秒
3: time mpiexec -n 32 numactl --physcpubind=0,2 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.32.0.2
271.435 秒
4: time mpiexec -n 32 numactl --physcpubind=0,1 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.32.0.1
255.364 秒
5: time mpiexec -n 64 numactl --physcpubind=0,4,2,6 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.64.0.4.2.6
335.994 秒
6: time mpiexec -n 64 numactl --physcpubind=0,4,1,5 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.64.0.4.1.5
302.228 秒
7: time mpiexec -n 64 numactl --physcpubind=0,2,1,3 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.64.0.2.1.3
295.312 秒
8: time mpiexec -n 128 numactl --physcpubind=0,1,2,3,4,5,6,7 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.128
398.540 秒
ほぼ予想通りの結果。全て F3 式で計算の場合は、プロセス数を増やしても L2 キャッシュなどのリソースを食い合うので速くはならない。また、プロセスを振り分けるときは、なるべく異なる CPU あるいは, L2 キャッシュを共有しないコアを使うようにする。
1: time mpiexec -n 16 numactl --physcpubind=0 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.16.0
250.810 秒
2: time mpiexec -n 32 numactl --physcpubind=0,4 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.32.0.4
275.275 秒
3: time mpiexec -n 32 numactl --physcpubind=0,2 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.32.0.2
271.435 秒
4: time mpiexec -n 32 numactl --physcpubind=0,1 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.32.0.1
255.364 秒
5: time mpiexec -n 64 numactl --physcpubind=0,4,2,6 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.64.0.4.2.6
335.994 秒
6: time mpiexec -n 64 numactl --physcpubind=0,4,1,5 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.64.0.4.1.5
302.228 秒
7: time mpiexec -n 64 numactl --physcpubind=0,2,1,3 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.64.0.2.1.3
295.312 秒
8: time mpiexec -n 128 numactl --physcpubind=0,1,2,3,4,5,6,7 ./sdpara.mpich2.goto ~/data/mcp2000-10.dat-s out.mcp2000.128
398.540 秒
ほぼ予想通りの結果。全て F3 式で計算の場合は、プロセス数を増やしても L2 キャッシュなどのリソースを食い合うので速くはならない。また、プロセスを振り分けるときは、なるべく異なる CPU あるいは, L2 キャッシュを共有しないコアを使うようにする。