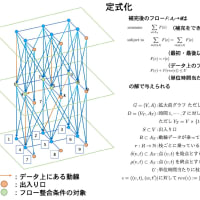
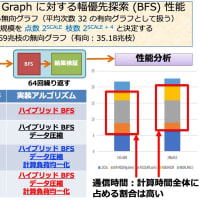
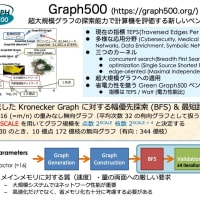
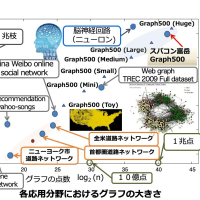
SDPA Ver.7 の方は一応 7.0.5 で固定ということになり、マニュアルの作成を含めて公開準備が進んでいる。それとは別にアルゴリズムにはほとんど変更を加えないで高速化を目指す改造作業が進んでいる。
当面の作業内容としてはデータの流れやメモリアクセスの整理ということで、特に疎行列のデータ構造とアクセス方法を変えている。疎行列と言っても以下の2種類がある。
1: 入力データの中の行列部分
2: Shur complement 行列を疎行列として保持する場合
現在では 1 も 2 も同じデータ構造を用いているが、疎行列ということで一要素につき、行番号(int)、列番号(int)、要素の値(double) という三つのデータ(合計 16byte)がある。今までは行番号、列番号、要素の値を別々の三つの配列として保持していたが、これを1要素について三つをパックした構造体を作り行番号 → 列番号 → 要素の値とメモリ上に連続して配置するように変更している(その後で要素数だけ構造体の配列を作る)。上記の 1 の場合では、行番号 = 列番号のときは予め要素の値を 1/2 にしておくと計算の記述が簡潔になるが、2 の場合では 1/2 にしない方が良い。
この工夫から問題によっては結構高速に解けるようになる。現在デバッグ中だが、ほぼバグは出尽くした模様だ。
当面の作業内容としてはデータの流れやメモリアクセスの整理ということで、特に疎行列のデータ構造とアクセス方法を変えている。疎行列と言っても以下の2種類がある。
1: 入力データの中の行列部分
2: Shur complement 行列を疎行列として保持する場合
現在では 1 も 2 も同じデータ構造を用いているが、疎行列ということで一要素につき、行番号(int)、列番号(int)、要素の値(double) という三つのデータ(合計 16byte)がある。今までは行番号、列番号、要素の値を別々の三つの配列として保持していたが、これを1要素について三つをパックした構造体を作り行番号 → 列番号 → 要素の値とメモリ上に連続して配置するように変更している(その後で要素数だけ構造体の配列を作る)。上記の 1 の場合では、行番号 = 列番号のときは予め要素の値を 1/2 にしておくと計算の記述が簡潔になるが、2 の場合では 1/2 にしない方が良い。
この工夫から問題によっては結構高速に解けるようになる。現在デバッグ中だが、ほぼバグは出尽くした模様だ。