








Dell の PowerEdge のマニュアルには Node Interleaving について以下のように書いてある。
Node Interleaving
対称的なメモリ構成の場合、このフィールドが有効に設定されていると、メモリのインタリービングがサポートされます。このファイルが無効(デフォルト)に設定されていると、システムは NUMA(Non-Uniform Memory Architecture)(非対称)メモリ構成をサポートします。
メモ: 冗長メモリ機能を使用する際には、Node Interleaving(ノードのインタリービング)フィールドは Disabled(無効)に設定する必要があります。
-----------------------------------------------------------------------------------------------------------------------------------------------
そこで Magny-Cours 48 コアサーバで Node Interleaving 機能を ON と OFF の両方に設定して SDPA の比較実験を行なった。numactl コマンドなどの組み合わせが絡んでくると少し複雑になるのだが、この場合では明らかに Node Interleaving 機能を ON にした方が得になる。ただし、両者とも HT Assist は ON にしている。
○ソフトウェア SDPA 7.4β
○問題 : theta6.dat-s
Node Interleaving ON : 13.8秒
Node Interleaving OFF : 24.8秒
○問題 : Be.1S.SV.pqgt1t2p.dat-s
Node Interleaving ON : 11分30秒
Node Interleaving OFF : 18分4秒
○問題 : nug12_r2.dat-s
Node Interleaving ON : 2分15秒
Node Interleaving OFF : 4分35秒
○計算サーバ (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4個
メモリ : 256GB (16 x 16GB / 1066MHz)
OS : Fedora 15 for x86_64
Node Interleaving
対称的なメモリ構成の場合、このフィールドが有効に設定されていると、メモリのインタリービングがサポートされます。このファイルが無効(デフォルト)に設定されていると、システムは NUMA(Non-Uniform Memory Architecture)(非対称)メモリ構成をサポートします。
メモ: 冗長メモリ機能を使用する際には、Node Interleaving(ノードのインタリービング)フィールドは Disabled(無効)に設定する必要があります。
-----------------------------------------------------------------------------------------------------------------------------------------------
そこで Magny-Cours 48 コアサーバで Node Interleaving 機能を ON と OFF の両方に設定して SDPA の比較実験を行なった。numactl コマンドなどの組み合わせが絡んでくると少し複雑になるのだが、この場合では明らかに Node Interleaving 機能を ON にした方が得になる。ただし、両者とも HT Assist は ON にしている。
○ソフトウェア SDPA 7.4β
○問題 : theta6.dat-s
Node Interleaving ON : 13.8秒
Node Interleaving OFF : 24.8秒
○問題 : Be.1S.SV.pqgt1t2p.dat-s
Node Interleaving ON : 11分30秒
Node Interleaving OFF : 18分4秒
○問題 : nug12_r2.dat-s
Node Interleaving ON : 2分15秒
Node Interleaving OFF : 4分35秒
○計算サーバ (4 CPU x 12 コア = 48 コア)
CPU : AMD Opteron 6174 (2.20GHz / 12MB L3) x 4個
メモリ : 256GB (16 x 16GB / 1066MHz)
OS : Fedora 15 for x86_64



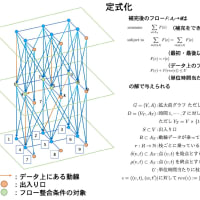


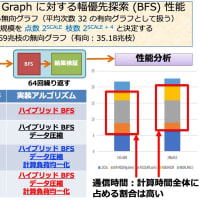
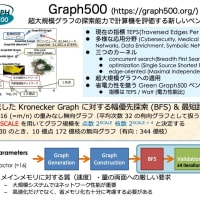

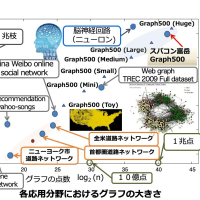





また node interleave の方が性能が良いということは、実は最適化が不十分である場合が多いです。
ただし、解く問題によって特性が異なるので、汎用的な調整は難しそうに見えます。