








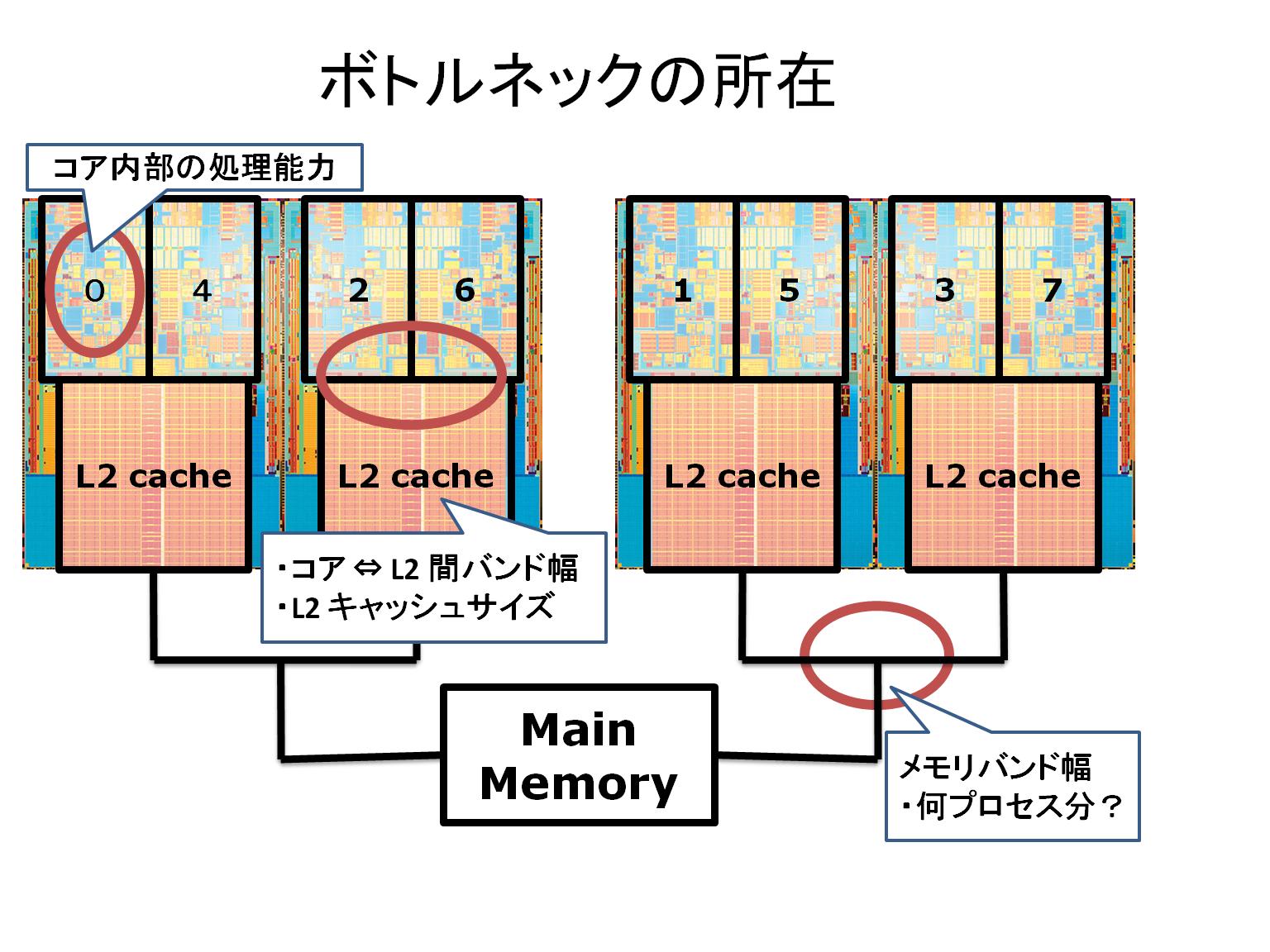
OpenMP の実行時の環境変数 KMP_AFFINITY について, 添付図のような構成を持つ Intel Xeon 5460 (3.16GHz : Penryn コア) x 2 を用いて調べてみる。コア番号は 0,1,2,3,4,5,6,7 と順番に並んでいるのではなく、下記のように 0,4,2,6,1,5,3,7 と並んでいる。
OMP: Info #168: KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 4 maps to package 0 core 1 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 2 maps to package 0 core 2 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 6 maps to package 0 core 3 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 1 maps to package 1 core 0 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 5 maps to package 1 core 1 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 3 maps to package 1 core 2 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 7 maps to package 1 core 3 [thread 0]
1: export KMP_AFFINITY=verbose,compact
compact オプションでは、コアを近い順に 0 から割り振っていくので、以下のように 0,4,2,6,1,5,3,7 となる。
OMP: Info #147: KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
OMP: Info #147: KMP_AFFINITY: Internal thread 1 bound to OS proc set {4}
OMP: Info #147: KMP_AFFINITY: Internal thread 2 bound to OS proc set {2}
OMP: Info #147: KMP_AFFINITY: Internal thread 3 bound to OS proc set {6}
OMP: Info #147: KMP_AFFINITY: Internal thread 4 bound to OS proc set {1}
OMP: Info #147: KMP_AFFINITY: Internal thread 5 bound to OS proc set {5}
OMP: Info #147: KMP_AFFINITY: Internal thread 6 bound to OS proc set {3}
OMP: Info #147: KMP_AFFINITY: Internal thread 7 bound to OS proc set {7}
2: export KMP_AFFINITY=verbose,scatter
scatter は、スレッドが以下のように均等に割り振られる。ところが、Nehalem や Istanbul などでは 4つのコアが一つの3次キャッシュを共有しているのに対して、Penryn は添付の図のように、例えば 0 と 4 が2次キャッシュを共有しているので、この型の CPU では 0,1,2,3,4,5,6,7 という順番で割り振った方が良いだろう。
OMP: Info #147: KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
OMP: Info #147: KMP_AFFINITY: Internal thread 1 bound to OS proc set {1}
OMP: Info #147: KMP_AFFINITY: Internal thread 2 bound to OS proc set {4}
OMP: Info #147: KMP_AFFINITY: Internal thread 3 bound to OS proc set {5}
OMP: Info #147: KMP_AFFINITY: Internal thread 7 bound to OS proc set {7}
OMP: Info #147: KMP_AFFINITY: Internal thread 4 bound to OS proc set {2}
OMP: Info #147: KMP_AFFINITY: Internal thread 5 bound to OS proc set {3}
OMP: Info #147: KMP_AFFINITY: Internal thread 6 bound to OS proc set {6}
OMP: Info #168: KMP_AFFINITY: OS proc 0 maps to package 0 core 0 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 4 maps to package 0 core 1 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 2 maps to package 0 core 2 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 6 maps to package 0 core 3 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 1 maps to package 1 core 0 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 5 maps to package 1 core 1 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 3 maps to package 1 core 2 [thread 0]
OMP: Info #168: KMP_AFFINITY: OS proc 7 maps to package 1 core 3 [thread 0]
1: export KMP_AFFINITY=verbose,compact
compact オプションでは、コアを近い順に 0 から割り振っていくので、以下のように 0,4,2,6,1,5,3,7 となる。
OMP: Info #147: KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
OMP: Info #147: KMP_AFFINITY: Internal thread 1 bound to OS proc set {4}
OMP: Info #147: KMP_AFFINITY: Internal thread 2 bound to OS proc set {2}
OMP: Info #147: KMP_AFFINITY: Internal thread 3 bound to OS proc set {6}
OMP: Info #147: KMP_AFFINITY: Internal thread 4 bound to OS proc set {1}
OMP: Info #147: KMP_AFFINITY: Internal thread 5 bound to OS proc set {5}
OMP: Info #147: KMP_AFFINITY: Internal thread 6 bound to OS proc set {3}
OMP: Info #147: KMP_AFFINITY: Internal thread 7 bound to OS proc set {7}
2: export KMP_AFFINITY=verbose,scatter
scatter は、スレッドが以下のように均等に割り振られる。ところが、Nehalem や Istanbul などでは 4つのコアが一つの3次キャッシュを共有しているのに対して、Penryn は添付の図のように、例えば 0 と 4 が2次キャッシュを共有しているので、この型の CPU では 0,1,2,3,4,5,6,7 という順番で割り振った方が良いだろう。
OMP: Info #147: KMP_AFFINITY: Internal thread 0 bound to OS proc set {0}
OMP: Info #147: KMP_AFFINITY: Internal thread 1 bound to OS proc set {1}
OMP: Info #147: KMP_AFFINITY: Internal thread 2 bound to OS proc set {4}
OMP: Info #147: KMP_AFFINITY: Internal thread 3 bound to OS proc set {5}
OMP: Info #147: KMP_AFFINITY: Internal thread 7 bound to OS proc set {7}
OMP: Info #147: KMP_AFFINITY: Internal thread 4 bound to OS proc set {2}
OMP: Info #147: KMP_AFFINITY: Internal thread 5 bound to OS proc set {3}
OMP: Info #147: KMP_AFFINITY: Internal thread 6 bound to OS proc set {6}











GotoBLAS では内部でこの設定を検出してベストな状態になるように Affinity を設定しています(ディフォルトではバンド幅を稼ぐ方向で設定しています)。残念ながら、100% 正しいわけではありません。
本当はアプリケーション側が完全な制御を行うべきなのですが、誰もやってくれないというが現実です。