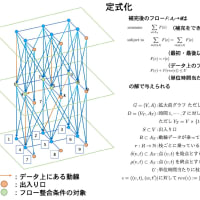
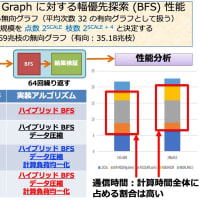
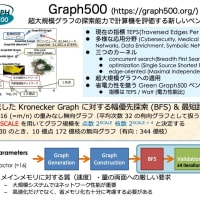
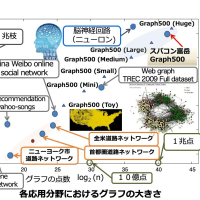
以前 AIST Super Cluster で Opteron 2.0GHz の CPU を 256 台用いて MPI で並列計算を行ったが(ノード間は Myrinet 2000 で接続)、この場合のピーク性能は 2.0GHz × 2 命令/クロック × 256 台でちょうど 1TFlops になる。1TFlops での計算は世界観を変えるに十分だった。今まで数日以上かかった計算が数時間で終わってしまう。このぐらいだとパラメータを変えて解き直してみようかという気分になる。
今後は 1チップで 1TFlops を目指していく動きが増えそうだ。現在 Cell だと 4GHz、8コアで 256GFlops なので(ただし単精度)、いずれ登場が予定されている 2PPE, 32コアの Cell ではちょうど SPE だけでも 1TFlops になる(倍精度演算がどうなるかは不明)。Intel の Larrabee も1チップで 1TFlops を目指すことになるだろう。1 チップで 1TFlops と 多数ノードで 1TFlops はまた意味が違うのだが、最適化分野としてもこれからに期待するところ大である。
今後は 1チップで 1TFlops を目指していく動きが増えそうだ。現在 Cell だと 4GHz、8コアで 256GFlops なので(ただし単精度)、いずれ登場が予定されている 2PPE, 32コアの Cell ではちょうど SPE だけでも 1TFlops になる(倍精度演算がどうなるかは不明)。Intel の Larrabee も1チップで 1TFlops を目指すことになるだろう。1 チップで 1TFlops と 多数ノードで 1TFlops はまた意味が違うのだが、最適化分野としてもこれからに期待するところ大である。