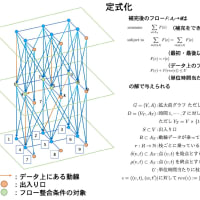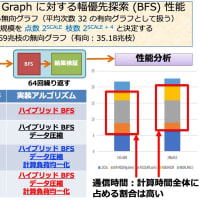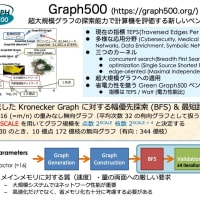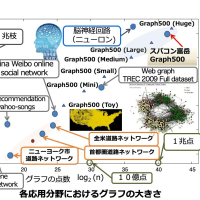
またまた前回の続きで今度は 32 MPI x 4 Pthread の結果も追加した。
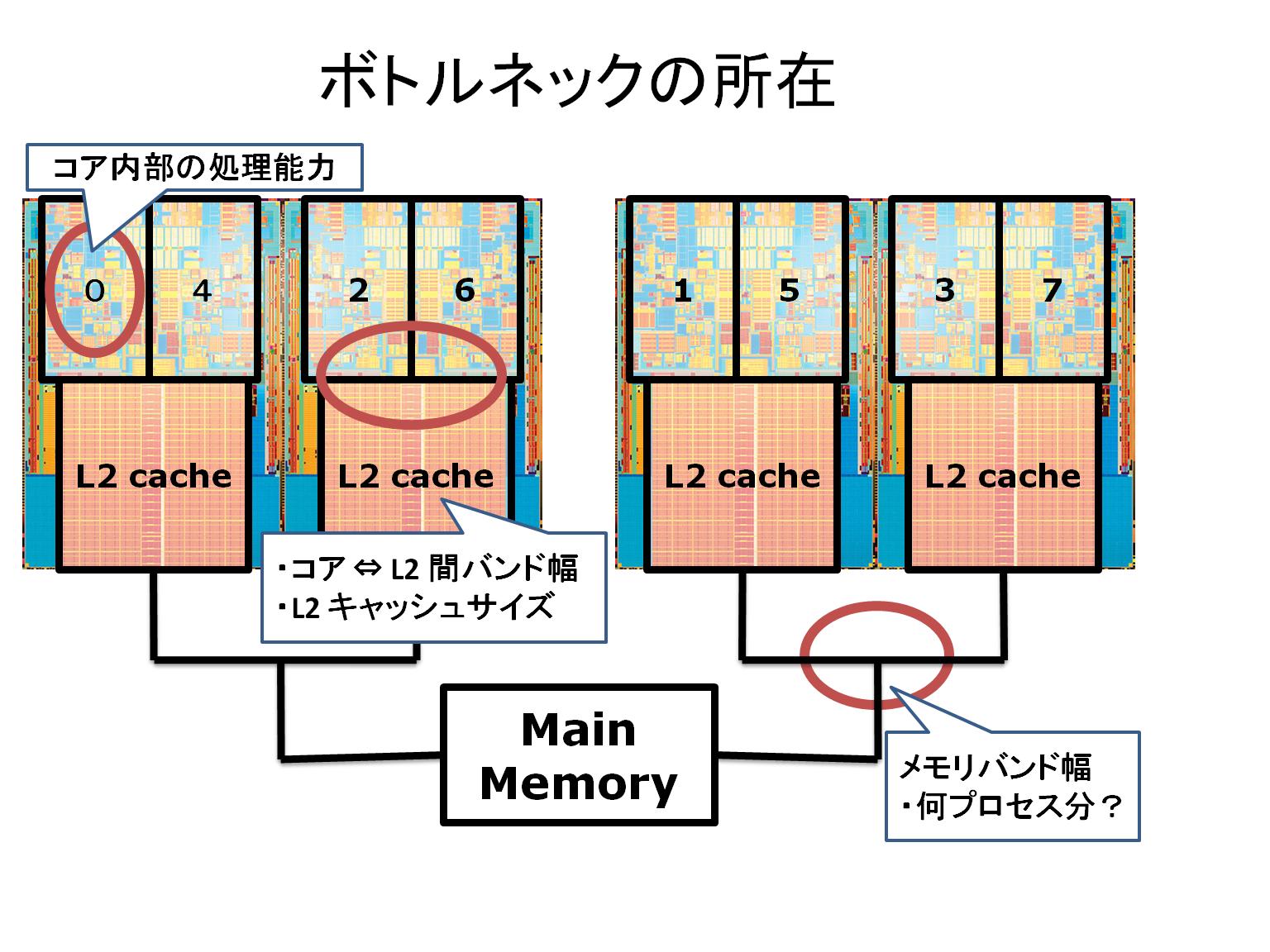
A: 0-1-2-3-4-5-6-7 (16 MPI x 8 Thread)
B: 0-4-2-6-1-5-3-7 (16 MPI x 8 Thread)
C: 0-4-2-6 & 1-5-3-7 (32 MPI x 4 Pthread)
どの設定が最速になるのかは、もちろん問題に依存するが、問題の特性を見ることによって事前に判断ができそうだ。
○問題1:NH.3Sigma-.DZ.pqgt1t2p.dat-s
A: 72m1s
B: 71m29s
C: 84m54s
○問題2:nug18_r2.dat-s
A: 45m6s
B: 43m35s
C: 41m37s
○ SDPA クラスタ
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.5 for x86_64
A: 0-1-2-3-4-5-6-7 (16 MPI x 8 Thread)
B: 0-4-2-6-1-5-3-7 (16 MPI x 8 Thread)
C: 0-4-2-6 & 1-5-3-7 (32 MPI x 4 Pthread)
どの設定が最速になるのかは、もちろん問題に依存するが、問題の特性を見ることによって事前に判断ができそうだ。
○問題1:NH.3Sigma-.DZ.pqgt1t2p.dat-s
A: 72m1s
B: 71m29s
C: 84m54s
○問題2:nug18_r2.dat-s
A: 45m6s
B: 43m35s
C: 41m37s
○ SDPA クラスタ
16 Nodes, 32 CPUs, 128 CPU cores;
CPU : Intel Xeon 5460 3.16GHz (quad cores) x 2 / node
Memory : 48GB / node
NIC : GbE x 2 and Myrinet-10G x 1 / node
OS : CentOS 5.5 for x86_64