








どうも、ようやくRAGを試せて少しだけ達成感のあるTです。
昨今IT業界ではAIがもてはやされていますが、色んな会社が色んなサービスを展開していて中々追いかけるのが大変ですね。やれLLMだ、やれNotebookLMが最強だ、やれMCP/A2Aで今年はAIエージェント元年だ…。
今回はそんな流れに乗り遅れ気味ではありますが、RAGを動かしてみたよ、という内容です。
今回使うのは「AnythingLLM」というオープンソースなローカルAI環境です。
https://anythingllm.com/
AnythingLLMは簡単に言えば「LLM関連の機能を詰め込んだ何でもアプリ」です。チャットもできますし、ドキュメントを読み込ませればRAGとしても動きます。APIサーバーにもなるのでエディタと連携してコード補完にも使えます。エージェント機能もちょっとだけ実装済みで、今後拡張予定だとか。
このRAG機能を使ってみて、「そもそもRAGって使えるのか?」ということの概観を掴めればと思います。
■検証条件
・参照ドキュメントあり/なしの応答の違いを見る
・RAGに使うモデルを変えて応答の違いを見る
・参照ドキュメントは「著作権」のWikiページ
https://ja.wikipedia.org/wiki/%E8%91%97%E4%BD%9C%E6%A8%A9
※全文選択して保存したテキストファイル
すごくザックリした検証条件です。全然RAGというものをわかっていないので、まずはこんな感じで試してみたいと思います。
参照ドキュメントに著作権のWikiページを選んだのは、ゆくゆく社内の業務マニュアル類をチャットAI化/エージェント化したいと考えていて、何となくルールっぽくて結構複雑なものを題材にしたかったからです。(著作権ってすごく大事ですが、すごく難しいですよね…。)
■検証に使う質問
・著作権は狭義には何を指しますか?「著作○○権」の形で答えてください。
・著作権は広義には何を指しますか?「著作○○権」の形で3つ答えてください。
正解
狭義: 著作財産権
広義: 著作財産権、著作者人格権、著作隣接権
質問もすごくシンプルな2つにしました。どちらもWikiページ上に明確に答えが載っていて、だけどしっかり読まないと人間でもうっかり間違えそうな感じにしてます。
■検証に使うモデル
・Gemma3 12B (https://ollama.com/library/gemma3)
・Phi4 14B (https://ollama.com/library/phi4)
・Llama-3-ELYZA-JP 8B (https://ollama.com/dsasai/llama3-elyza-jp-8b)
・DeepSeek-R1-Distill-Qwen-Japanese 14B (https://ollama.com/yuma/DeepSeek-R1-Distill-Qwen-Japanese)
LLMモデルは4つ選定しました。GoogleとMicrosoftが提供している多言語対応したモデルと、日本企業のELYZAとCyberAgentが提供している日本語特化モデルです。
なお、DeepSeekは色々と怪しい噂もあるので使う際はご注意を。今回はモデルファイルのみの利用であること、CyberAgentが追加学習した後のモデルであることから問題ないと判断して使っています。
ということで検証結果に移ります。
まずはGoogleのGemma3ではどういう回答が来たのかご紹介します。
まずは参照ドキュメントがない場合です。


結構惜しいですね…!
厳密には広義の「著作隣接権」だけ正解ですが、近い言葉は回答されているので惜しいところです。
今度は参照ドキュメントありを試します。


広義の方は『「著作○○件」の形で答えて』という指示に反していますが、出てきた単語としては正答率が上がりましたね。広義の「関連権利」だけ誤答です。
なお、回答の下に「Show Citations >」と出ていますが、これは参考にしたドキュメントを指しています。「ファイルの中のココ!」までは示せず、「どのファイルを参考にしたか」程度の情報です。今回は1ファイルだけなので全ての回答で同じ参考情報となります。
他のモデルは…と行きたいところですが、一つずつだと長くなりそうなので下記の観点で点数化したいと思います。
・正確性:
回答中に正しい用語が含まれるか
狭義1点、広義3点の計4点
・遵守度:
『「著作○○件」の形で答えて』にどれだけ従っているか
単語のみ2点、説明付き列挙1点、文章0点
・回答速度:
回答にかかった時間(厳密にはトークン生成速度tok/s)
参考値なので点数なし
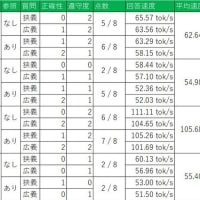
まとめた結果がコチラ

すごく適当なスコア付けですが、ELYZA > Gemma > Phi4 > DeepSeekという結果になりました。
ELYZA強いですね。回答も指示通りに「著作○○権」だけを端的に答えていました。Llama3を日本語に特化させたモデルなので、Llama3も同じ傾向かもしれませんね。
一方、高性能さも話題の一つだったDeepSeekですが今回の検証ではあまり力が出せなかったようです。
GemmaはELYZAに匹敵するほど良い成績で、英語・日本語問わず使えそうなのはとても良いですね。Phiは参照ドキュメントの有無でスコアが結構変わりました。モデル自体の日本語の学習量はそこまで大きくないけど、参照ドキュメントをしっかり読み込めている、のかもしれません。
回答速度はELYZAが極端に遅いだけで他は概ね同様でした。パラメータ数的にはELYZAが一番軽い8Bで、他は12~14Bと重めなのですが、パラメータ数よりも量子化や速度チューニングの影響を大きく受けているのかもしれませんね。
ということですごく簡単な比較でしたが色々と得られるものがありました。
個人的に一番大きな成果は「単純にドキュメントを投げ込むだけでは正確なRAGシステムを構築できなさそう」ということがわかったことです。世の中に結構こういうサービス出ている気がしますが、それらはどのくらいの精度なのか気になってきますね。
RAGは上記の問題もあって色々と進化している側面もあるのですが、また別の機会にその辺りも触ってみたいと思います。
今回はこの辺で!
(T)
moni-meter
脱・手書き!点検データをデジタル化、誤検針を削減
AI自動読み取りで検針が楽になる設備点検支援システム
PLMソリューション
製品ライフサイクルの各データを活用しビジネスを改革
PLMシステム導入支援、最適なカスタマイズを提案します
EV用充電制御ソリューション
EV充電インフラ整備を促進するソリューションを提供
OCPP・ECHONET Liteなど設備の通信規格に柔軟に対応
株式会社NTTデータIMジェイエスピー
横浜に拠点を置くソフトウェア・システム開発、
自社製品開発(moniシリーズ)も手がけるIT企業
昨今IT業界ではAIがもてはやされていますが、色んな会社が色んなサービスを展開していて中々追いかけるのが大変ですね。やれLLMだ、やれNotebookLMが最強だ、やれMCP/A2Aで今年はAIエージェント元年だ…。
今回はそんな流れに乗り遅れ気味ではありますが、RAGを動かしてみたよ、という内容です。
今回使うのは「AnythingLLM」というオープンソースなローカルAI環境です。
https://anythingllm.com/
AnythingLLMは簡単に言えば「LLM関連の機能を詰め込んだ何でもアプリ」です。チャットもできますし、ドキュメントを読み込ませればRAGとしても動きます。APIサーバーにもなるのでエディタと連携してコード補完にも使えます。エージェント機能もちょっとだけ実装済みで、今後拡張予定だとか。
このRAG機能を使ってみて、「そもそもRAGって使えるのか?」ということの概観を掴めればと思います。
■検証条件
・参照ドキュメントあり/なしの応答の違いを見る
・RAGに使うモデルを変えて応答の違いを見る
・参照ドキュメントは「著作権」のWikiページ
https://ja.wikipedia.org/wiki/%E8%91%97%E4%BD%9C%E6%A8%A9
※全文選択して保存したテキストファイル
すごくザックリした検証条件です。全然RAGというものをわかっていないので、まずはこんな感じで試してみたいと思います。
参照ドキュメントに著作権のWikiページを選んだのは、ゆくゆく社内の業務マニュアル類をチャットAI化/エージェント化したいと考えていて、何となくルールっぽくて結構複雑なものを題材にしたかったからです。(著作権ってすごく大事ですが、すごく難しいですよね…。)
■検証に使う質問
・著作権は狭義には何を指しますか?「著作○○権」の形で答えてください。
・著作権は広義には何を指しますか?「著作○○権」の形で3つ答えてください。
正解
狭義: 著作財産権
広義: 著作財産権、著作者人格権、著作隣接権
質問もすごくシンプルな2つにしました。どちらもWikiページ上に明確に答えが載っていて、だけどしっかり読まないと人間でもうっかり間違えそうな感じにしてます。
■検証に使うモデル
・Gemma3 12B (https://ollama.com/library/gemma3)
・Phi4 14B (https://ollama.com/library/phi4)
・Llama-3-ELYZA-JP 8B (https://ollama.com/dsasai/llama3-elyza-jp-8b)
・DeepSeek-R1-Distill-Qwen-Japanese 14B (https://ollama.com/yuma/DeepSeek-R1-Distill-Qwen-Japanese)
LLMモデルは4つ選定しました。GoogleとMicrosoftが提供している多言語対応したモデルと、日本企業のELYZAとCyberAgentが提供している日本語特化モデルです。
なお、DeepSeekは色々と怪しい噂もあるので使う際はご注意を。今回はモデルファイルのみの利用であること、CyberAgentが追加学習した後のモデルであることから問題ないと判断して使っています。
ということで検証結果に移ります。
まずはGoogleのGemma3ではどういう回答が来たのかご紹介します。
まずは参照ドキュメントがない場合です。
結構惜しいですね…!
厳密には広義の「著作隣接権」だけ正解ですが、近い言葉は回答されているので惜しいところです。
今度は参照ドキュメントありを試します。
広義の方は『「著作○○件」の形で答えて』という指示に反していますが、出てきた単語としては正答率が上がりましたね。広義の「関連権利」だけ誤答です。
なお、回答の下に「Show Citations >」と出ていますが、これは参考にしたドキュメントを指しています。「ファイルの中のココ!」までは示せず、「どのファイルを参考にしたか」程度の情報です。今回は1ファイルだけなので全ての回答で同じ参考情報となります。
他のモデルは…と行きたいところですが、一つずつだと長くなりそうなので下記の観点で点数化したいと思います。
・正確性:
回答中に正しい用語が含まれるか
狭義1点、広義3点の計4点
・遵守度:
『「著作○○件」の形で答えて』にどれだけ従っているか
単語のみ2点、説明付き列挙1点、文章0点
・回答速度:
回答にかかった時間(厳密にはトークン生成速度tok/s)
参考値なので点数なし
まとめた結果がコチラ
すごく適当なスコア付けですが、ELYZA > Gemma > Phi4 > DeepSeekという結果になりました。
ELYZA強いですね。回答も指示通りに「著作○○権」だけを端的に答えていました。Llama3を日本語に特化させたモデルなので、Llama3も同じ傾向かもしれませんね。
一方、高性能さも話題の一つだったDeepSeekですが今回の検証ではあまり力が出せなかったようです。
GemmaはELYZAに匹敵するほど良い成績で、英語・日本語問わず使えそうなのはとても良いですね。Phiは参照ドキュメントの有無でスコアが結構変わりました。モデル自体の日本語の学習量はそこまで大きくないけど、参照ドキュメントをしっかり読み込めている、のかもしれません。
回答速度はELYZAが極端に遅いだけで他は概ね同様でした。パラメータ数的にはELYZAが一番軽い8Bで、他は12~14Bと重めなのですが、パラメータ数よりも量子化や速度チューニングの影響を大きく受けているのかもしれませんね。
ということですごく簡単な比較でしたが色々と得られるものがありました。
個人的に一番大きな成果は「単純にドキュメントを投げ込むだけでは正確なRAGシステムを構築できなさそう」ということがわかったことです。世の中に結構こういうサービス出ている気がしますが、それらはどのくらいの精度なのか気になってきますね。
RAGは上記の問題もあって色々と進化している側面もあるのですが、また別の機会にその辺りも触ってみたいと思います。
今回はこの辺で!
(T)
moni-meter
脱・手書き!点検データをデジタル化、誤検針を削減
AI自動読み取りで検針が楽になる設備点検支援システム
PLMソリューション
製品ライフサイクルの各データを活用しビジネスを改革
PLMシステム導入支援、最適なカスタマイズを提案します
EV用充電制御ソリューション
EV充電インフラ整備を促進するソリューションを提供
OCPP・ECHONET Liteなど設備の通信規格に柔軟に対応
株式会社NTTデータIMジェイエスピー
横浜に拠点を置くソフトウェア・システム開発、
自社製品開発(moniシリーズ)も手がけるIT企業









※コメント投稿者のブログIDはブログ作成者のみに通知されます