








ユーザって私のことですが。
UTF-8になって使える文字が爆発的に増えましたが、現状のAnthyではそれをうまく扱うことができません。
厳密にいうと違いますが、ATOKはF2キーを単漢字変換に割り当てています。もしこれと同じような機能がAnthyでも使えたら、UTF-8の文字は全部単漢字辞書で出せるようにしてしまえば、たいていの問題は解決します。
しかし、現状はそのような機能がないため、普通に変換すると見たこともない漢字がずらずらと出てきて非常に不便、ということになりかねません。
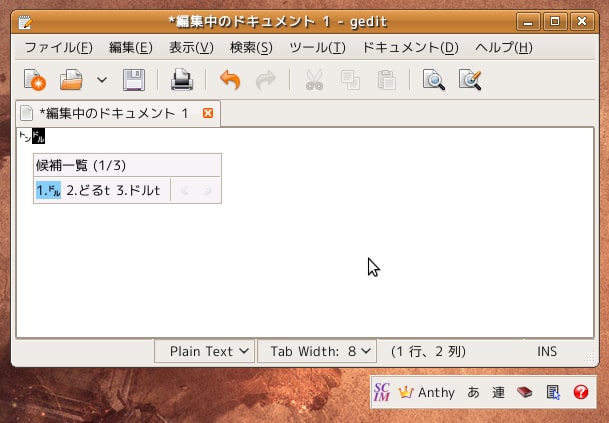
そうならないために、alt-cannadicでは読みの後ろに"t"を入れています。
これだと、意図しないと見たこともないような漢字が出てくる恐れはありませんが、知らないと入力できないということにもなります。先日アップした画面を見ても、"t"を入力していることがわかります。
しかし、上記のような制限を考えると、これはなかなかリーズナブルでナイスなアイディアだと思います。
他にも、「これはUTF-8の文字だから注意してね」というannotation(注釈?)が出てきてほしいところでもあります。これも現状では不可能です。まぁscim-anthyとかだと文字のエンコーディングが変更できるので、これで対応すればいいという話のような気もしますが。
仮にAnthyにこれらのような機能を実装したとすると、結構大がかりなことになります(たぶん)。もちろんフロントエンドでも対応しなければいけませんし、辞書ツールも「単漢字辞書で使用」とかいうチェックが必要になるかもしれません。
そのようなことを織り込んだ新しい変換エンジンが必要なんじゃないでしょうか、というのが結論なわけです。
どの程度実用的なのかはわかりませんけど、日本語の変換エンジンから繁体字/簡体字やハングル、その他の文字も入力できるようになったら便利かもしれません。
UTF-8になって使える文字が爆発的に増えましたが、現状のAnthyではそれをうまく扱うことができません。
厳密にいうと違いますが、ATOKはF2キーを単漢字変換に割り当てています。もしこれと同じような機能がAnthyでも使えたら、UTF-8の文字は全部単漢字辞書で出せるようにしてしまえば、たいていの問題は解決します。
しかし、現状はそのような機能がないため、普通に変換すると見たこともない漢字がずらずらと出てきて非常に不便、ということになりかねません。
そうならないために、alt-cannadicでは読みの後ろに"t"を入れています。
これだと、意図しないと見たこともないような漢字が出てくる恐れはありませんが、知らないと入力できないということにもなります。先日アップした画面を見ても、"t"を入力していることがわかります。
しかし、上記のような制限を考えると、これはなかなかリーズナブルでナイスなアイディアだと思います。
他にも、「これはUTF-8の文字だから注意してね」というannotation(注釈?)が出てきてほしいところでもあります。これも現状では不可能です。まぁscim-anthyとかだと文字のエンコーディングが変更できるので、これで対応すればいいという話のような気もしますが。
仮にAnthyにこれらのような機能を実装したとすると、結構大がかりなことになります(たぶん)。もちろんフロントエンドでも対応しなければいけませんし、辞書ツールも「単漢字辞書で使用」とかいうチェックが必要になるかもしれません。
そのようなことを織り込んだ新しい変換エンジンが必要なんじゃないでしょうか、というのが結論なわけです。
どの程度実用的なのかはわかりませんけど、日本語の変換エンジンから繁体字/簡体字やハングル、その他の文字も入力できるようになったら便利かもしれません。





{kind=link}