前回の続き
統計解析フリーソフト R の備忘録頁 ver.3.1
http://cse.naro.affrc.go.jp/takezawa/r-tips/r.html
や
Rで統計 - R入門
http://home.hiroshima-u.ac.jp/chubo/index.cgi?R%a4%c7%c5%fd%b7%d7
をもとに、Rを勉強してみる。
もう、順番めちゃくちゃになってきたけど、今回はデータ操作。
RDBなんかだと、選択、射影、結合ができる
選択とは
条件にあった「行」のみ取り出すこと
射影とは
自分が見たい「列」だけ取り出すこと
結合は
2つにテーブルを連結すること(列をつなげる)
今回は、この操作について、行いたい。
■選択
行を選択するには、subsetを使います。
subset(データ,条件式)
例:subset(CO2,Type=="Quebec")

(もっと続いているけど、省略)
■射影
3とおりあります。
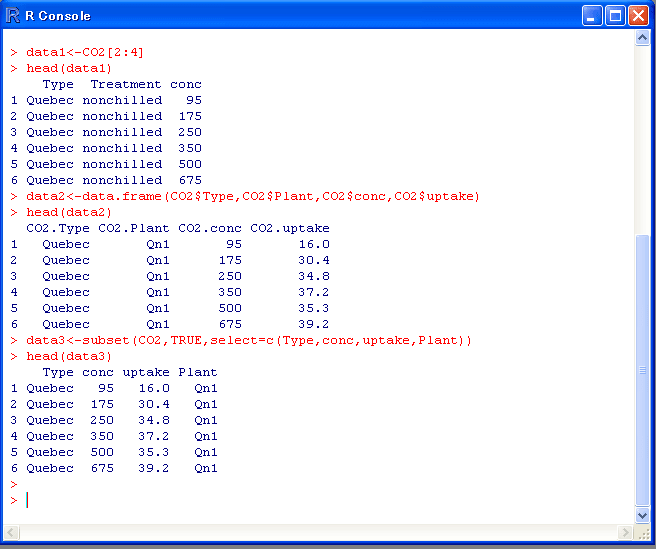
1.桁が連続しているとき
データ[開始桁:終了桁]
例:CO2[2:4]
2.桁が離れているとき:その1
data.frame(桁1,桁2,桁3・・・)
例:data.frame(CO2$Type,CO2$Plant,CO2$conc,CO2$uptake)
(桁の順番を変えてもOK)
3.桁が離れているとき:その2
subset(データ,条件式,select=c(桁1,桁2,・・・))
※条件式にTRUEをいれれば、全ての場合ということになり、
結局、射影(select部分の処理)をしていることになる。
例:subset(CO2,TRUE,select=c(Type,conc,uptake,Plant))
■結合
ようするにJOIN
データ1が、売上テーブル(項目:販売日時、商品コードなど)
データ2が、商品テーブル(項目:商品コード、商品名など)
のとき、データ1の商品コードと、データ2の商品コードを連結させて
(一致するレコードを結び付けて)
売上レコードに、商品名を結び付けたいような場合につかう
marge(データ1,データ2,by.x="データ1の結合桁名",by.y="データ2の結合桁名")
例:
今、data1に(id,Plant,Type,Treatment,conc,uptake)、
data2に(id,name)
が入っていて、data1のTypeと、data2のidを連結させて、data2の名前を取得したい場合
merge(data1,data2,by.x="Type",by.y="id")

subsetは結局subset(データ,条件式,select=c(項目・・・))なので、
SQLのSELECTの項目名を並べるところと、WHERE句にほぼ相当する。
また、mergeでJOINを行う。
なので、この2つだけを知っていれば、SQLに相当する操作はできる。
















