








きのう(8月30日)「夏休み最後の自由研究をしよう!データビジュアライゼーションもくもく会」に行って来た!
その内容をメモメモ
本日の趣旨
手を動かして作る
これまでのダイジェスト
最後に成果発表
AITCの紹介
■R言語ではじめよう、データサイエンス!(ハンズオン勉強会)
~機械学習・データビジュアタイゼーション事始め~
(すがいさん)
http://www.slideshare.net/dsuket/ss-38507785
・SVMとK-means
・R-Studio
・ggplot2
気象庁の台風の軌道
・~相関分析による需要予測~
東京電力の電力使用量
気温
■D3.jsでLODをビジュアライゼーション
http://www.slideshare.net/dsuket/d3js-35239244
Data駆動→グラフツールではない。
宣言的に記述。何を表すかを記述する
データセット→順次指定
足りないとき、Enter,Exit
スケール
地図を表示できる
SPARQL
DBPedia
■D3.JSを使ったデータビジュアライズ勉強会
http://cloud.aitc.jp/20140717_D3js/
のall.zipを解凍すればOK
・横浜のオープンデータ
・横浜市統計情報ポータルサイト
横浜市/統計白書
Excel→CSVへ
緯度経度に直すサイト
テレビ受信→地図へ
「もくもく会」でやったこと
<<目標>>
台風の軌道をD3.jsで書く
■まずは、Rで書くことの復習
(1)Rで日本を書く
R起動
install.packages("maps")
library(maps)
map(xlim=c(121,155),ylim=c(20,50))
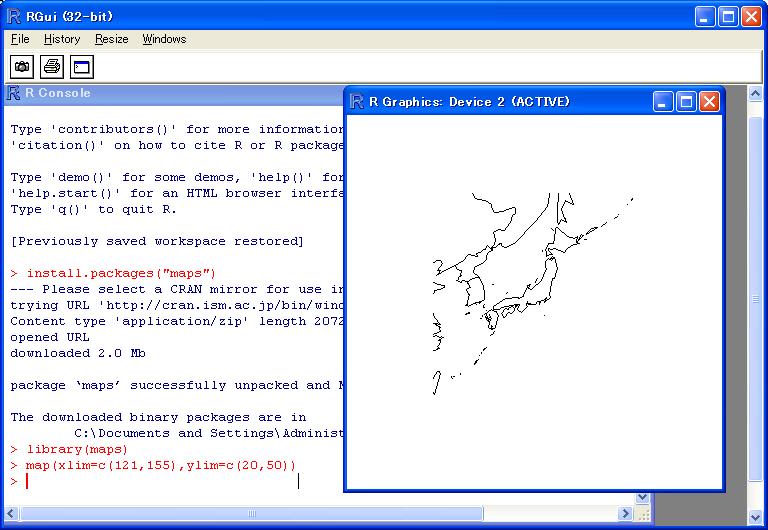
(2)気象庁データのダウンロード:2014年版を利用
bst<-readLines('http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/Besttracks/bst2014.txt')
View(bst)
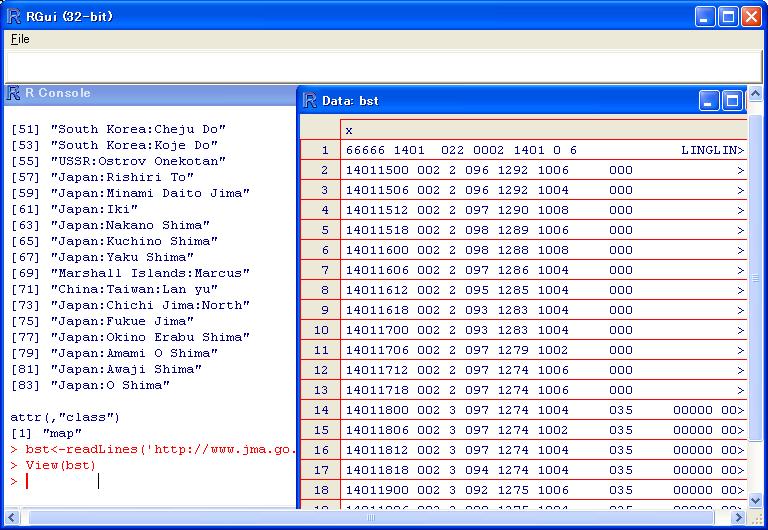
・ヘッダー部分処理
header<-read.table(textConnection(bst[grep("^66666",bst)]))
View(header)
・レコード部
record<-read.table(textConnection(bst[-grep("^66666",bst)]),fill=TRUE)
record<-record[!is.na(record[,7]),]
View(record)
・必要な行のみ抽出し、列名をつける
header<-header[,c(3,4,8)]
names(header)<-c("NROW","TC_NO","NAME")
View(header)
record<-record[,c(1,3:7)]
names(record)<-c("DATE_TIME","GRADE","LAT","LON","HPA","KT")
View(record)
・RecordにHeaderのID(TC_NO)を付与
record$TC_NO<-rep(header$TC_NO,header$NROW)
View(record)
・HeaderとRecodeをJoin(merge)する
data<-merge(header,record,by="TC_NO")
View(data)
・緯度経度補正(10倍されている)
data<-transform(data,LAT=LAT/10,LON=LON/10)
View(data)
・緯度経度幅の確認
range_lon<-range(data$LON)
range_lon
range_lat<-range(data$LAT)
range_lat
→103.6~183.2,1.8~53.7と確認できる
(3)mapに台風の軌道を書く
map<-data.frame(map(plot=FALSE,
xlim=c(range_lon[1]-10,range_lon[2]+10),
ylim=c(range_lat[1]-5,range_lat[2]+5))[c("x","y")])
・描画
install.packages("ggplot2")
library(ggplot2)
ggplot(data,aes(LON,LAT,colour=NAME))+
geom_point(aes(size=GRADE))+
geom_path(aes(x,y,colour=NULL),map)
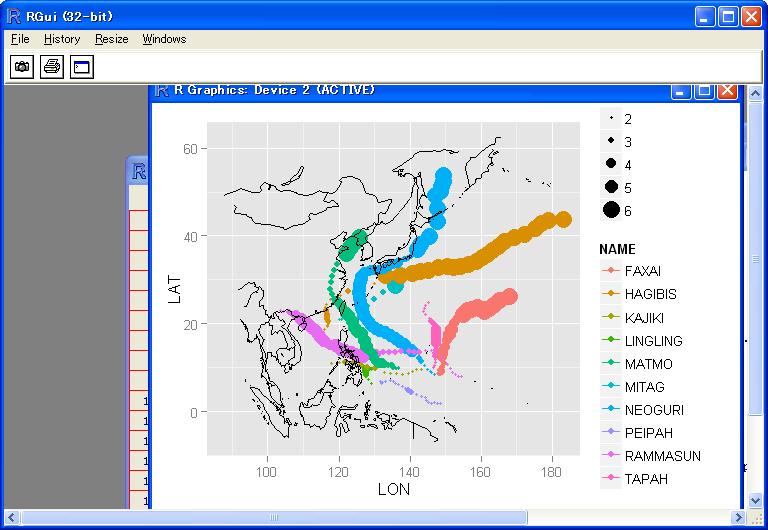
・保存(change dirで適当な作業ディレクトリに変更後)
p<-ggplot(data,aes(LON,LAT,colour=NAME))+
geom_point(aes(size=GRADE))+
geom_path(aes(x,y,colour=NULL),map)
ggsave("typhoons2014.png",p)
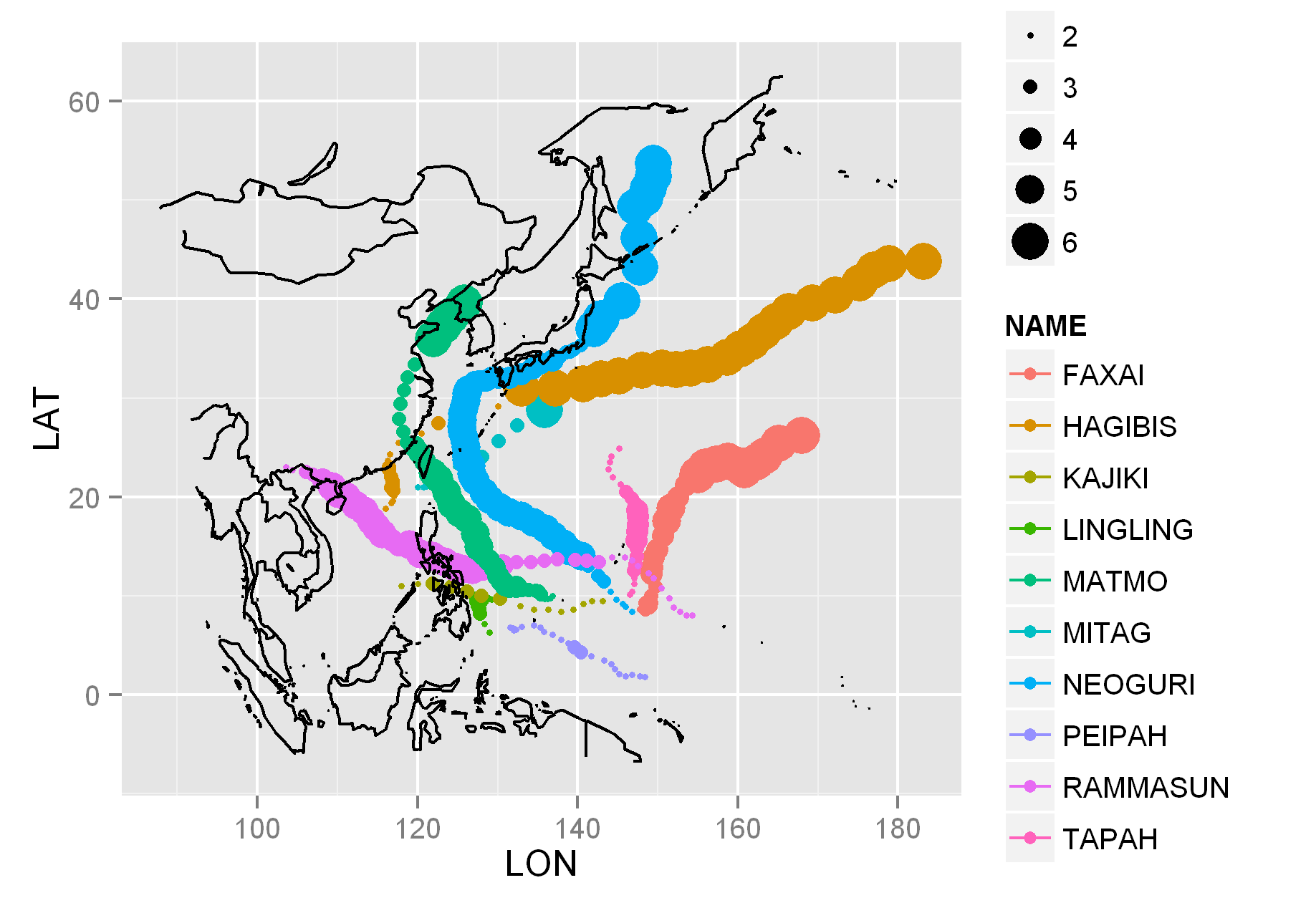
(4)CSVファイルに保存
write.csv(data,file="typhoons2014.txt")
■D3.jsで日本地図を出し、プロットしてみる
・jsfiddleで日本地図表示
http://jsfiddle.net/に行く
http://jsfiddle.net/sEFjd/ のjavascriptの内容をコピー
Framework&Extensionsを
D3 3.0.4
OnDomready
に設定
External Resourcesに topojson.v0.min.js を追加
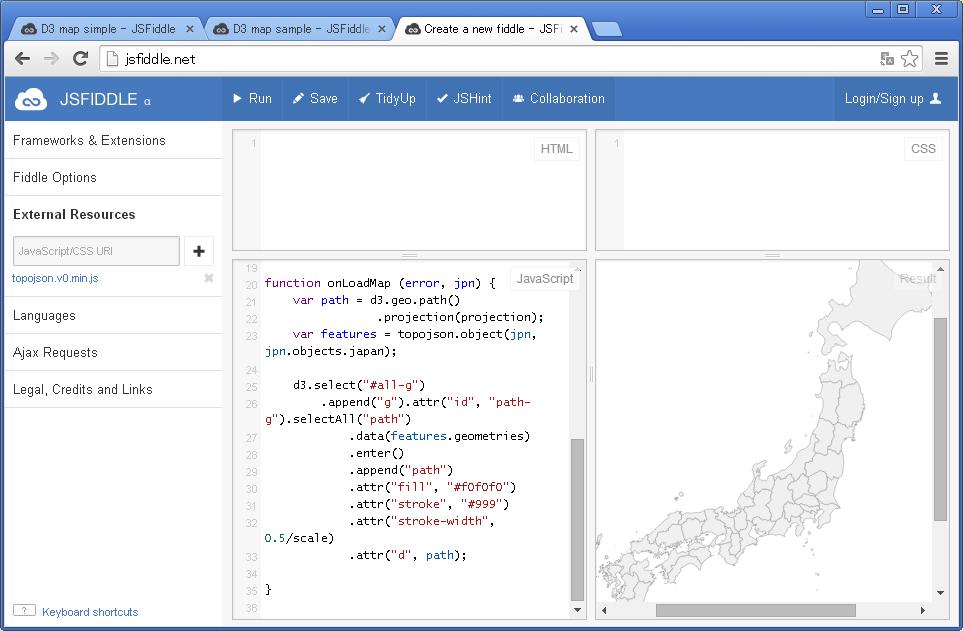
・ここで終わってしまいました・・・
このあと、http://jsfiddle.net/dsuket/W9sVC/を参考に
点を書く予定でした。
■発表会
NVD3
c3.js
このあと、D3.jsで日本地図出して、点をうつ方法までは分かりました。
別エントリで書きます
その内容をメモメモ
本日の趣旨
手を動かして作る
これまでのダイジェスト
最後に成果発表
AITCの紹介
■R言語ではじめよう、データサイエンス!(ハンズオン勉強会)
~機械学習・データビジュアタイゼーション事始め~
(すがいさん)
http://www.slideshare.net/dsuket/ss-38507785
・SVMとK-means
・R-Studio
・ggplot2
気象庁の台風の軌道
・~相関分析による需要予測~
東京電力の電力使用量
気温
■D3.jsでLODをビジュアライゼーション
http://www.slideshare.net/dsuket/d3js-35239244
Data駆動→グラフツールではない。
宣言的に記述。何を表すかを記述する
データセット→順次指定
足りないとき、Enter,Exit
スケール
地図を表示できる
SPARQL
DBPedia
■D3.JSを使ったデータビジュアライズ勉強会
http://cloud.aitc.jp/20140717_D3js/
のall.zipを解凍すればOK
・横浜のオープンデータ
・横浜市統計情報ポータルサイト
横浜市/統計白書
Excel→CSVへ
緯度経度に直すサイト
テレビ受信→地図へ
「もくもく会」でやったこと
<<目標>>
台風の軌道をD3.jsで書く
■まずは、Rで書くことの復習
(1)Rで日本を書く
R起動
install.packages("maps")
library(maps)
map(xlim=c(121,155),ylim=c(20,50))
(2)気象庁データのダウンロード:2014年版を利用
bst<-readLines('http://www.jma.go.jp/jma/jma-eng/jma-center/rsmc-hp-pub-eg/Besttracks/bst2014.txt')
View(bst)
・ヘッダー部分処理
header<-read.table(textConnection(bst[grep("^66666",bst)]))
View(header)
・レコード部
record<-read.table(textConnection(bst[-grep("^66666",bst)]),fill=TRUE)
record<-record[!is.na(record[,7]),]
View(record)
・必要な行のみ抽出し、列名をつける
header<-header[,c(3,4,8)]
names(header)<-c("NROW","TC_NO","NAME")
View(header)
record<-record[,c(1,3:7)]
names(record)<-c("DATE_TIME","GRADE","LAT","LON","HPA","KT")
View(record)
・RecordにHeaderのID(TC_NO)を付与
record$TC_NO<-rep(header$TC_NO,header$NROW)
View(record)
・HeaderとRecodeをJoin(merge)する
data<-merge(header,record,by="TC_NO")
View(data)
・緯度経度補正(10倍されている)
data<-transform(data,LAT=LAT/10,LON=LON/10)
View(data)
・緯度経度幅の確認
range_lon<-range(data$LON)
range_lon
range_lat<-range(data$LAT)
range_lat
→103.6~183.2,1.8~53.7と確認できる
(3)mapに台風の軌道を書く
map<-data.frame(map(plot=FALSE,
xlim=c(range_lon[1]-10,range_lon[2]+10),
ylim=c(range_lat[1]-5,range_lat[2]+5))[c("x","y")])
・描画
install.packages("ggplot2")
library(ggplot2)
ggplot(data,aes(LON,LAT,colour=NAME))+
geom_point(aes(size=GRADE))+
geom_path(aes(x,y,colour=NULL),map)
・保存(change dirで適当な作業ディレクトリに変更後)
p<-ggplot(data,aes(LON,LAT,colour=NAME))+
geom_point(aes(size=GRADE))+
geom_path(aes(x,y,colour=NULL),map)
ggsave("typhoons2014.png",p)
(4)CSVファイルに保存
write.csv(data,file="typhoons2014.txt")
■D3.jsで日本地図を出し、プロットしてみる
・jsfiddleで日本地図表示
http://jsfiddle.net/に行く
http://jsfiddle.net/sEFjd/ のjavascriptの内容をコピー
Framework&Extensionsを
D3 3.0.4
OnDomready
に設定
External Resourcesに topojson.v0.min.js を追加
・ここで終わってしまいました・・・
このあと、http://jsfiddle.net/dsuket/W9sVC/を参考に
点を書く予定でした。
■発表会
NVD3
c3.js
このあと、D3.jsで日本地図出して、点をうつ方法までは分かりました。
別エントリで書きます



 ウィリアムのいたずら @xmldtp
ウィリアムのいたずら @xmldtp




