










 ウィリアムのいたずら @xmldtp
ウィリアムのいたずら @xmldtpたしかに別人・・・だけど、afterより、beforeに眉書いて、メガネかけたほうが、自分の好みだ・・・やっぱ、自分の好みはおかしい(^^;)? matome.naver.jp/odai/213790365…
マスコミというのは、
巨大権力に対し挑戦し、
時代を風刺し、
反骨精神を示すものであります。
プリキュアがAKBと秋元康を痛烈批判! プロデューサーが怪物になり「CD買ってよ~握手券つけるから~」と暴れる
http://blog.livedoor.jp/dqnplus/archives/1781096.html
すばらしい風刺!
一番マスコミらしいテレビ番組はプリキュアかもしれん・・・
巨大権力に対し挑戦し、
時代を風刺し、
反骨精神を示すものであります。
プリキュアがAKBと秋元康を痛烈批判! プロデューサーが怪物になり「CD買ってよ~握手券つけるから~」と暴れる
http://blog.livedoor.jp/dqnplus/archives/1781096.html
すばらしい風刺!
一番マスコミらしいテレビ番組はプリキュアかもしれん・・・
統計モデル その3 SEMによる単回帰
http://blog.goo.ne.jp/xmldtp/e/45e908f31f3060d9e7acb5b753c97493
の続き。「統計モデル」の授業のメモメモ
影響を排除する方法
・偏相関
・パス解析
・重回帰
偏相関
model1<-'
COG~SES
HS~SES
CG~~HS
'
~~が偏相関
パス解析
model2<-'
COG~SES
HS~SE
COG~HS
'
重回帰
model3<-'
COG~HS+SES
'
・効果の有無=有意性検定
・モデルを立てるとき=理由が要る
・回帰係数と因子負荷量は両方ともパス係数と呼ばれる
・偏回帰係数を相関といわないように
→違う概念、値も違う
擬似相関・偏相関係数
誤差の間の相関・擬似相関
→見かけ上の相関
モデルの修正
ビッグファイブの神経質分析
モデル1:よくなかった
モデル2,3:よくなった→こっちがいい
では、どうやってモデル1から3に考えるか
モデルの修正とは
・適合度が悪い場合に、モデルを修正して適合度を上げる
適合が悪いモデルを報告しても意味ない
・どのように修正を行う?
数値的
理論的(意味的)
モデル1のΣの値
RMSEAをみる→悪い値
共分散行列が得られる(fitted())
残差(StoΣの差)
・適合が良いSとΣの差が小さいはず
・データから計算されるS
・モデル1のS-Σ
→絶対値が小さければよい
一部大きく狂っているところがある
この間の共分散がモデルで説明できていない
・残差は、関数residで求まる
モデル2
・その残差を小さくするようなパラメータを入れれば適合が改善する
→RESEAが0で良くなる
→理論的に説明できるか?
モデル3
・だったら、別個の構成概念を測定していることを
直接的に表現
標準化残差
残差にも種類
標準化残差
修正指数
miカイ二乗の減少値
epc
→mi大きいところ探す
Rではmodindices
パス解析
・因果モデルを考えて
・そんなに特別なものじゃない
・因果の方向性を知るのは難しい
・分析者が仮定した因果モデルを分析する手法
事例1:
標準化推定値→分散を1にしたとき
そうでないと、非標準化
非標準化→変数の単位ついてる:単位に依存で解釈
→標準化、非標準化どちらがいいかはケースないケース
決定係数:パス解析でもできる
モデルを変える
誤差分散が小さくなった=説明できない部分が激減
直接効果:ダイレクトに影響
間接効果:何かを介して影響
総合効果=直接効果+間接効果
直接効果の解釈
間接効果の要因が一定の場合、排除した場合
間接効果の解釈
パス間の係数の掛け算
総合効果の解釈
直接効果+間接効果
標準化の場合
分散1になっているので、
変数が1変化すると、1標準偏差変化させることになる
lavvanのくせ
外生的な観測変数=矢印が刺さっていない(出てるだけ)
→自動的に共分散を入れてしまうものがある。
入れたくないとき
変数1~~0*変数2
~~(共分散)で、0をかけることにより、0になり、入らない
sem(model1,sample・・・,fixed.x=T)
fixed.x=Tの説明は省略
従属変数に複数の変数(X1,X2,X3)が影響する場合
X2,X3が一定の場合には、
X1が大きくなると、Yは○大きくなる
と解釈する
パス解析におけるSとΣ
・確認的因子分析の場合と同じように
標本データから計算される共分散行列Sと
モデルから計算される共共分散行列Σの差を
小さくするようなパラメタをもとめる
丁度識別=飽和モデル
潜在変数間のパス解析
・観測変数の背後にある構成概念をとりdス
因子分析によって
・パス解析と因子分析の合体
・合計得点の間のパス解析はメリットない
→希薄化の修正
決定係数:やじるし刺さっているすべてもとめられる
確認的因子分析モデルの識別
・なぜ因子の分散=1
・誤差からの係数=1
内生的因子がある場合の識別
・矢印が刺さっている:内生的因子
・内生的因子の分散=パス係数の2乗+内生的因子の誤差分散の和
・一般的には因子負荷量の1つを1に固定
→lavvanのデフォルト
希薄化および希薄化の修正
合計得点でなく、因子間の相関を求める3つの理由
・構成概念に近いのは因子
・因子間の相関のほうが絶対値が大きくなる
→相関の希薄化
・単回帰・重回帰分析:飽和モデルであっても、
因子を仮定すると、適合度が求まる
因子間相関と合計得点間相関
・因子の中に誤差は入っていない=分離されてる
・合計には、誤差が含まれる
等値制約
・複数のパス係数が等しい値であるという制約
→パラメータの数が減る:倹約的
・等値制約を課すと、適合度が良くなることがある
Rだと、モデルのところで
f1=~v1*x1+v1*v2
誤差分散の場合
x1~~e1*x1
富士通が
オンプレミスと複数のパブリッククラウドのハイブリッド環境を管理できる統合運用管理ソフトウェア「Systemwalker Centric Manager V15」をグローバルに販売開始
http://pr.fujitsu.com/jp/news/2013/11/25.html
ということで、
オンプレミス、プライベートクラウド、パブリッククラウド環境を統合して管理するハイブリッドクラウド統合運用管理が話題だ。
Zabbixでは、HyClops for Zabbixなどが、それだし、
そのうちZabbix本体でも対応していくんでしょうか・・
(VMWare対応はそのはじめといえますよね)
Microsoftの場合は、Microsoft System Center 2012がそれに相当するのかな?
他の会社もあるんだろうけど、今後、クラウドの統合の話(オーケストレーション)はもとより、クラウドの統合監視は、重要視されそうですね。
オンプレミスと複数のパブリッククラウドのハイブリッド環境を管理できる統合運用管理ソフトウェア「Systemwalker Centric Manager V15」をグローバルに販売開始
http://pr.fujitsu.com/jp/news/2013/11/25.html
ということで、
オンプレミス、プライベートクラウド、パブリッククラウド環境を統合して管理するハイブリッドクラウド統合運用管理が話題だ。
Zabbixでは、HyClops for Zabbixなどが、それだし、
そのうちZabbix本体でも対応していくんでしょうか・・
(VMWare対応はそのはじめといえますよね)
Microsoftの場合は、Microsoft System Center 2012がそれに相当するのかな?
他の会社もあるんだろうけど、今後、クラウドの統合の話(オーケストレーション)はもとより、クラウドの統合監視は、重要視されそうですね。
もう、1週間前になってしまいましたが、
11月22日のZabbix Conference 2013の
日本市場におけるZABBIXの現状と今後の取り組み
についてメモメモ
2013年11月12日 Zabbix2.2
・VMWareの監視、Windowsのイベントログの監視
1.8に比べると、内部的には結構変わっている
Zabbix2.2までの取り組み
・2000件のバグ&新機能要望
1800の改善
12000コミット
2.0/2.2ファストアップグレードサービス
1.8から2.0にはDBアップグレードに時間がかかる
OSS監視ソフトウェア
2011年~ 知名度上がってきている
商用監視ソフトと比べると、クロスしてきている
→商用製品と太刀打ちできる
2012.10.1 Zabbix Japan設立
→目的:パートナー支援
22社のオフィシャルパートナー
OSS+オフィシャルサービス
・フルオープンソース
・オフィシャルサポート
・トレーニング
・会社でやっている
オフィシャルサポートのフロー
カスタマー⇔パートナー⇔ZABBIX
Zabbixのアウトプット
・数百件のサポート
・150件のバグ、要望
・修正パッチ
・セキュリティ問題の早期アナウンス
開発サービス
・お金払うと、確実に入れられる
Zabbixパートナー会
・パートナー間の情報交換
・コミニティちっくに活動
ZabbixのOSS開発サイクル
・開発・修正・改善
ダウンロード
利用・テスト
フィードバック
→フィードバックをたくさんください
Zabbixオフィシャルトレーニング
Zabbixアプライアンス:プラットホーム
無償ツール
はっぴょう3つ
(1)Zabbixアプライアンスモデルのプロキシ
・Zabbixがはいった、プロキシ
・設置簡単
・メンテナンスフリー
・VPN機能の搭載
(2)Zabbixサーバー仮想アプライアンス
ZS-V200
VMWare,Xen,KVM対応
無料で
(3)Zabbix Enterpriseサポート
技術問い合わせ
バグ修正
新機能
セキュリティFIX:早期アナウンス
ナレッジベース
周辺ツール提供
このあとも、Zabbix conference 2013はやってたけど、
ここで抜け出して、Microsoft Conference 2013に行きました。
11月22日のZabbix Conference 2013の
日本市場におけるZABBIXの現状と今後の取り組み
についてメモメモ
2013年11月12日 Zabbix2.2
・VMWareの監視、Windowsのイベントログの監視
1.8に比べると、内部的には結構変わっている
Zabbix2.2までの取り組み
・2000件のバグ&新機能要望
1800の改善
12000コミット
2.0/2.2ファストアップグレードサービス
1.8から2.0にはDBアップグレードに時間がかかる
OSS監視ソフトウェア
2011年~ 知名度上がってきている
商用監視ソフトと比べると、クロスしてきている
→商用製品と太刀打ちできる
2012.10.1 Zabbix Japan設立
→目的:パートナー支援
22社のオフィシャルパートナー
OSS+オフィシャルサービス
・フルオープンソース
・オフィシャルサポート
・トレーニング
・会社でやっている
オフィシャルサポートのフロー
カスタマー⇔パートナー⇔ZABBIX
Zabbixのアウトプット
・数百件のサポート
・150件のバグ、要望
・修正パッチ
・セキュリティ問題の早期アナウンス
開発サービス
・お金払うと、確実に入れられる
Zabbixパートナー会
・パートナー間の情報交換
・コミニティちっくに活動
ZabbixのOSS開発サイクル
・開発・修正・改善
ダウンロード
利用・テスト
フィードバック
→フィードバックをたくさんください
Zabbixオフィシャルトレーニング
Zabbixアプライアンス:プラットホーム
無償ツール
はっぴょう3つ
(1)Zabbixアプライアンスモデルのプロキシ
・Zabbixがはいった、プロキシ
・設置簡単
・メンテナンスフリー
・VPN機能の搭載
(2)Zabbixサーバー仮想アプライアンス
ZS-V200
VMWare,Xen,KVM対応
無料で
(3)Zabbix Enterpriseサポート
技術問い合わせ
バグ修正
新機能
セキュリティFIX:早期アナウンス
ナレッジベース
周辺ツール提供
このあとも、Zabbix conference 2013はやってたけど、
ここで抜け出して、Microsoft Conference 2013に行きました。
今回のお題は2つ
・開発の実績データを解析して、開発見積もりが合わない理由について
ソフトウェア工学の立場
統計学の立場
・そこから、ビッグデータの危うさを考える。
■ソフトウェア工学的に考えた、合わない理由
ソフトウェア工学的に考えると、データを解析しても、多様性があり、その辺のばらつきが誤差となる。したがって、弱い因子は、誤差範囲となってしまうので、ものすごい強い因子しか解析しても、出てこない。
具体的に言うと、LOC(ソースコード行数)は、開発規模に関係する強い因子なので出てくる。しかし、これ以外の因子は、そもそも測るのも難しいし(開発者の能力とか、疲労とか)、LOCと多重共線性がでちゃうし(設計書のページ数はLOCと、強い相関がでても、不思議ではない)、連続量ではないし(CとJavaとPHPは、名義尺度だ)っていうことで、なかなか、出てきにくいのが現状ではないだろうか。
とすると、LOCが大きいと、開発工数も多くなるという、とてつもなく当たり前な性質がでてくる。
コンビニでビッグデータ解析すると、「商圏は、数百メートル!」などという、「知ってた ^^;」っていうデータしか出てこないのと一緒だ。
■統計的に考えた、合わない理由
つまり、誤差を小さくしないといけない。
そこで、統計の場合には、どうするかというと、モデルを持ってくる。
理論的に考えられる統計モデルを複数用意し、その中から、適切なモデルを選び出す
。そのモデルが、現在の観測している変数から作れるのであれば、回帰式で表現できるから、ステップワイズ法でモデルが作れる。このぐらいは、ソフトウェア工学の学者さんもやっているだろう(・・やってるかな ^^;)
しかし、現在観測している変数の根本原因となるような因子、すなわち潜在因子があるのであれば、ステップワイズではだめで、そのような潜在因子を含めたモデルを作成し、そのモデルの正当性をSEMやグラフィカルモデリングで示していくことになる。
この場合、モデルをまず作らなければならなくなる。
ところが、このような開発モデルが、ソフトウェア工学的にはない。
そのため、このような研究は進んでいない。
■ビッグデータの危うさ
ビッグデータも同じ危うさがある。
データをたくさん集めれば、多様性は増える。
誤差は大きくなる=分散が大きくなる。
その結果、一般的なことしか言えなくなる
気温が上がると、ビールが売れる・・・など。
誤差に隠れてしまう因子を浮かび上がらせるには、
モデルを作って解析しないといけない。
この解析手法は、マーケティングのほうでは知られているが
(上記のグラフィカルモデリングのほかに
MCMC法を利用したベイズモデルなどが有る)
今のビッグデータ解析手法の中では、取り扱われていない
今のビッグデータは、回帰、判別分析(&SVM)、決定木など、
観測データからモデルを作るほうが重要と考えられている。
このへんに、ビッグデータの危うさがある。
・開発の実績データを解析して、開発見積もりが合わない理由について
ソフトウェア工学の立場
統計学の立場
・そこから、ビッグデータの危うさを考える。
■ソフトウェア工学的に考えた、合わない理由
ソフトウェア工学的に考えると、データを解析しても、多様性があり、その辺のばらつきが誤差となる。したがって、弱い因子は、誤差範囲となってしまうので、ものすごい強い因子しか解析しても、出てこない。
具体的に言うと、LOC(ソースコード行数)は、開発規模に関係する強い因子なので出てくる。しかし、これ以外の因子は、そもそも測るのも難しいし(開発者の能力とか、疲労とか)、LOCと多重共線性がでちゃうし(設計書のページ数はLOCと、強い相関がでても、不思議ではない)、連続量ではないし(CとJavaとPHPは、名義尺度だ)っていうことで、なかなか、出てきにくいのが現状ではないだろうか。
とすると、LOCが大きいと、開発工数も多くなるという、とてつもなく当たり前な性質がでてくる。
コンビニでビッグデータ解析すると、「商圏は、数百メートル!」などという、「知ってた ^^;」っていうデータしか出てこないのと一緒だ。
■統計的に考えた、合わない理由
つまり、誤差を小さくしないといけない。
そこで、統計の場合には、どうするかというと、モデルを持ってくる。
理論的に考えられる統計モデルを複数用意し、その中から、適切なモデルを選び出す
。そのモデルが、現在の観測している変数から作れるのであれば、回帰式で表現できるから、ステップワイズ法でモデルが作れる。このぐらいは、ソフトウェア工学の学者さんもやっているだろう(・・やってるかな ^^;)
しかし、現在観測している変数の根本原因となるような因子、すなわち潜在因子があるのであれば、ステップワイズではだめで、そのような潜在因子を含めたモデルを作成し、そのモデルの正当性をSEMやグラフィカルモデリングで示していくことになる。
この場合、モデルをまず作らなければならなくなる。
ところが、このような開発モデルが、ソフトウェア工学的にはない。
そのため、このような研究は進んでいない。
■ビッグデータの危うさ
ビッグデータも同じ危うさがある。
データをたくさん集めれば、多様性は増える。
誤差は大きくなる=分散が大きくなる。
その結果、一般的なことしか言えなくなる
気温が上がると、ビールが売れる・・・など。
誤差に隠れてしまう因子を浮かび上がらせるには、
モデルを作って解析しないといけない。
この解析手法は、マーケティングのほうでは知られているが
(上記のグラフィカルモデリングのほかに
MCMC法を利用したベイズモデルなどが有る)
今のビッグデータ解析手法の中では、取り扱われていない
今のビッグデータは、回帰、判別分析(&SVM)、決定木など、
観測データからモデルを作るほうが重要と考えられている。
このへんに、ビッグデータの危うさがある。
この前、「インターネットオプション」を見たら、
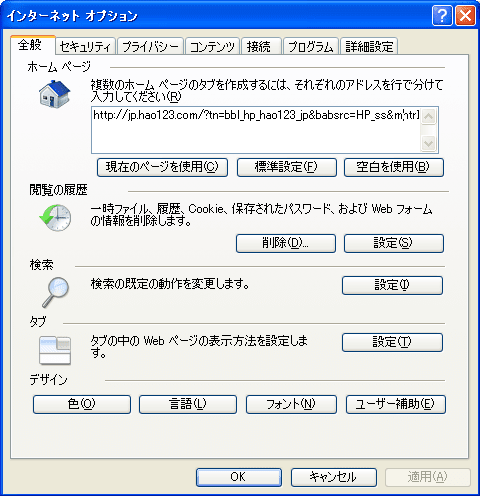
って、なってて・・・
なになに??ホームページのところ、hao123.comとか
入っているんだけど・・・
・・・入れた覚えないんだけど・・・
なにが起こってるの(@_@!)
と思って、検索したら、以下のページに・・・
hao123(jp.hao123.com) 削除アンインストール方法&スタートページ無効化方法
http://www.geocities.co.jp/Playtown-Yoyo/6130/notes/baidu-hao123.htm
バイドゥですか・・・(-_-;)
もちろん、消しましたけど・・・
いつの間に、入ったんだろう??
って、なってて・・・
なになに??ホームページのところ、hao123.comとか
入っているんだけど・・・
・・・入れた覚えないんだけど・・・
なにが起こってるの(@_@!)
と思って、検索したら、以下のページに・・・
hao123(jp.hao123.com) 削除アンインストール方法&スタートページ無効化方法
http://www.geocities.co.jp/Playtown-Yoyo/6130/notes/baidu-hao123.htm
バイドゥですか・・・(-_-;)
もちろん、消しましたけど・・・
いつの間に、入ったんだろう??
11月22日のZabbix conference 2013の話のつづき。
・Zabbix導入事例にみる課題と効果とは
・ハイブリッドクラウド環境監視自動化
Zabbixプラグイン HyClops for zabbix
・クラウド環境でのシステム監視運用ポイント
の話をまとめて、メモメモ
■Zabbix導入事例にみる課題と効果とは
クロス・ヘッド(株)
クロスヘッド自身の導入
・商用サービス
カスタムメイドな監視サービス
→監視ツールのみなおし:ツールのアーキテクチャ
オープンソースでありながらサポート:ZABBIX採用
7ヶ月くらいかけて見直し
・導入効果
運用作業のシンプル化
収益貢献:要件定義の精度貢献
・事例
商用ツール保守コスト削減
→ツール3種類、保守費用、既存監視環境あいまい
ツール管理のシンプル化
運用フローの見直し
運用業務の効率化
→テンプレートに時間費やす
MIB情報のズレ→ダイナミックに
運用工数の削減
大規模監視対応
お客様のご要望に応じたカスタマイズ
1名しかわからないシステム
パラメータを1から
お客様専用インターフェースの開発
運用手順の明確化、人依存からの脱却
仮想環境でのZabbix導入
監視項目をつめすぎない:運用コスト
GUIでの設定が可能
仮想環境での導入
事例から見る課題と解決
成功のために
監視設計
運用フロー見直し
かんしれべる設定
パフォーマンス
■ハイブリッドクラウド環境監視自動化
Zabbixプラグイン HyClops for zabbix
・バックグラウンド
仮想化、クラウド化
DevOps
Zabbix利用者増えている・機能豊富
・仮説
できるだけ自動化:自動監視設定
複数の環境:1つの口に統合
ZabbixUIの使用感
→運用作業の負担減
ソリューション
・動的に変化する環境を追い続ける
Zabbixと各環境のAPI連携
・ハイブリッド化
メタクラウドAPIを活用した処理の統合
・ZabbixのUI
Zabbixダッシュボードへの表示項目追加
HyClops for Zabbix
・2013年7月12日OSS→だれでも使える
・公開先はGitHub
アーキテクチャ
・API=pythonのめたクラウドAPI
→これをHyClopsがたたく
・SSH:ブラウザでできる
ZABBIX API:ホスト作成、監視テンプレート自動設定
ZABBIX CENTER:
自動化を突き詰めると結構作りこまないといけない
HyClops:裏でがんばってくれる
デモ
2.2との比較
(1)対象環境の違い
(2)監視方式の違い
HyClopse:ZABBIX API
2.2:性能よく作られている
(3)自動化できる項目の違い
(4)対応バージョンの違い
HyClopse:2.0から
Postgres監視用テンプレート
pg_monz
■クラウド環境でのシステム監視運用ポイント
・人材ソリューション系
・運用管理系に力を入れている
・Zabbix:大規模、細かい設定OK
インシデントマネージャー
ログの統合分析:スクランブル?
・クラウド
いつ、だれが、どのくらいデプロイするのかわからない
Zabbix2.0、2.2
根本問題
利用者が自由にできる
↓
課題
全体のリソース
申し込みコントロール
障害範囲の把握
↓
まず、すべきこと
状態把握
REDMINE→Incident Manager
過去に誰かがやった対応も
カスタマイズ
構成イメージ
てなかんじかな・・・
・Zabbix導入事例にみる課題と効果とは
・ハイブリッドクラウド環境監視自動化
Zabbixプラグイン HyClops for zabbix
・クラウド環境でのシステム監視運用ポイント
の話をまとめて、メモメモ
■Zabbix導入事例にみる課題と効果とは
クロス・ヘッド(株)
クロスヘッド自身の導入
・商用サービス
カスタムメイドな監視サービス
→監視ツールのみなおし:ツールのアーキテクチャ
オープンソースでありながらサポート:ZABBIX採用
7ヶ月くらいかけて見直し
・導入効果
運用作業のシンプル化
収益貢献:要件定義の精度貢献
・事例
商用ツール保守コスト削減
→ツール3種類、保守費用、既存監視環境あいまい
ツール管理のシンプル化
運用フローの見直し
運用業務の効率化
→テンプレートに時間費やす
MIB情報のズレ→ダイナミックに
運用工数の削減
大規模監視対応
お客様のご要望に応じたカスタマイズ
1名しかわからないシステム
パラメータを1から
お客様専用インターフェースの開発
運用手順の明確化、人依存からの脱却
仮想環境でのZabbix導入
監視項目をつめすぎない:運用コスト
GUIでの設定が可能
仮想環境での導入
事例から見る課題と解決
成功のために
監視設計
運用フロー見直し
かんしれべる設定
パフォーマンス
■ハイブリッドクラウド環境監視自動化
Zabbixプラグイン HyClops for zabbix
・バックグラウンド
仮想化、クラウド化
DevOps
Zabbix利用者増えている・機能豊富
・仮説
できるだけ自動化:自動監視設定
複数の環境:1つの口に統合
ZabbixUIの使用感
→運用作業の負担減
ソリューション
・動的に変化する環境を追い続ける
Zabbixと各環境のAPI連携
・ハイブリッド化
メタクラウドAPIを活用した処理の統合
・ZabbixのUI
Zabbixダッシュボードへの表示項目追加
HyClops for Zabbix
・2013年7月12日OSS→だれでも使える
・公開先はGitHub
アーキテクチャ
・API=pythonのめたクラウドAPI
→これをHyClopsがたたく
・SSH:ブラウザでできる
ZABBIX API:ホスト作成、監視テンプレート自動設定
ZABBIX CENTER:
自動化を突き詰めると結構作りこまないといけない
HyClops:裏でがんばってくれる
デモ
2.2との比較
(1)対象環境の違い
(2)監視方式の違い
HyClopse:ZABBIX API
2.2:性能よく作られている
(3)自動化できる項目の違い
(4)対応バージョンの違い
HyClopse:2.0から
Postgres監視用テンプレート
pg_monz
■クラウド環境でのシステム監視運用ポイント
・人材ソリューション系
・運用管理系に力を入れている
・Zabbix:大規模、細かい設定OK
インシデントマネージャー
ログの統合分析:スクランブル?
・クラウド
いつ、だれが、どのくらいデプロイするのかわからない
Zabbix2.0、2.2
根本問題
利用者が自由にできる
↓
課題
全体のリソース
申し込みコントロール
障害範囲の把握
↓
まず、すべきこと
状態把握
REDMINE→Incident Manager
過去に誰かがやった対応も
カスタマイズ
構成イメージ
てなかんじかな・・・
11月21日のET2013で聴いてきた話の続き
永遠の課題FPGAの品質向上の扉を開く!
実機デバッグの限界を解決するノウハウを教えます。
CMエンジニアリング(株)
の内容をメモメモ
はじめに
会社紹介
検証サービス
仕様書からRTL自動生成ツール
FPGA設計品質向上のコツを教えます
・セミナー受講者の興味範囲
仕様書・検証項目に興味あり
テストベンチ・CDC検証に興味あり
・FPGAユーザーの声
仕様書を書く暇はない
仕様は頭の中、個人資料しかない
→ドキュメントの重要性は認識している
シミュレーションに費やす時間ははい
実機検証で何とかなる
テストベンチ設計が難しい
非同期回路の対策が明確になってない
非同期の真の問題点を理解していない
非同期設計、検証方法が確立されていない
アサーションなどの最新手法導入の壁が高い
シミュレーターがサポートしていない
最新手法がどんなものがあるかわからない
FPGA品質向上への問題解決の鍵
FPGAの3つの課題
機能の複雑化
検証ボリューム増大
FPGA早期完動
・シミュレーションと実機検証の併用
・個人スキルからの脱却
・非同期回路設計・検証手法の確立
→FPGA品質向上へ問題解決の鍵
品質問題事例
初期品質問題
シミュレーションの役割
シミュレーションの活用
画像、映像系の各パラメーター
設定パラメーター
タイミングパラメーター
画像データパラメータ
各パラメータの振りを実機検証ですべて行うのは難しい
コーナーケース検証もれ
検証漏れ:検証すべき項目が挙がっていない
3大要因
1.仕様の解釈を誤っていた
2.検証項目からもれていた
3.検証項目としてあがっていたが、実行していなかった
→仕様書の重要性
非同期回路の設計ミス
・シミュレーションも実機検証も問題なかったのに
→出荷後に発覚するケース
メタ・ステーブルの問題:FF2段
でできないもの
リコンバージェンスの問題
データの取りこぼし問題
→非同期回路の真の問題点を理解しよう
何をする
シミュレーションと実機検証の役割分担
シミュレーション得意
詳細な検証
ブロック単位での検証
部分的、詳細、例外的な検証に向き、変更後の対応、確認もしやすい
実機検証
長時間検証
外部デバイスとの検証
ソフトウェアとの検証
システム検証
外部デバイスとの長時間検証、ソフトウェアを含めたシステム検証にむいている
シミュレーションと実機検証の役割分担
シミュレーション:各設定パラメータ振り、組み合わせ
実機検証:ユースケースのシステム動作
テストベンチの基本構成の確立
テストベンチを独立した部品と考え、再利用
チェックの自動化
目視確認時の見落としなどのミスを低減することで
品質が大幅に向上
データチェック
タイミング:アサーションチェック
アサーション適用
PSL,SVAを使いたいが、シミュレーターが対応していない
→OVLの導入
検証済みチェックIP
仕様書の重要性
1.回路の大規模化、短TAT化
仕様書を作成する上での3つの視点
1.設計者の視点
2.第三者の視点
3.検証者の視点
動作条件、競合、
ドキュメント記述ルール
用語集
非同期回路設計
D-^FF同期化
MUX同期化
ハンドシェーク
FIFO
検証戦略
ダイナミック検証
フォーマル検証
IPのため検証しない
まとめ
1.シミュレーションと実機検証の併用
2.仕様書の重要性を理解
3.非同期設計、検証手法の確立
設計レス・設計/検証自動化
(あとはすぺっくいんさいとのせんでん)
このあと、Microsoft conference 2013に行きました。
永遠の課題FPGAの品質向上の扉を開く!
実機デバッグの限界を解決するノウハウを教えます。
CMエンジニアリング(株)
の内容をメモメモ
はじめに
会社紹介
検証サービス
仕様書からRTL自動生成ツール
FPGA設計品質向上のコツを教えます
・セミナー受講者の興味範囲
仕様書・検証項目に興味あり
テストベンチ・CDC検証に興味あり
・FPGAユーザーの声
仕様書を書く暇はない
仕様は頭の中、個人資料しかない
→ドキュメントの重要性は認識している
シミュレーションに費やす時間ははい
実機検証で何とかなる
テストベンチ設計が難しい
非同期回路の対策が明確になってない
非同期の真の問題点を理解していない
非同期設計、検証方法が確立されていない
アサーションなどの最新手法導入の壁が高い
シミュレーターがサポートしていない
最新手法がどんなものがあるかわからない
FPGA品質向上への問題解決の鍵
FPGAの3つの課題
機能の複雑化
検証ボリューム増大
FPGA早期完動
・シミュレーションと実機検証の併用
・個人スキルからの脱却
・非同期回路設計・検証手法の確立
→FPGA品質向上へ問題解決の鍵
品質問題事例
初期品質問題
シミュレーションの役割
シミュレーションの活用
画像、映像系の各パラメーター
設定パラメーター
タイミングパラメーター
画像データパラメータ
各パラメータの振りを実機検証ですべて行うのは難しい
コーナーケース検証もれ
検証漏れ:検証すべき項目が挙がっていない
3大要因
1.仕様の解釈を誤っていた
2.検証項目からもれていた
3.検証項目としてあがっていたが、実行していなかった
→仕様書の重要性
非同期回路の設計ミス
・シミュレーションも実機検証も問題なかったのに
→出荷後に発覚するケース
メタ・ステーブルの問題:FF2段
でできないもの
リコンバージェンスの問題
データの取りこぼし問題
→非同期回路の真の問題点を理解しよう
何をする
シミュレーションと実機検証の役割分担
シミュレーション得意
詳細な検証
ブロック単位での検証
部分的、詳細、例外的な検証に向き、変更後の対応、確認もしやすい
実機検証
長時間検証
外部デバイスとの検証
ソフトウェアとの検証
システム検証
外部デバイスとの長時間検証、ソフトウェアを含めたシステム検証にむいている
シミュレーションと実機検証の役割分担
シミュレーション:各設定パラメータ振り、組み合わせ
実機検証:ユースケースのシステム動作
テストベンチの基本構成の確立
テストベンチを独立した部品と考え、再利用
チェックの自動化
目視確認時の見落としなどのミスを低減することで
品質が大幅に向上
データチェック
タイミング:アサーションチェック
アサーション適用
PSL,SVAを使いたいが、シミュレーターが対応していない
→OVLの導入
検証済みチェックIP
仕様書の重要性
1.回路の大規模化、短TAT化
仕様書を作成する上での3つの視点
1.設計者の視点
2.第三者の視点
3.検証者の視点
動作条件、競合、
ドキュメント記述ルール
用語集
非同期回路設計
D-^FF同期化
MUX同期化
ハンドシェーク
FIFO
検証戦略
ダイナミック検証
フォーマル検証
IPのため検証しない
まとめ
1.シミュレーションと実機検証の併用
2.仕様書の重要性を理解
3.非同期設計、検証手法の確立
設計レス・設計/検証自動化
(あとはすぺっくいんさいとのせんでん)
このあと、Microsoft conference 2013に行きました。
あんまり、現役ホームレスの人が、
「金持ちになる方法」とか言っても、信じないですよね。
Fランク大学に入学、卒業した人が
「東京大学に合格する方法」って言っても、信じないですよね・・・
ところで!
SIerさんって、ビッグデータとかいう話で、
いろいろ、データ予測するツールや手法を出していますよね!
で、
SIerさんにとって、一番身近なデータ予測っていうのは、
開発見積もりですよね。
っていうことは、SIerさんは、ビッグデータ解析ツールを
売るくらいだから、さぞや解析は上手、
開発見積もりなんていうのは、ばっちり予測できるはずですよね。
その売り物のビッグデータ解析ツールがすばらしいのならば・・・
で、
開発見積もりって、合ってる?
合ってないのにビッグデータを信じる?
「金持ちになる方法」とか言っても、信じないですよね。
Fランク大学に入学、卒業した人が
「東京大学に合格する方法」って言っても、信じないですよね・・・
ところで!
SIerさんって、ビッグデータとかいう話で、
いろいろ、データ予測するツールや手法を出していますよね!
で、
SIerさんにとって、一番身近なデータ予測っていうのは、
開発見積もりですよね。
っていうことは、SIerさんは、ビッグデータ解析ツールを
売るくらいだから、さぞや解析は上手、
開発見積もりなんていうのは、ばっちり予測できるはずですよね。
その売り物のビッグデータ解析ツールがすばらしいのならば・・・
で、
開発見積もりって、合ってる?
合ってないのにビッグデータを信じる?
11月21日にET2013に行って来た!ことは前に書いたけど、
そのときのセミナーのつづき。
今回は、
最新ARM内臓FPGAを使うには
CortexA9システムとソフトウェアの実装
について、メモメモ
実装の流れ、ハードとソフトの融合
アジェンダ
アルテラSoCソリューション
アルテラSoC開発環境
HWデザイン
SWデバッグ
アルテラSoCソリューション
広範な組組み込みプロセッサをサポート
QuartusⅡ→Qsys内臓
・プロセッサ
ARM Cortex
NIOSⅡ(ソフトコア)→これからも!
→機能分散あり!
フルコンパチンブルMIPS
CortrxM1あろー
NIOSⅡミッションクリティカル
フリースケール
→全部Qsysでできる
・OpenCL
・DSPBuilder
第一世代:ARM CortexA9
第二世代:Arria10
第三世代:ARM CortexA53クワッドコア
ARM CortexA53 Stratix10
・高い性能+高い消費電力効率
6倍以上のデータ処理能力
64ビットプロセッサにおいて、高い消費電力効率
28nm製品概要、アルテラSoC製品
・デュアルコアARM CortexA9
ARMエコシステム
Qsysシステム統合ツール
ARM DS5 アルテラエディションによる
CPU-FPGA協調デバッグ
システムアーキテクチャ
プロセッサ:ハイエンドなプロセッサ
→1GHzちかく
シングルコア
ECC32ビット
FPGAサイドにメモリ
内部バス128ビット
Cycloneにも対応:ハードPCIs/トランシーバ
コンフィグレーションにおける究極の柔軟性
FPGAはFPGA,プロセッサはプロセッサ別々できる
プロセッサからFPGAもできる
FPGAから立ち上げてプロセッサもできる
アルテラSoC開発環境
・デザインフロー2つ
FPGAデザインフロー
Quartus2、Qsys
ソフトウェアデザインフロー
ARMと連携取れる:今のJTAGデバッガー
・アルテラSoC
Linuxカーネル周辺ペリフェラル提供
→アルテラEDS
HW/SWハンドオフ
協調デバッグ
・アルテラSoCブロック図
HPS(ハードウエアプロセッサシステム)
FPGA
・HW設計
HPS
どのペリフェラルつかうか
HPS FPGAインターフェース
どのインターフェース信号を使うか
FPGA
従来どおり
→Qsysで(ふつうのIPと同じかんじ)
インターフェース
Altera:あばろんインターフェース
+
ARM:AXI3,AXI4・・・
→ネットワーク on チップ:Qsysインターコネクト
無償のQuartusⅡの中に入っている
ハードウェア開発フロー
SOFを作る
自動でプリローダーを作る
ソフトウェア開発方法
SW開発
OS活用?/ベアメタル・商用OS?
OSベンダIDE?
→AlteraEDS
Linuxはただ
FPGA対応デバッグ方法:1ヶ月無償、その後有償
クロスドメインデバッグ
→ソフトウェアトリガー→ハードウェアの状況表示
FPGAから、ソフトウェアへトリガー
シグナルタップ
RocketBoard.orgのアルテラSoC情報
XWindowSDI version demo in Ubuntu
そのときのセミナーのつづき。
今回は、
最新ARM内臓FPGAを使うには
CortexA9システムとソフトウェアの実装
について、メモメモ
実装の流れ、ハードとソフトの融合
アジェンダ
アルテラSoCソリューション
アルテラSoC開発環境
HWデザイン
SWデバッグ
アルテラSoCソリューション
広範な組組み込みプロセッサをサポート
QuartusⅡ→Qsys内臓
・プロセッサ
ARM Cortex
NIOSⅡ(ソフトコア)→これからも!
→機能分散あり!
フルコンパチンブルMIPS
CortrxM1あろー
NIOSⅡミッションクリティカル
フリースケール
→全部Qsysでできる
・OpenCL
・DSPBuilder
第一世代:ARM CortexA9
第二世代:Arria10
第三世代:ARM CortexA53クワッドコア
ARM CortexA53 Stratix10
・高い性能+高い消費電力効率
6倍以上のデータ処理能力
64ビットプロセッサにおいて、高い消費電力効率
28nm製品概要、アルテラSoC製品
・デュアルコアARM CortexA9
ARMエコシステム
Qsysシステム統合ツール
ARM DS5 アルテラエディションによる
CPU-FPGA協調デバッグ
システムアーキテクチャ
プロセッサ:ハイエンドなプロセッサ
→1GHzちかく
シングルコア
ECC32ビット
FPGAサイドにメモリ
内部バス128ビット
Cycloneにも対応:ハードPCIs/トランシーバ
コンフィグレーションにおける究極の柔軟性
FPGAはFPGA,プロセッサはプロセッサ別々できる
プロセッサからFPGAもできる
FPGAから立ち上げてプロセッサもできる
アルテラSoC開発環境
・デザインフロー2つ
FPGAデザインフロー
Quartus2、Qsys
ソフトウェアデザインフロー
ARMと連携取れる:今のJTAGデバッガー
・アルテラSoC
Linuxカーネル周辺ペリフェラル提供
→アルテラEDS
HW/SWハンドオフ
協調デバッグ
・アルテラSoCブロック図
HPS(ハードウエアプロセッサシステム)
FPGA
・HW設計
HPS
どのペリフェラルつかうか
HPS FPGAインターフェース
どのインターフェース信号を使うか
FPGA
従来どおり
→Qsysで(ふつうのIPと同じかんじ)
インターフェース
Altera:あばろんインターフェース
+
ARM:AXI3,AXI4・・・
→ネットワーク on チップ:Qsysインターコネクト
無償のQuartusⅡの中に入っている
ハードウェア開発フロー
SOFを作る
自動でプリローダーを作る
ソフトウェア開発方法
SW開発
OS活用?/ベアメタル・商用OS?
OSベンダIDE?
→AlteraEDS
Linuxはただ
FPGA対応デバッグ方法:1ヶ月無償、その後有償
クロスドメインデバッグ
→ソフトウェアトリガー→ハードウェアの状況表示
FPGAから、ソフトウェアへトリガー
シグナルタップ
RocketBoard.orgのアルテラSoC情報
XWindowSDI version demo in Ubuntu
11月22日 ZABBIX Conference 2013に行って来た!話のつづき
2つめの話
システム運用最前線・調査と事例に見る課題と解決策
日経BPの人
の内容をメモメモ
・情報システムの運用に関する問題意識
・調査に見る運用現場の課題と取り組み
・事例に見る課題解決
情報システムの運用に関する問題意識
・運用の負担は、増大の一途
→効率化、生産性向上が必要
・従来になかった運用業務:クラウド、スマホ
→多様化
・ITコスト削減/抑制要求
・運用起点のIT利用へ
→共通フレーム2013
2007年 要求定義をしっかりやりましょう
2013年 運用が起点
調査に見る運用現場の課題と取り組み
・全国4000社のユーザー企業→627社から回答
・IT関連コストの内訳
ITコストの内訳
運用管理・保守開発:75%をしめる
IT関連コストの今後の見通し
新規開発を増やす4割
運用開発・保守開発:増やすのは2割
→減らす、現状維持8割
・システム運用の課題
ノウハウが属人化
特定のスタッフに業務かたより
人材育成できていない
担当者多忙
→人材に関すること
・運用課題の取り組み
ノウハウの属人化:改善へ取り組み
人材育成:それに比べると、できていない
予算の確保は5割くらいが、取り組みたいけど取り組めない
課題への取り組み
1.コストの視点
2.仮想化・クラウドの視点
3.自動化・運用プロセスの視点
1.コストの視点
運用管理コストの項目内訳
人件費 22%
保守サポート
リース料
減価償却費
かかりすぎと感じている
保守サポート
ライセンス料
リース料
コストをかけられていない部分
人件費
業務委託費
外注費
→いかに外部をつかっていくか
コストを増やせない中での取り組み
2.仮想化、クラウド
サーバー仮想化:使っているのは半数を超えている
クラウドサービス:一部まで含めると、半数超えている
→大部分クラウドは少ない(一部40%)
目的
コスト削減
クラウドはコスト削減以外は、安定稼動、DR(障害復旧)
運用の観点から
サーバー仮想化:
障害の影響範囲確定が困難・・など
ただし、特にないが4割で一番多い
クラウド
特にないが多いが、2割程度(少ない)
オンプレミスよりコストが高い
サービスの継続性
障害発生の制約
3.運用プロセス/自動化の視点
自動化による効率化が求められている
属人化の排除
仮想化/クラウドのサービス感
運用品質の向上
↓
運用プロセスの見える化
運用プロセスの標準化
運用プロセスの自動化
ツール
監視ルーツとかはおおい
運用手順の自動化はまだまだ
事例に見る課題解決の取り組み
今求められるシステム運用
忍耐、献身にみる「受身の運用」
自ら問題を発見して、解決・改善していく「攻めの運用」
見える化・標準化・最適化・自動化・迅速化
運用作業をポイント化して生産性を把握
自動化でサーバー利用申請プロセスを極限まで短縮
Chefでサーバー構築、構成変更を完全自動化
まとめ
なかんじ・・
2つめの話
システム運用最前線・調査と事例に見る課題と解決策
日経BPの人
の内容をメモメモ
・情報システムの運用に関する問題意識
・調査に見る運用現場の課題と取り組み
・事例に見る課題解決
情報システムの運用に関する問題意識
・運用の負担は、増大の一途
→効率化、生産性向上が必要
・従来になかった運用業務:クラウド、スマホ
→多様化
・ITコスト削減/抑制要求
・運用起点のIT利用へ
→共通フレーム2013
2007年 要求定義をしっかりやりましょう
2013年 運用が起点
調査に見る運用現場の課題と取り組み
・全国4000社のユーザー企業→627社から回答
・IT関連コストの内訳
ITコストの内訳
運用管理・保守開発:75%をしめる
IT関連コストの今後の見通し
新規開発を増やす4割
運用開発・保守開発:増やすのは2割
→減らす、現状維持8割
・システム運用の課題
ノウハウが属人化
特定のスタッフに業務かたより
人材育成できていない
担当者多忙
→人材に関すること
・運用課題の取り組み
ノウハウの属人化:改善へ取り組み
人材育成:それに比べると、できていない
予算の確保は5割くらいが、取り組みたいけど取り組めない
課題への取り組み
1.コストの視点
2.仮想化・クラウドの視点
3.自動化・運用プロセスの視点
1.コストの視点
運用管理コストの項目内訳
人件費 22%
保守サポート
リース料
減価償却費
かかりすぎと感じている
保守サポート
ライセンス料
リース料
コストをかけられていない部分
人件費
業務委託費
外注費
→いかに外部をつかっていくか
コストを増やせない中での取り組み
2.仮想化、クラウド
サーバー仮想化:使っているのは半数を超えている
クラウドサービス:一部まで含めると、半数超えている
→大部分クラウドは少ない(一部40%)
目的
コスト削減
クラウドはコスト削減以外は、安定稼動、DR(障害復旧)
運用の観点から
サーバー仮想化:
障害の影響範囲確定が困難・・など
ただし、特にないが4割で一番多い
クラウド
特にないが多いが、2割程度(少ない)
オンプレミスよりコストが高い
サービスの継続性
障害発生の制約
3.運用プロセス/自動化の視点
自動化による効率化が求められている
属人化の排除
仮想化/クラウドのサービス感
運用品質の向上
↓
運用プロセスの見える化
運用プロセスの標準化
運用プロセスの自動化
ツール
監視ルーツとかはおおい
運用手順の自動化はまだまだ
事例に見る課題解決の取り組み
今求められるシステム運用
忍耐、献身にみる「受身の運用」
自ら問題を発見して、解決・改善していく「攻めの運用」
見える化・標準化・最適化・自動化・迅速化
運用作業をポイント化して生産性を把握
自動化でサーバー利用申請プロセスを極限まで短縮
Chefでサーバー構築、構成変更を完全自動化
まとめ
なかんじ・・
統計モデル その2 確認的因子分析のlavaan、SEMパス図のsemPlot
http://blog.goo.ne.jp/xmldtp/e/67d20f131517b9fb1b5e55963ecb72fa
の続き。授業の「統計モデル」の内容をメモメモ
構成概念とは
構成概念とは、直接観測することはできないけれども、
それを定義することにより観測された現象をうまく説明
できるようになる事柄
確認的因子分析
・測定しようとしている構成概念を定義
・定義に従って項目を作成
・データ収集
・構成概念=因子の確認
・信頼性と妥当性
探索的因子分析
・構成概念を測定していそうな項目
・作成した項目データ調べる
・構成概念=因子がわかってくる
・後付的に定義する
・信頼性と妥当性
因子分析
・変数間のまとまりを見つける方法
・相関の高い変数同士が同じ因子にまとまる
確認的因子分析
・各観測変数がどの因子の影響を受けているかを
仮説としてモデル化する
・適合度で検討
・モデルが識別されている必要がある
結果でてこない→識別されていない
誤差
・誤差=特殊因子+測定誤差
因子負荷量
・因子から受けている影響の大きさ
因子分析と回帰分析
対応がある
カイ2乗検定の結果の見方
Number of observationsのほうを見る
Model test baseline modelではない
→こちらは独立モデル。変数間に関係がないと仮定したもの
CFI:独立モデルにくらべ、どっちがいいか
loglikelihood:対数尤度
対数尤度の2つの差をとって2倍するとカイ2乗値
2*対数尤度+2*自由度=AIC
因子名:方向性をもっている
→わからないのはX
因子の向きの影響
カイ二乗検定
・きむ仮説は「モデルはデータに適合されている」
識別(identification)
・連立方程式の解:3つにわかれる
丁度識別:解ける
識別不能:すべてを満たすものはない
識別不定:
識別不能の方程式
どちらが適切そうか?
不適切さの程度を最小にするような組を見つける
→最小二乗法
不適切さの程度が適合度と同等
丁度識別の確認的因子分析モデル
答えは1組
因子の分散=1とする
適切さでもとめる
識別不定
求まらない
SEM(共分散構造分析)のしくみ
・標本データから計算される観測変数間の共分散行列S
・パラメータで表現された観測変数間の共分散行列Σ
・sとΣの差を小さくするパラメータの推定
(重複する部分はいれないでOK)
4つの場合
方程式の本数>パラメータ数
なので、識別不能
2つの場合
方程式の本数3>パラメータ数4
なので、解けない(識別不定)
誤差の分散
S :データがあれば求まる
Σ:モデルがあれば求まる
S=Σでとく
なぜ因子の分散=1、誤差からの係数=1としたか
→逆に1にしなかったとしたら・・・
方程式を立ててとこうとすると・・・・
パラメータが増えて、方程式のほうがすくなくなる
ので、解けない
→そこで、1にした
・・・って、していいの?
因子負荷量のあるところ、因子の分散が出る
因子は単位がない
そこで、因子の分散1
確認的因子分析
・V(f)を1に固定
・因子負荷量の1つを固定する
らばーんは、後者:1においたところ点線
→そこから標準化
適合度と自由度
・連立方程式に良く当てはまる解であるほど、
適合度は高くなる
・丁度識別のとき:完全な適合になる
→適合度は検討できない
・識別不能のとき:適合度を検討できる
・識別不定のとき:適合度は検討できない
自由度
・自由度=連立方程式の本数-パラメータ数
・自由度0:丁度識別
・自由度正:識別不能
・自由度負:識別不定
統計モデル=データ
適合度はモデルとデータの適合の度合い
モデルを変更すると
Sは変わらない(データは変わらない・方程式の右辺は変わらない)
Σは変わる(モデルは変わる・連立方程式の左辺は変わる)
モデルを変更すると、SとΣが近くなる可能性があるので、モデル比較を行う
モデル比較
・複数のモデルの中で、もっとも良いモデルは何か
倹約的なモデル
・SとΣを近づける
→パラメータをいっぱい入れればいい
→そのデータにしか当てはまらなくなる
→頑健なモデル:より少ないパラメータで
・RMSEA,AIC,BICは倹約的な考え方を含んでいる
SEMによる単回帰分析
・単回帰モデルのΣ(共分散構造)
→丁度識別で解ける
・切片はどこにいったの?
SEMで切片を推定するには、
平均・共分散構造分析を使わないとできない
因子分析:共通性→回帰分析:決定係数
誤差の分散=Variance
観測変数の分散=共通性+独自性=1
Rで実行
library(lavaan)
model1<-'rating~complaints'
fit1<-sem(model1,data=attitude)
summary(fit1,standardized=TRUE,fit.measures=TRUE,rsquare=TRUE)
SEMによる重回帰分析
Rで実行
modelがちがう
ほか同じ
3つ観測変数があって、共分散構造分析
a1,a2,V(e)
飽和モデル:自由度0
確認的因子分析、単回帰分析、重回帰分析は
飽和モデル
良いモデル
・適合度がいい場合
・決定係数がいい場合
決定係数;説明できない部分がどれくらい残るか
適合度はいいが、決定係数小さい
→モデルで説明できる。よくある
決定係数がいいが、適合がわるい
→あまりないけど
R
lower対角行列の下だけ入ってる
11月22日にZABBIX Conference 2013に行って来た!
そのときの話をメモメモ
今回は、一番初め
■Where We are
「あれっくす うらじじぇふ」さん
参加者(登録者)250人超えている
→リガより大規模
トピックス
ZABBIX2.2の新機能
ZABBIX2.2アップデート方法
サポートポリシー
ZABBIX2.4
Zabix2.2
100以上の新機能と改善項目
・VMWareのサポート
→自動的に始まる
・利用可能なテンプレート
→VMWareのゲスト、ハイパーバイザーのモニタリングがはいる
・パフォーマンスの改善
2.0より2~5倍高速
・メモリ上のvalueキャッシュ導入
→トリガー処理はやい
・容易なメンテナンス
内部イベントのサポート
・同一アプリケーション名を持つ
テンプレートのリンクが可能
・自動登録がより柔軟に
メタデータ情報使える
AWSのホスト名
・housekeeper制御の最適化
・ユーザー権限
読み込み権限:書き込み権限の上書きしない
・内部監視
プロキシ内部のモニタリング
Zabbixのプロセスの役割をシェルで表示
・データ収集
エージェント側の改善
ZABBIXエージェントにより多くのチェックがサポート
Windows用ZabbixエージェントがWMIをサポート
→Windows環境対応
ローダブルモジュールのサポート
・Webモニタリングの改善
Webシナリオのテンプレート
リトライ回数設定可能
HTTPプロキシサポート
セッションIDを取得できる
障害検知
・トリガー:2048文字まで拡張
インテグレーション
・階層構造のユーザースクリプト
・ZABBIX API
100%ドキュメント化
・WindowsDLL
Zabbixセンター機能
→お客様はすでに商用環境で使用
<<アップグレード方法>>
(1)バイナリー、データベース、設定ファイルを
バックアップ
(2)サーバーとプロキシ停止、Webインターフェース
より、メンテナンスモードに設定
(3)サーバーとプロキシのバイナリ、
Webインターフェースをインストール
(4)新しいバイナリを実行
・データベースの自動化アップデートする
→手動でしなくていい
・下位互換性を担保
→エージェントをアップデートする必要はない
サポートポリシー
・1.6.Xサポートなし
・1.8 2.4が出るまで
→2.4は来年末までに(リリース1年おき)
・2.0以降 5年間のサポート
3年間 バグフィックス
5年間 致命的またはセキュリティ関係
Zabbix2.4 ロードマップ
・要望:Zabbix日本支社へ→将来的に見積もり
→来年末までに提供
→影響を与えることができる
来年11月リリース予定
6、7割が2.0のこり1.8
勇敢なかたがた(2.2利用者)4人
2.0から2.2へのアップグレード
→2.0から1.8だと、手動実行、パッチ当てる
来週、2.2.1
・いくつかのFIX
・重大なものない
Q&A
・他の仮想化、ハイパーバイザーは?
→2.4のロードマップはまだきまっていない
具体的には→Hyper-V,KVM
→いつかはサポートされるだろうか、いつとはいえない
重要な点:2.2→より仮想環境
そのときの話をメモメモ
今回は、一番初め
■Where We are
「あれっくす うらじじぇふ」さん
参加者(登録者)250人超えている
→リガより大規模
トピックス
ZABBIX2.2の新機能
ZABBIX2.2アップデート方法
サポートポリシー
ZABBIX2.4
Zabix2.2
100以上の新機能と改善項目
・VMWareのサポート
→自動的に始まる
・利用可能なテンプレート
→VMWareのゲスト、ハイパーバイザーのモニタリングがはいる
・パフォーマンスの改善
2.0より2~5倍高速
・メモリ上のvalueキャッシュ導入
→トリガー処理はやい
・容易なメンテナンス
内部イベントのサポート
・同一アプリケーション名を持つ
テンプレートのリンクが可能
・自動登録がより柔軟に
メタデータ情報使える
AWSのホスト名
・housekeeper制御の最適化
・ユーザー権限
読み込み権限:書き込み権限の上書きしない
・内部監視
プロキシ内部のモニタリング
Zabbixのプロセスの役割をシェルで表示
・データ収集
エージェント側の改善
ZABBIXエージェントにより多くのチェックがサポート
Windows用ZabbixエージェントがWMIをサポート
→Windows環境対応
ローダブルモジュールのサポート
・Webモニタリングの改善
Webシナリオのテンプレート
リトライ回数設定可能
HTTPプロキシサポート
セッションIDを取得できる
障害検知
・トリガー:2048文字まで拡張
インテグレーション
・階層構造のユーザースクリプト
・ZABBIX API
100%ドキュメント化
・WindowsDLL
Zabbixセンター機能
→お客様はすでに商用環境で使用
<<アップグレード方法>>
(1)バイナリー、データベース、設定ファイルを
バックアップ
(2)サーバーとプロキシ停止、Webインターフェース
より、メンテナンスモードに設定
(3)サーバーとプロキシのバイナリ、
Webインターフェースをインストール
(4)新しいバイナリを実行
・データベースの自動化アップデートする
→手動でしなくていい
・下位互換性を担保
→エージェントをアップデートする必要はない
サポートポリシー
・1.6.Xサポートなし
・1.8 2.4が出るまで
→2.4は来年末までに(リリース1年おき)
・2.0以降 5年間のサポート
3年間 バグフィックス
5年間 致命的またはセキュリティ関係
Zabbix2.4 ロードマップ
・要望:Zabbix日本支社へ→将来的に見積もり
→来年末までに提供
→影響を与えることができる
来年11月リリース予定
6、7割が2.0のこり1.8
勇敢なかたがた(2.2利用者)4人
2.0から2.2へのアップグレード
→2.0から1.8だと、手動実行、パッチ当てる
来週、2.2.1
・いくつかのFIX
・重大なものない
Q&A
・他の仮想化、ハイパーバイザーは?
→2.4のロードマップはまだきまっていない
具体的には→Hyper-V,KVM
→いつかはサポートされるだろうか、いつとはいえない
重要な点:2.2→より仮想環境




