








MongoDBについては、
NoSQLのMongoDBを立ち上げてみる
http://blog.goo.ne.jp/xmldtp/e/03c3407abbc1897423569441aa0bd976
さらに、
NoSQLのMongoDBをJavaでアクセスしてみる
http://blog.goo.ne.jp/xmldtp/e/9baed46c53212a6a14ccfe24d13d8839
で、javaでアクセスするところまではやった。
今回は、Node.jsでアクセスしてみる。
なお、今回は、以下のブログの内容を参考にしています。
node.jsでMongoDBを扱う
http://d.akiroom.com/2011-10/node-js-mongodb-native/
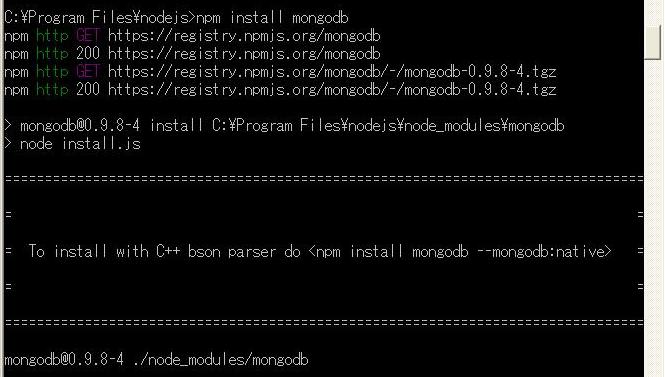
■ダウンロード&インストール
npmをつかって、
npm install mongodb
を実行するとはいる。
■ソースを作成
以下のソースをhelloworld3.jsという名前で作成しました。
なんか、汚いプログラムになっちゃってごめんなさい。
ローカルホストにある、testというDBの中に、'things'というコレクションがあって、
それをとってきて、中身を表示するプログラムです。
require('mongodb/lib/mongodb')のところは、置き場によって書き換える必要があるかもよ。
■立ち上げ
前回同様、
・まず、mongoサーバーを立ち上げます。
つまり、mongodを起動します。
(mongoでなく、mongod、サーバーのほうです)
・次に、node.jsを起動します。

・そしたら、ブラウザから、http://127.0.0.1:8124/をアクセス。
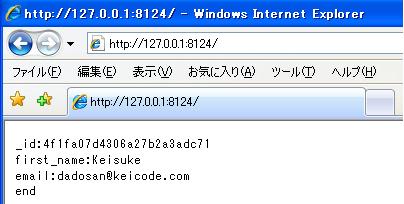
なかんじで表示できた。
今回はここまで
NoSQLのMongoDBを立ち上げてみる
http://blog.goo.ne.jp/xmldtp/e/03c3407abbc1897423569441aa0bd976
さらに、
NoSQLのMongoDBをJavaでアクセスしてみる
http://blog.goo.ne.jp/xmldtp/e/9baed46c53212a6a14ccfe24d13d8839
で、javaでアクセスするところまではやった。
今回は、Node.jsでアクセスしてみる。
なお、今回は、以下のブログの内容を参考にしています。
node.jsでMongoDBを扱う
http://d.akiroom.com/2011-10/node-js-mongodb-native/
■ダウンロード&インストール
npmをつかって、
npm install mongodb
を実行するとはいる。
■ソースを作成
以下のソースをhelloworld3.jsという名前で作成しました。
var http = require('http');
var mongo = require('mongodb/lib/mongodb');
var server = http.createServer(
function (request, response) {
response.writeHead(200, {'Content-Type': 'text/plain'});
var db = new mongo.Db('test',
new mongo.Server('localhost',mongo.Connection.DEFAULT_PORT, {}), {});
db.open(function(err, db) {
if ( err )
{
response.write("err:"+err);
response.end();
}
else
{
db.collection('things', function(err, collection) {
if ( err )
{
response.write("err:"+err);
response.end();
}
else
{
collection.find(function(err, cursor) {
if ( err )
{
response.write("err:"+err);
response.end();
}
else
{
cursor.each(function(err, item) {
if ( err )
{
response.write("err:"+err);
response.end();
}
else
{
if ( item != null )
{
for (key in item)
{
response.write(key+":"+item[key]+"\n");
}
}
else
{
response.write("end");
response.end();
}
}
});
}
});
}
});
}
});
}
).listen(8124);
|
なんか、汚いプログラムになっちゃってごめんなさい。
ローカルホストにある、testというDBの中に、'things'というコレクションがあって、
それをとってきて、中身を表示するプログラムです。
require('mongodb/lib/mongodb')のところは、置き場によって書き換える必要があるかもよ。
■立ち上げ
前回同様、
・まず、mongoサーバーを立ち上げます。
つまり、mongodを起動します。
(mongoでなく、mongod、サーバーのほうです)
・次に、node.jsを起動します。
・そしたら、ブラウザから、http://127.0.0.1:8124/をアクセス。
なかんじで表示できた。
今回はここまで


















