左の図は本を開いた内側のようにも見えますし、外側の表紙のようにも見えます。
内側に見えるときは真ん中が後退して見え、外側に見えるときは真ん中が前にせり出して見えます。
見ているうちに見え方がいつの間にか交替するので、真ん中の部分はでっぱたりへこんだりするので動いて見えます。
右の図の場合は立方体に見えるのですが、左下側の正方形が手前に見えたり、右上の正方形が手前に見えたりします。
左が前面の立方体と思ってみているうちに、いつの間にか右側が前面に見えて見え方が交替します。
左側の正方形と、右側の正方形はかわるがわる前面に出たり、後退して見えたりします。
意識的には視線を動かしていないつもりでも、視線が動き見え方の体制がかわって、奥行き感が変わるので、眼の焦点距離が変わっているのです。
左下の図では右側が暗くなっているので、左から光が当たっていると見なすと、真ん中が出っ張っているように見え、この見え方が安定します。
右下の場合は黒く塗りつぶした部分があるので、左側の正方形も、右側の正方形も一つの面と解釈しにくくなるので、立方体として見難くなり、全体が平面図形のように見えます。
右上の図の場合は、どうしても立方体に見えてしまい、立方体の見え方が交替するので図形が動いて見えてしまいますが、右下の場合は平面としてみれば安定して見えます。
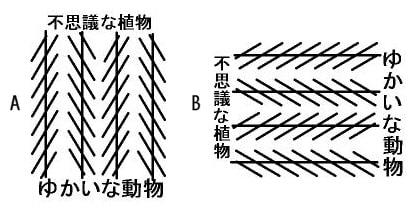
ここで図形を見るのでなく、文字のほうに注目して見ます。
左上の文字は七文字ですが、このぐらいの文字数は大体中心窩で見ることが出来る範囲なので、視線を動かさなくてもハッキリと見えると思います。
このとき下の文字は少し大きいので、ハッキリと文字が読めなくてもなんとなく読めるような感じがすると思います。
もし下の文字を読みに行こうとして視線を動かすと、このとき真ん中の図形は見え方が変わるので、奥行き感が交替して図形が動くように感じます。
視線を動かさないで下の字が認識できれば、周辺視野の文字に対する感度が上がったということになるのですが、このとき間の図形は動きません。
視線が動いたかどうかは、図形の見え方で判断できるのです。
右の図の場合も同じなのですが、左の図よりも注意を引きやすいので、文字を見ながらつい図形のほうに眼がいきがちです。
上の文字のほうに注意を向け、下の文字を視線を動かさずに周辺視野で見れば、間の図形は平面的に見えます。
つい視線を動かして図形のほうを見てしまうと、図形は立方体に見えるので、平面から立方体へと見え方が変化するとき図形は動いて見えます。
視線を動かさずに下の文字が認識できたかどうかは、図形が動いたかどうかで分かります。