









カナは音節文字なので、文字と音声がほぼ対応しています。
したがって単語を構成する文字をばらばらにおいても、一つ一つの音声を組み合わせて元がどんな順序だったか検討をつけるのが楽です。
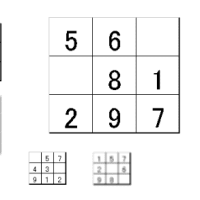
図の例で言えば「わやまか、わかまや、わかやま、やわまか、やまわか、やまかわ」などと試行錯誤して「わかやま」か「やまかわ」だなと推理できます。
文字を見ながら一つづつ音声化できるので、単語を構成している音説の順序を口の中で変えてみてみて、聞き覚えのあるものと一致するまで試行すればよいのです。
文字を並べ替えた状態を視覚的にイメージするというやり方は、文字を見ながらやろうとしても難しいし、目を閉じて文字を並べ替えるのも困難です。
「とるふさ」を視覚イメージの並べ替えで「ふるさと」に変更するのはなかなか難しいですが、音声化して並べ替えるのは楽です。
英語の場合はアルファベットは音声を表現しているといっても、文字と音素が1対1で対応しているわけではありません。
したがって単語の文字配列の順序を変えると元の配列の順序を推測するのはとても困難です。
文字の並べ替えを視覚的イメージでやるのは結構難しいので、音声を使ってやろうとするとこれがかなの場合よりも難しいのです。
最初の例では母音は「i]と「o」ですがそれぞれ発音の仕方はひと通りではないので、試行錯誤をするにも場合の数が多く、かなの場合より複雑です。
文字を一つづつ発音してその音を並べ替えるということが出来ないのでカナに比べると音声化が難しいのです。
漢字の場合も偏と旁をばらばらにしてしまうと、それぞれを音声化して、音声の並べ替えで元の単語が復元できるわけではありません。
最初の例では各部分の読みは「けい、おう、し、り」となるのですが元の単語が一文字なのか、二文字なのかあるいは三文字、四文字なのか分からないので難しいのです。
漢字や英語の単語はカナに比べると全体の視覚イメージで記憶されていて、要素をばらばらにすると元の単語を復元しにくいのです。
逆に言うと視覚イメージとして記憶しやすいということで、音読せずに読むことが可能になっているのです。



※コメント投稿者のブログIDはブログ作成者のみに通知されます