








シリーズ?
CiscoのSDN OnePKが(ルーターとかなくても)VM使って確かめられる
前回はダウンロードしてきました。
今回は、
(1)VM作成
(2)VM起動
(3)サンプル(3-node)起動
を行います。
以下のサイトを参考にしています。
onePK を使ってアプリケーションを作る – All-in-one VMのご紹介
http://gblogs.cisco.com/jp/2014/04/developing-applications-with-onepk-all-in-one-vm/
■(1)VM作成
まずは、Virtual Boxを起動します。
そしたら、
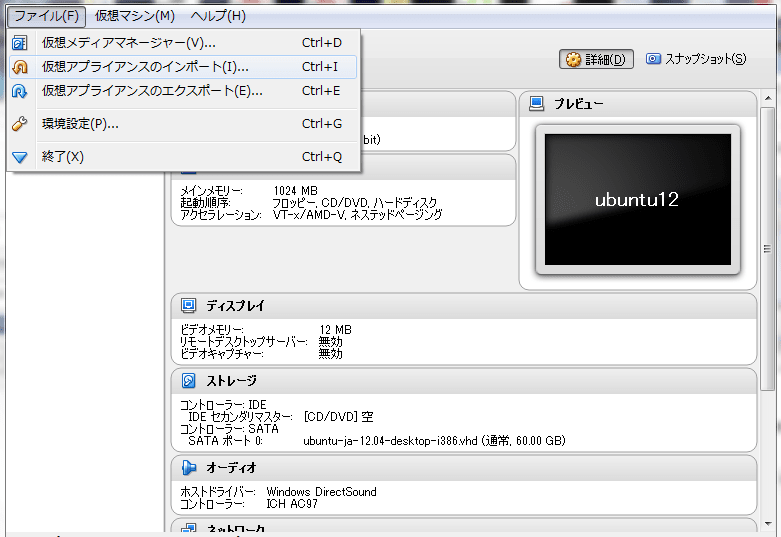
ファイル→仮想アプライアンスのインポート
出てきたダイアログで

前回ダウンロードしたOVFファイルを選択し次へ

MACアドレス、再初期化しました・・・ま、インポート
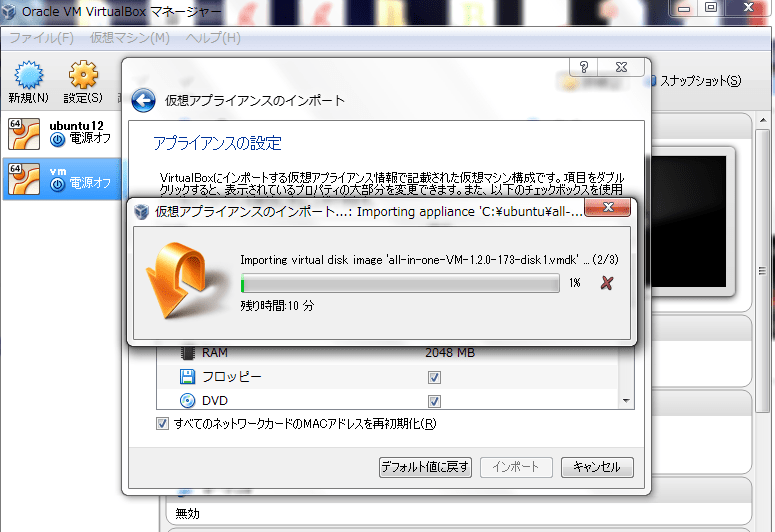
こんなかんじでがんばります。

VMができました(2個目:赤丸)
■(2)VM起動
VM(赤丸のところ)をダブルクリックして起動します。
待っていると、いつものubuntu画面に

はじめのパスワードは「cisco123」ですので、それを入力
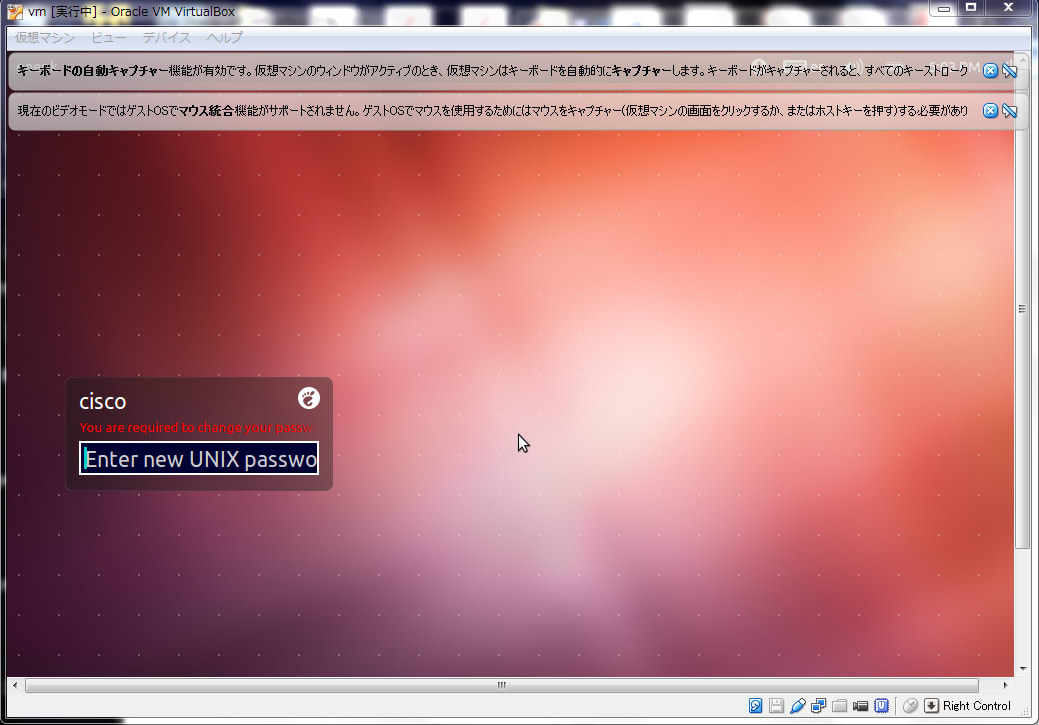
新しいパスワードを聞いてきます。適当に入れます。
もう一回、確認用に聞いてきます。同じパスワードを入れます。

I accept...をチェックして右側のボタンクリック

ネットワークシミュレーターのユーザー名とパスワードを聞いてきます。
めんどっちいので、アカウントと同じ、
ユーザー名cisco パスワードpassword
にしましたけど、好きにいれてください。

なんか、welcomeされてます・・・OK
■(3)サンプル(3-node)起動
なにしたらいいか、まったくわかりません・・・
QuickStartupGuide.pdfをあけてみます。

どうも、3-nodeというデモがあるみたい。

start3nodeというアイコン(緑のまる)をダブルクリック
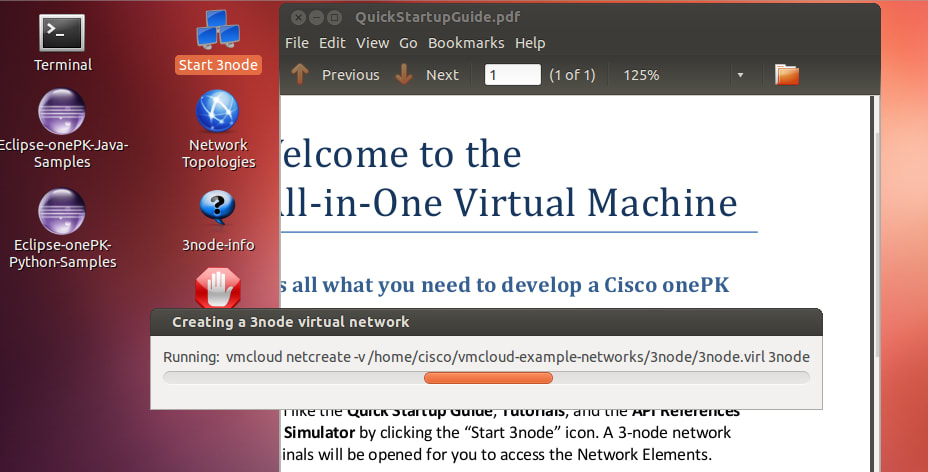
がんばってます
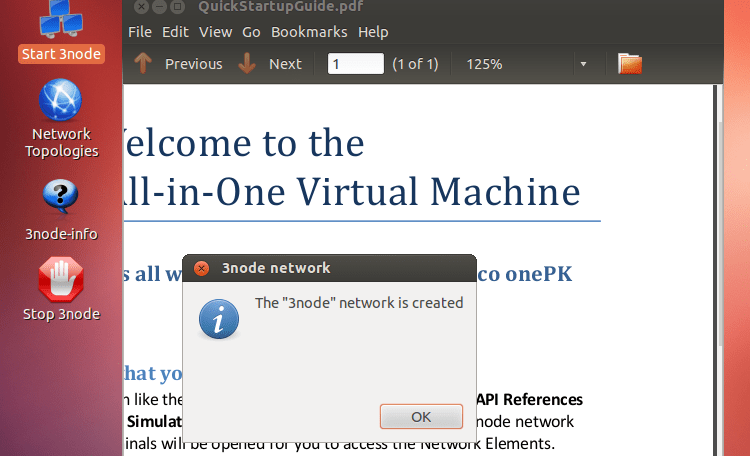
つくったそうです。OK
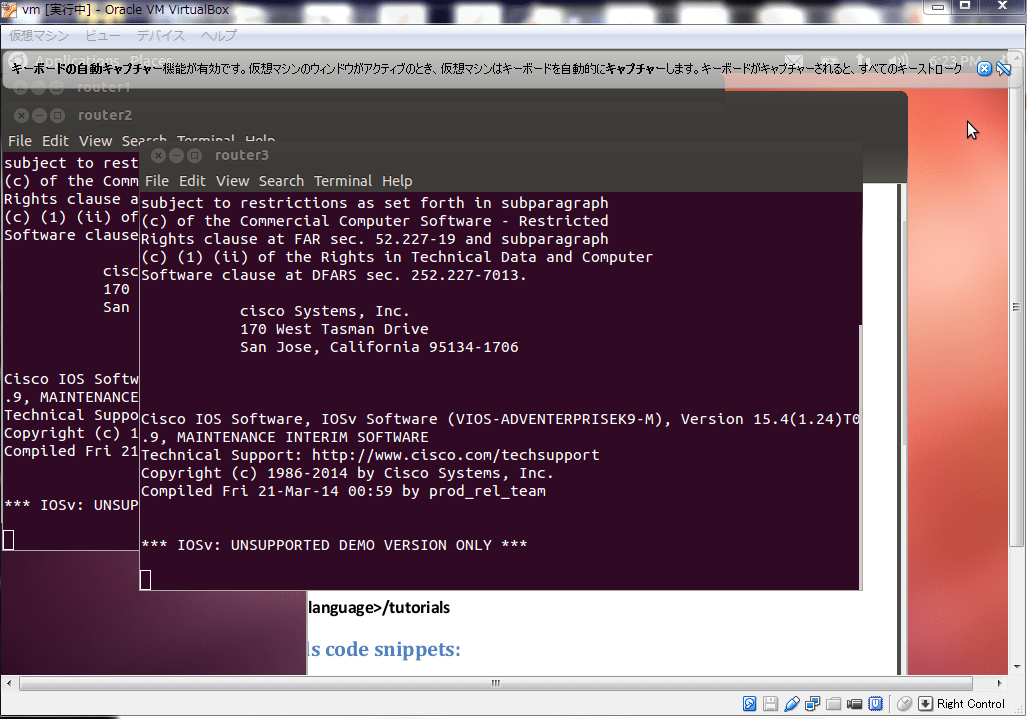
なんか、端末が出てきました。
ちょっと、(いや、かなり)まっていると・・・

なんかでてきて、さらにまつと・・・

%Error opening・・・とでてきたあと、反応ないので、Enterキーをくりっくしたら、
入力できるようになりました。
おお・・・
enable
show ip route
してみたら

なんか、つながっているようだが・・・よくわからん??
・・・わかんないので、今回はここまで・・・
CiscoのSDN OnePKが(ルーターとかなくても)VM使って確かめられる
前回はダウンロードしてきました。
今回は、
(1)VM作成
(2)VM起動
(3)サンプル(3-node)起動
を行います。
以下のサイトを参考にしています。
onePK を使ってアプリケーションを作る – All-in-one VMのご紹介
http://gblogs.cisco.com/jp/2014/04/developing-applications-with-onepk-all-in-one-vm/
■(1)VM作成
まずは、Virtual Boxを起動します。
そしたら、
ファイル→仮想アプライアンスのインポート
出てきたダイアログで
前回ダウンロードしたOVFファイルを選択し次へ
MACアドレス、再初期化しました・・・ま、インポート
こんなかんじでがんばります。
VMができました(2個目:赤丸)
■(2)VM起動
VM(赤丸のところ)をダブルクリックして起動します。
待っていると、いつものubuntu画面に
はじめのパスワードは「cisco123」ですので、それを入力
新しいパスワードを聞いてきます。適当に入れます。
もう一回、確認用に聞いてきます。同じパスワードを入れます。
I accept...をチェックして右側のボタンクリック
ネットワークシミュレーターのユーザー名とパスワードを聞いてきます。
めんどっちいので、アカウントと同じ、
ユーザー名cisco パスワードpassword
にしましたけど、好きにいれてください。
なんか、welcomeされてます・・・OK
■(3)サンプル(3-node)起動
なにしたらいいか、まったくわかりません・・・
QuickStartupGuide.pdfをあけてみます。
どうも、3-nodeというデモがあるみたい。
start3nodeというアイコン(緑のまる)をダブルクリック
がんばってます
つくったそうです。OK
なんか、端末が出てきました。
ちょっと、(いや、かなり)まっていると・・・
なんかでてきて、さらにまつと・・・
%Error opening・・・とでてきたあと、反応ないので、Enterキーをくりっくしたら、
入力できるようになりました。
おお・・・
enable
show ip route
してみたら
なんか、つながっているようだが・・・よくわからん??
・・・わかんないので、今回はここまで・・・











