








ビッグデータ=統計の専門家まかせという考え方で、大丈夫か?
http://blog.goo.ne.jp/xmldtp/e/c38a65222b83fa67b55539d71b6e769c
で書いたことがわかりにくい気がするので、ツンデレを使って、具体的に説明してみる。
■ケース
こういうケースを考えましょう。
トモダチ関係を分析するため、
スカイプの音声を全部録音して、
それをテキストに自動変換し、
そのテキストを使って、
テキストマイニングで
トモダチ関係を判断するとします。
Aさんは、B君に、ひどいことを100回いいました。
でも、やさしいことを3回いいました。
Aさんは、C君にやさしいことを5回いいました。
Aさんは、B君とC君、どちらがすきでしょう。
答え C君
とは、いいきれないよね。
■ビッグデータと統計の関係
スカイプの音声のテキストマイニングなんて、まさに非構造データなわけで、
これの解析というと、ビッグデータになりそうだ・・・
さて、このとき、統計的に単純に平均とかを出せば、
C君のほうに、優しい言葉をかけている回数が多いから、
すきなのはC君となる。
しかし、これは不自然だ。
ひどいことを100回も言ってB君と付き合っているとしたら、
B君がいじめられっこか、Aさんがツンデレと考えたほうが自然だ。
しかし、そんなことは、統計からは出てこない。
統計から出てくるのは、あくまで、
Aさんは、B君に、ひどいことを100回いいました。
でも、やさしいことを3回いいました。
Aさんは、C君にやさしいことを5回いいました。
しか出てこない。
これをみて、ツンデレと判断するのは、あくまでも人間の判断になる
人間の判断だから、正しいかどうかは判らない。
■潜在変数、因子の発見
つまり、統計では、表面的なことは出てくるが、もう一歩、奥に入った
ところ、つまり潜在意識、統計用語だと因子(因子分析)や潜在変数(共分散構造分析)
が知りたいとなると、人間の判断が入ってくる。
たとえば、因子分析だと、Aさんが、B君C君D君、E君に対して、もっといろんなデータを
あつめてきて、それを表(行列)にして、それに対して、因子分析をかけるわけだけど、
その前に因子の数を大体決める。そして、分析すると、因子負荷量は出してくれる。
出してくれるけど、その値が、どういう意味かは、自分で考えないといけない。
コンピューターは、考えてくれない。
そうすると、自分で考える・・・といっても、今の場合だと、Aさんのような女子高生
(あれ、設定、女子高生だったっけ?女子高生とする)に詳しいおじさんじゃないと、
よくわかんないわけだ。
で、共分散構造分析(SEM)をする場合、その構造がわかんなければならない。
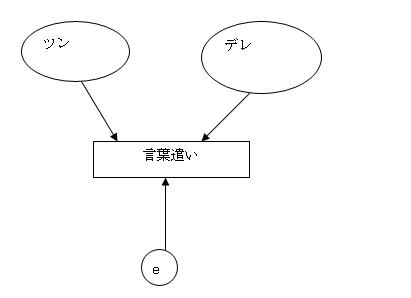
ツンデレの場合、2つの構造が、すぐに思いつく。
1つは、ツンの要素とデレの要素、それぞれが、行動に関係しているというもの
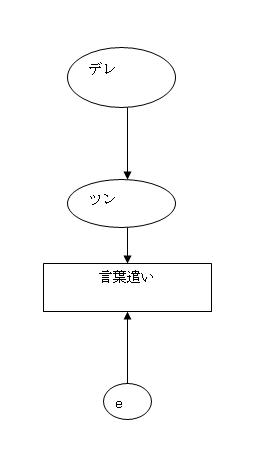
もうひとつは、やっぱり、デレ(愛)の要素が根本にあり、それがツンフィルターによって、
ゆがませられた上に、気まぐれ要素eの誤差項の影響を受けたのが、行動という考え方。
これのどっちがいいかは、共分散構造分析をすれば出てくるかもしれない。
だけど、この2つの構造でいいのか?っていう問題がある。
ツンデレは、もっと複雑かもしれない。
こういうことは、やはり、「ツンデレ評論家」の女子高生好きオジサンでないと、わからないのだ。
■ビッグデータはむしろ、業界専門家が必要
ということで、ビッグデータは、女子高生好きオジサンがやるのがいい・・・というわけではなく、
データからモノを判断する場合、潜在意識までさかのぼってしまうと、それらしいことを言える、
業界の専門家が必要になる。
逆に、統計の専門家が、本当に必要かというと。。。システムが出来てしまえば、あとは使うだけ
なので、使い方がわかればいいってことになる。
上記の共分散構造分析の場合は、SPSS Amosが判ればいいって言うことになるし・・
というわけで、統計の専門家だけで大丈夫か?
ツンデレ解析できるか?
統計専門の数学科の人がツンデレ解析すると、おかしな方向に行かないか?
ってことになる。

















