









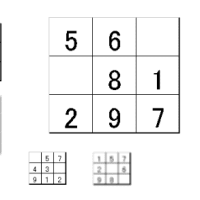
写真が八枚ならんでいますが、真ん中(■の上の部分)に視線を向けて見ると両脇の二つの顔はハッキリ見え、表情もわかります。
ところが残りの顔は見えているという感じがするのに、どんな表情なのかまではわかりません。
男性の顔なのか女性の顔なのか、髪の毛が金髪であるかどうかなど大雑把なことはわかりますが、どんな表情なのかまではわかりません。
一番左の顔と一番右の顔は同じ人物の顔なのですが、左のほうは右のほうの顔の左側の半分を反転して右側に写して作った左右対称の顔です。
■の部分に視線を向けたまま見たのでは、二つの顔は目に入るのですが、一番左の顔が左右対称で、一番右の写真とは似ているが異なるということまではわかりません。
周辺視野はよく見えているように感じても、細かい点が実際にどうなっているかは見えていないのです。
このことは写真の下の文字列を見てみるとよくわかります。
すぐ下の漢字列では真ん中を中心にして5文字ぐらいまでは読み取れますが、
それから外側の文字になると、見えてはいても読み取ることが難しくなります。
どの漢字も少し複雑なので、外側の文字はボンヤリとしか見えないと読み取ることが困難になるからです。
同じ文字でも次の行のアルファベットとか、ひらがな、カタカタになると、視線を動かさなくても注意さえ向ければ一番遠い左端の文字でも、右端の文字でも何とか読み取れることができます。
文字の形が漢字で字画の多い複雑なものよりも、比較的に簡単なためボンヤリとしか見えなくても文字を見分けることができるのです。
それだけでなく、カナやアルファベットは数が少ないので強く記憶されていてボンヤリとしか見えなくてもそれと見分けやすいからです。
ハッキリとそれと見分けることができなくても、大雑把な部分的な理解から全体を「これ」と推定して読み取るのです。
詳しく見極めなくいまま、いわば短絡的に理科してしまうのです。
五行目の文字列は固、細かい部分が見分けられるように明朝体で書かれています。
それでも比較的易しい漢字なので周辺視野にあっても、字画が少ないため周辺視野にあっても読み取れるものがあります。
ところが実はいくつかの文字は左右を反転させた鏡文字にしてあります。
それらは字画が少ないので大雑把にしか見えなくても、それと見分けてしまういわば短絡的なやりかたで読み取っているのです。
六行目はひらがなばかりが並んで、その上も字が似通っているため、周辺視野では見分けにくくなっているのですが、七行目のように漢字が間に入り、青と言う文字列の知識があるため見分けやすくなっています。
はっきり「あお」と見分けているのではないのですが、規制の知識があるので短絡的に当てはめて見ているのです。
このように短絡的に判断して読み取る能力があるから、速読ができたり、あるいは目の負担を軽くしてよむことができるので、短絡も有益な能力でもあるのです。



※コメント投稿者のブログIDはブログ作成者のみに通知されます