








12月になりました。ご無沙汰しております。
1chipMSXでは日本語入力の利便性の向上のためプログラミングをはじめました。
ミナカンで公開したのですが変換速度が遅いために鑑賞プログラムで終わりました。
2023年は実用に向けて日本語入力システムの以前に作ったものをゼロベースでやっています。
これによりMSX2+より前のMSX2で漢字コードの文書を表示することができます。

MSX2パソコンで動作する設計でSCREEN7、漢字ROMを使っています。
PUT SPRITEに次いでPUT KANJI命令ですが当時の本を見るとマジック的なイメージがあるような気がします。
当時はロール紙に印刷する電子計算機がメインでPCは知らない方が大半でオフィスオートメーションしている限られた会社だけでした。
Windows95以前は電卓持って帳簿に手書きで罫線とか定規で引いて数字を書いている会社が多かったです。
というわけで8ビットでもできる!オマケ機能なので処理能力を上げるために半角には変換できないようにします。
セットアップの処理の流れは入力した文字を大文字にするようにコードをキャラクタコード順に並べます。
MSX2+で小文字を大文字に変えます。濁点などは2文字を判別してト→ドに変えます。
ここで128コード以降のひらがな、カタカナは変換できないので
漢字BASICのコードを入力します。これでコンソールの準備はできました。
カーソルは16*16スプライトです。最前面にグラフィックが表示されます。
移動処理でカーソルを消すことなく作れます。処理速度も上がります。
間違えた操作は最初からやり直すなど不親切さはありますが、
プログラム量の軽減のためです。起動します。
第一段階としてあかさたな順に辞書ファイルの区分を大雑把に分けて様子を見ていきます。
最新版ではローマ字変換モードに変える手間がかかるので最新版では
プログラムにPOKE&HFCFC,69を加えて英数の状態からローマ字変換に変わります。
このローマ字変換はMSX2から使うことができます。
単漢字変換をやっています。
例えば2223、2224、2225…のように漢字コードを+1にしていくと、
音訓になっていないのでかなり変換に苦労します。
そこで漢和辞典の音訓索引からの独自の辞書を採用しています。
特長としては「呼ぶ」を「呼」というふうに「よ」候補になります。
漢字の読みを略した場合に対応できます。
また「呼」は「呼称」の「こ」候補にもあります。※
こんなふうに単漢字変換候補を出すことができます。
保存形式は10桁ごとに漢字を並べています。
1行10文字の漢字候補に変えてテンキーからの入力も対応します。
この辞書は400行程度の大きなデータです。
これを毎回、1行1行ロードすると数十秒かかってしまいます。
また高速で表示されるのでBASICのメモリを消費します。
使わなくなったデータの解放のため最適化で30秒程度止まる場合もあります。
調べてみないとわかりませんが問題を解消する場合はRUNコマンドで再起動がよいかもしれません。
頻繁に発生するようなら考えてみたいと思います。
※手作りのため常用漢字で候補にないものはアップデートする場合があります。
デバッグの流れですが例えば「つ」の場合を見てみます。
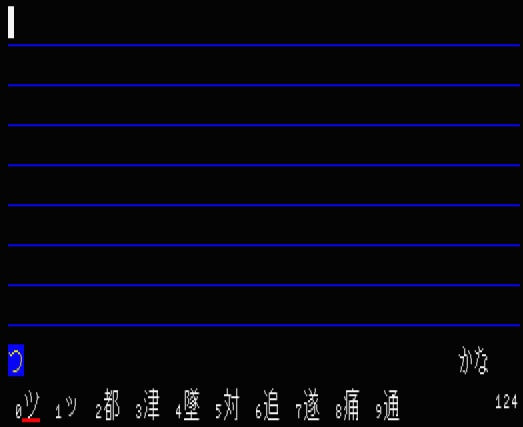
8ビットの技としてキャラクターコードごとに辞書を作ります。
ロードをカウントすることで行数を把握できます。
数値が高いほうが時間がかかるということです。
MSXturboR相当でも124はかなり時間がかかっています。
そこでファイル名で辞書を作って一発で変換できるようにします。
フロッピーディスクドライブはファイル数が少ないほど高速に動作しますが、
50音なら50個作ると意外と時間がかかります。
頻度の高い候補のみをファイルにすることで快適に動作します。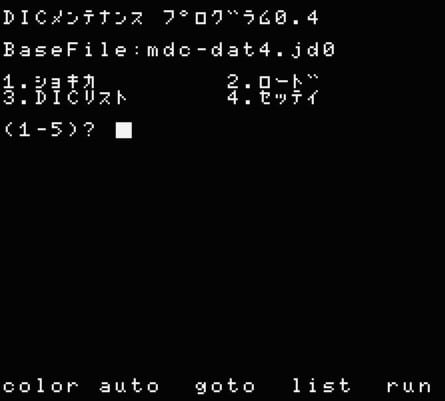
DICメンテナンスプログラムで辞書を作ります。
基本の辞書ファイルをカットして設定します。
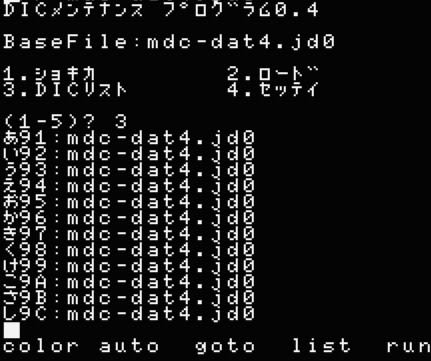
まず2を選択してロードします。
3は例えば「あ」の変換に対応する辞書のファイル名を表示しています。
4の設定は煩雑な処理になるので自動化して誰でも設定できるようにします。
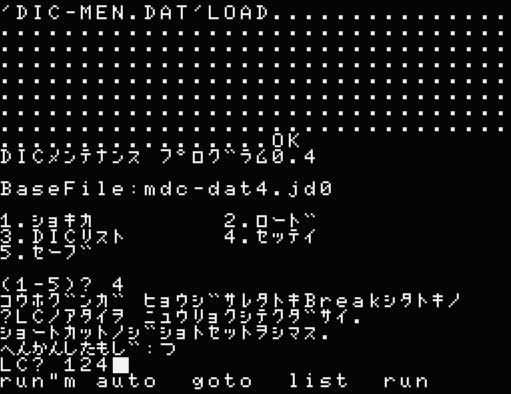
自動ファイルができました。5でセーブして変更完了です。
システムを起動すれば「つ」が一発で候補になります。
日本語入力を即席で作ったもので漢字対応にできるような設計です。

背景デザインはデバッグ中にはこの画面にします。
正式バージョンでは背景を変えます。
最初から候補が出る直前の行はカットして別名保存するプログラムができれば
ショートカットした辞書ができます。第一段階はこんなところです。

今後の展望としては辞書システムの改良がメインになる予定です。

MSXパソコンはロードが遅いのでファイルを種類ごとに分割して処理時間を軽減します。
第二段階は熟語の属性コードの設定が可能になります。単漢字変換から単語変換への流れです。
また入力中に変換候補が出るようなAI変換ができればと思います。
年号が令和に変わる時期に予定していましたが問題がクリアできず不採用に終わりました。
単漢字は1文字でしたが新しく属性コードを設定することで同音異義語を使うことができます。
「処理上の問題」「処理場の問題」などの変換対応です。
最終段階では既存辞書との互換性と利便性の向上です。
MSX2+以降ではユーザー辞書を登録できますがSRAMを使うので登録できる語句が少ないです。
当時は「建設省」でしたが「国土交通省」など時代とともに日本語も変わっていきます。
時代に対応できる辞書を作るために辞書管理もできる大きな辞書データが必要です。
駅名データ、市町村合併後の地名データなどもあります。
そこでテキストで今までの方法で簡易的な辞書から読み込めるようにしてみたいと思います。
余談ですが最近はデスクワークをやっているのですが1年程度やっていると億劫なところがなくなり、
打ち込んだり書いたりしてルーティン作業すると思考能力が上がる感じがします。
何か頭にイメージしたものや話したことなど筆記する習慣ができますね。
日本語変換で数十年も経ちますが;誤字脱字が社会的に多い気がします。
1行を変換なしで入力すれば一発で変換できる世の中になっていると思いますね。
なんか思わず変換キーを押してしまうんですね。
ちょっとWindows10でやってみると
>うめたてちがすくなくしょりじょうのもんだい
埋立地が少なく処理上の問題
>うめたてちがすくなくしょりじょうをどうするか
埋立地が少なく処理場をどうするか
という結果です。変換数を1回にすることで校正機能がはたらき精度の高い変換ができるようです。
広告とかメディアに印刷などするともう修正はききませんから;
間違えを少なくするには文書化して使う語句だけを抜き取れば校正できると思います。
>きかいがありこうかんかいにさんかすることにしました
機会があり交換会に参加することにしました
>きかいがありこうかんをいらいしました
機会があり交換を依頼しました。
正:代わりとなる機械があり交換を依頼しました。
>おだわらにいくきかいがありこしょうしたきかいのてんけんをしました
小田原に行く機会があり故障した機械の点検をしました
まだ日本語は難しいですね;でも面白いです。
MSXはファイル形式をバイナリデータで漢字コードを出力することを予定しています。
データフォーマットなどは自分で作ってください。後日書く予定です。
これをMSX2または1chipMSXに対応していきます。では。














※コメント投稿者のブログIDはブログ作成者のみに通知されます