今回は Propensity score(傾向スコア)の概要をご紹介します。例えば、
2つの Group ( TRUE群とFLSE群)があって、この2つのグループを説明する変数( X1, X2 )があったとします。医学においてTRUE群は対照群など、FALSE群は治療群などであり、X1 や X2 は年齢、性別、血圧など・・・・などが考えられます。すなわち、
Formular ( Group ~ X1 + X2 ) は Logistic 回帰分析によってTRUE群かFALSE群かのいずれかに属する確率(0.0~1.0)を得ることができ、この確率を Propensity score(PS)と言っています。これは X1 や X2 などGroupに影響を及ぼす因子を調整することになり、背景因子を除いた母集団検定などに用いられています。仮想例題ですが、
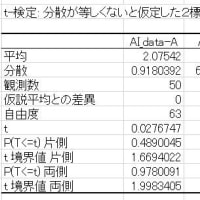
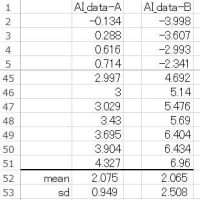
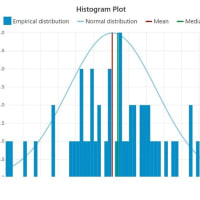
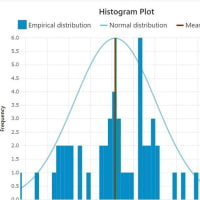
 左図は2群のある観測値で、その平均値±標準偏差はTRUE群(n=47)=10.66±4.90、False群(n=37)=13.69±3.96 だったときの t-test の結果は「 t-value=-3.566、df=82、p-value=0.0030 」で統計学的に有意と判断されます。ここで、
左図は2群のある観測値で、その平均値±標準偏差はTRUE群(n=47)=10.66±4.90、False群(n=37)=13.69±3.96 だったときの t-test の結果は「 t-value=-3.566、df=82、p-value=0.0030 」で統計学的に有意と判断されます。ここで、
因子 X1 を例えば年齢などと仮定して、Logistic 回帰分析を行ったTRU の様になり、これがPSの散布図です。
の様になり、これがPSの散布図です。
この散布図を通常5つ以上のクラスに分けて t-test を行えば因子X1(例えば年齢など・・など)の背景因子を調整した母集団検定となります。正確には、Pair maching とか Full maching などの方法が開発されており、R program の Library( optmatch )にある関数( pscore.dist )を用いるのが簡便かと思います。下図のR program による Full maching 結果は次の通りでした。
----------------------------------------------------------
Welch Two Sample t-test
data: tmean and cmean
t = 2.0899, df = 51.91, p-value = 0.04155
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.1032125 5.0856764
sample estimates:
mean of x mean of y
3.3111111 0.7166667
----------------------------------------------------------