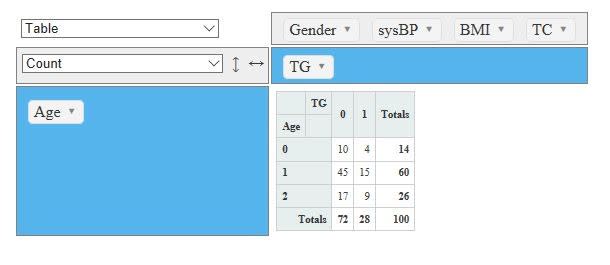
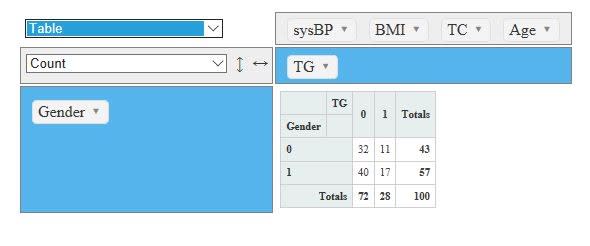
杉本典夫 先生から大変参考になるコメントを頂きましたのでご紹介させて頂きます。
コメント要旨:
2×2分割表には色々な手法を適用できるため、統計学解説書等ではそれらの手法が体系的に整理されていない傾向があると思います。例えば2×2分割表の場合は次のようになります。
2種類の2分類化された計量尺度項目の相関性を検討したい時。
今回の話題であるピポットテーブルのように、
2種類の計量尺度項目を境界値で2分類にした時、2つの項目の間にどの程度の相関性があるかを検討したい場合です。
2種類の計量尺度項目を境界値で2分類にした時、2つの項目の間にどの程度の相関性があるかを検討したい場合です。
・研究デザイン:横断的研究
・評価指標:四分点相関係数=φ(ファイ)係数
・検定手法:四分点相関係数の検定=Mantel-Haenszelの検定
・推定手法:Fisherのz変換を利用した相関係数の区間推定
・評価指標:四分点相関係数=φ(ファイ)係数
・検定手法:四分点相関係数の検定=Mantel-Haenszelの検定
・推定手法:Fisherのz変換を利用した相関係数の区間推定
χ2乗検定は本来は連関係数の検定ですが、これに連続修正(Yatesの修正)を施すと、出現率の正規近似検定と同じものになります。そのため検定対象の評価指標の種類によって、連続修正を施すか施さないかを使い分けると良いと思います。
SASやSPSSやJMPやRでは、通常は出現率の区間推定に連続修正を施しません。
しかし
連続修正は超幾何分布を正規分布でより正確に近似するためのものですから、区間推定でも施す必要があります。
連続修正は超幾何分布を正規分布でより正確に近似するためのものですから、区間推定でも施す必要があります。
出現率が低い時は、2つの項目の関係が直線ではなく指数関係に近くなります。
そのため出現率の差の代わりに、リスク比とその検定と推定を用いる時があります。
そのため出現率の差の代わりに、リスク比とその検定と推定を用いる時があります。
リスク比を対数変換すると、対数変換した出現率の差つまり対数リスク差になります。
そのためリスク比の検定と推定は、対数変換した出現率の差を正規近似して検定と推定を行っていることに相当します。
そのためリスク比の検定と推定は、対数変換した出現率の差を正規近似して検定と推定を行っていることに相当します。